PII-Datenleck in OpenAI-Logs
Nutzer-Prompts enthalten oft Namen, E-Mails und Gesundheitsdaten. Wir implementieren PII-Erkennung, Schwärzung und ZDR-Endpunktkonfiguration, bevor ein Prompt die Systemgrenze verlässt.
EU-KI-Verordnung DSGVO Art. 22 Evaluierungsgesteuert Anbieterneutral
Wir entwickeln DSGVO-konforme OpenAI-Integrationen für DACH-Unternehmen: GPT-4.1 und Function Calling über Azure OpenAI mit EU-Rechenzentrum und DSGVO Art. 28-konformem Auftragsverarbeitungsvertrag — kein Training auf Ihren Unternehmensdaten, Data Residency in der EU. Jedes Engagement wird mit EU-KI-Verordnungs-Risikoklassifizierung, ZDR-Konfiguration und Fallback zu selbst gehosteten Modellen ausgeliefert.

Wir liefern DSGVO-konforme OpenAI-Entwicklung für vier Käuferprofile im DACH-Raum: Produktteams, die GPT-gestützte Features ergänzen — Dokumentenanalyse, Klassifizierung, RAG über Unternehmensdaten; regulierte Branchen (Finanzdienstleistungen, Gesundheitswesen, Versicherung), die EU-KI-Verordnungs-Konformität und DSGVO Art. 28-Auftragsverarbeitung benötigen; Enterprise-Kunden, die interne Wissensassistenten über SAP- oder SharePoint-Korpora aufbauen; und Plattformen, die manuelle Prüfprozesse durch DSGVO-konforme LLM-Automatisierung ersetzen. Der bevorzugte Weg: Microsoft Azure OpenAI Service mit EU-Rechenzentrum — keine Datenweitergabe an US-Server, kein Training auf Ihren Daten, vollständige Datenhaltung in der EU.
Herausforderungen
Nutzer-Prompts enthalten oft Namen, E-Mails und Gesundheitsdaten. Wir implementieren PII-Erkennung, Schwärzung und ZDR-Endpunktkonfiguration, bevor ein Prompt die Systemgrenze verlässt.
Token-Ausgaben steigen ohne Feature-Budgets und Anomalie-Alarme unvorhersehbar. Wir instrumentieren jeden Modell-Aufruf mit Token-Zahl-Metriken und alarmieren vor Überschreitung der Monatsbudgets.
GPT-4-Modelle halluzinieren bei unterspezifiziertem Retrieval oder mehrdeutigen Anweisungen. Wir erden Antworten mit RAG, verwenden strukturierte Ausgaben zur Formateinschränkung und gaten auf RAGAS-Treue-Scores.
Benutzerkontrollierte Eingaben in System-Prompts eingebettet erzeugen Injection-Vektoren. Wir wenden strukturierte Schemata, explizite Trennzeichen, Ausgabe-Validierung und adversarielle Testsuiten in der CI an.
Prompt-Änderungen werden ohne Qualitätsprüfungen ausgeliefert und verschlechtern die Ausgaben lautlos. Wir bauen RAGAS-basierte Evaluierungs-Harnesses und verlangen bestandene Evaluierungen als CI-Merge-Gate.
Regulatoren erwarten dokumentierte Risikoklassifizierung, bevor KI-Features live gehen. Wir führen den Klassifizierungs-Workshop am ersten Tag durch und erstellen eine technische Akte, keine Tabellenkalkulation.
Lösungen
Retrieval-Augmented-Generation über interne Dokumente, SAP-Exportdaten und Wissensdatenbanken — mit pgvector oder Qdrant, Quellennachweis und RAGAS-Qualitätsmessung.
Deployment über Microsoft Azure OpenAI Service mit EU-Rechenzentrum: DSGVO-konformer Auftragsverarbeitungsvertrag (AVV) gemäß Art. 28, keine US-Datenweitergabe, Data Residency Deutschland/Irland.
GPT-Agenten, die interne APIs, ERP-Systeme und Tools aufrufen — mit typisierten Schemata, Retry-Logik und Human-in-the-Loop-Genehmigungsgates für geschäftskritische Aktionen.
Vertragsanalyse, Rechnungs-Parsing und Formular-Extraktion mit JSON-Modus und Pydantic-Schema-Validierung — Ersatz für manuelle Prüfprozesse in Buchhaltung und Recht.
Hybride BM25+Embedding-Suche mit GPT-gesteuertem Reranking — verbessert die Relevanz für E-Commerce-Kataloge, interne Wissensdatenbanken und technische Dokumentation.
Anbieterneutrale Routing-Schicht zu OpenAI, Anthropic oder Llama 3 On-Premise — Anbieterwechsel ohne Neuschreiben der Anwendungslogik, BSI-KI-Leitfaden-konform.
Stack
OpenAI GPT-4.1, GPT-4o, Whisper, Structured Outputs, Assistants API, Embeddings, LangChain, LlamaIndex, pgvector, Qdrant, LangSmith, Ragas, FastAPI, Python.
Compliance
DSGVO-konform · EU-KI-Verordnung berücksichtigt · SOC-2-fähig · HIPAA-fähig · CCPA-berücksichtigt
Gemeinsam: OWASP LLM Top 10, Prompt-Injection-Härtung, SBOM für Modell-Abhängigkeiten.
Fallstudien
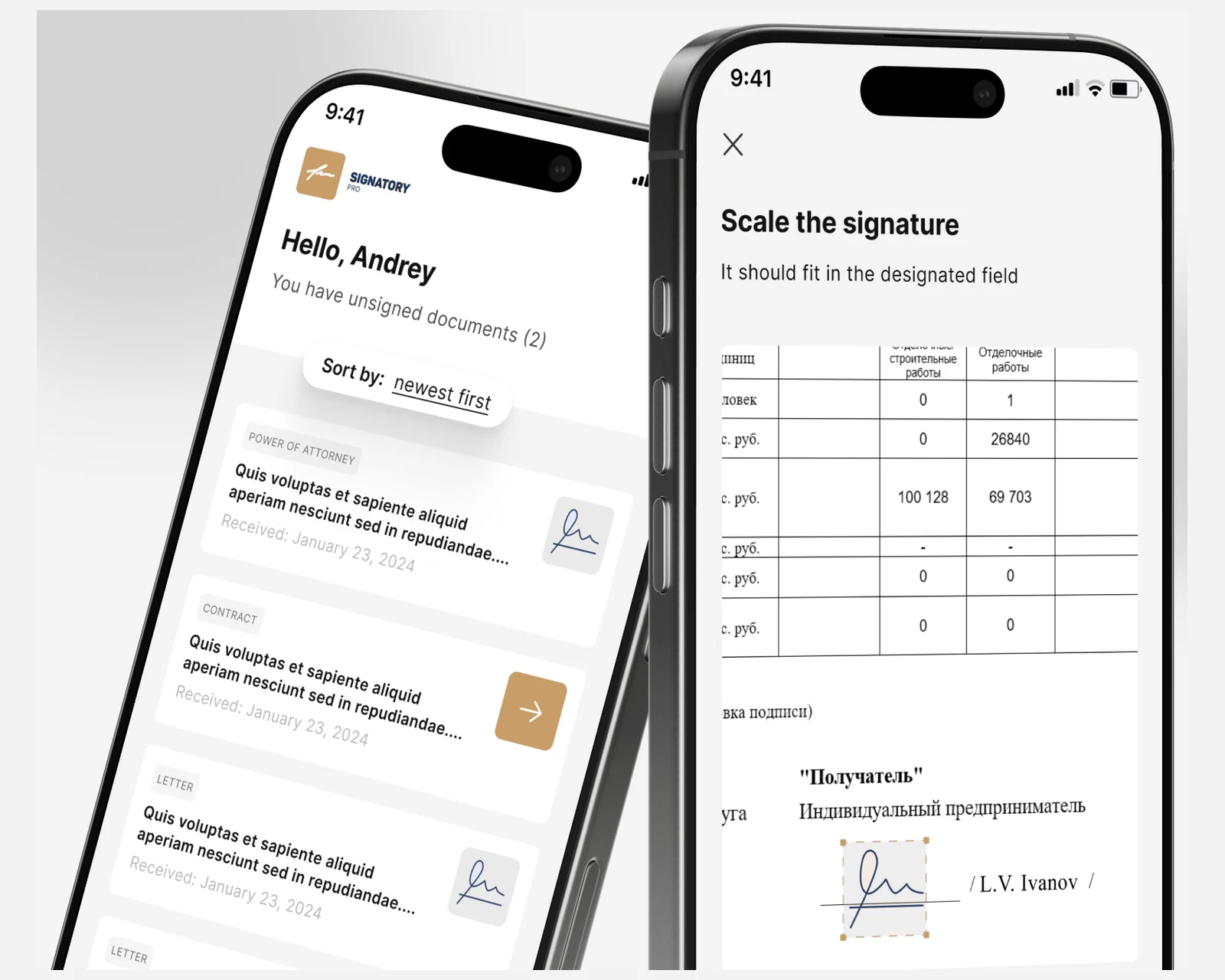
Native iOS- und Android-E-Signatur-Clients mit einem Symfony + React CRM für eine grenzüberschreitende Anwaltskanzlei — KYC-Onboarding und eine rechtssichere Beweiskette für US- & EU-Verfahren.

Produktive Social-Plattform — App Store + Google Play, live in den USA und der EU — mit Geo-Radar, verschlüsseltem Messaging und einer virtuellen Wirtschaft.
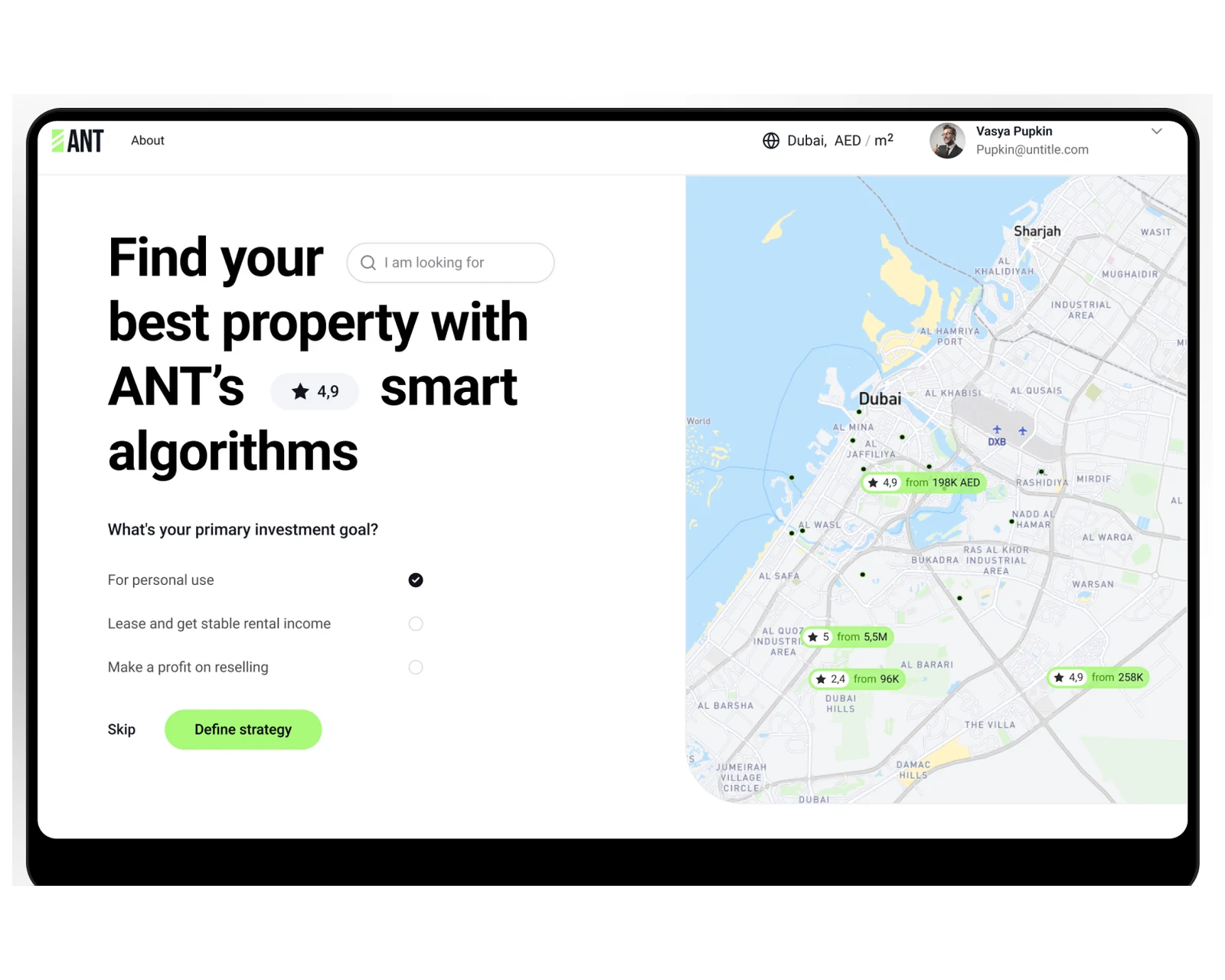
Immobilien-Marktplatz-Webplattform mit Listing-CMS, Suche und B2B-Admin-Konsole für US- und EU-Betreiber.
Warum YuSMP
Wir integrieren OpenAI, Anthropic, Mistral und selbst gehostete Modelle über einen einheitlichen Router — sodass Sie Anbieter wechseln können, ohne Anwendungslogik neu zu schreiben.
Kein Prompt wird ohne Regressions-Evaluierung ausgeliefert. RAGAS-Metriken, Golden-Set-Vergleiche und geschäftsspezifische Benchmarks laufen bei jedem Merge in der CI.
Jedes KI-Engagement beginnt mit Risikoklassifizierung und AVV-Gestaltung gemäß DSGVO Art. 28. Hochrisikosysteme erhalten Konformitätsbewertungspläne; Azure OpenAI EU ist unser Standard für DACH-Kunden mit strengen Datenschutzanforderungen.
FAQ
Wir konfigurieren Zero-Data-Retention-API-Endpunkte (ZDR), wo verfügbar, implementieren PII-Erkennung und -Schwärzung mit Microsoft Presidio oder benutzerdefinierten NER-Modellen, bevor Prompts unseren Perimeter verlassen, und leiten EU-personenbezogene Daten ausschließlich über Azure OpenAI mit EU-Region-Endpunkten und einer No-Logging-Konfiguration.
ZDR-Endpunkte weisen OpenAI an, keine API-Anfragedaten über die unmittelbare Antwort hinaus zu speichern. Verfügbar für ausgewählte Modelle per API-Vereinbarung. Wir dokumentieren die ZDR-Konfiguration in Ihrem Auftragsverarbeitungsvertrag und nehmen sie in die technische Akte gemäß EU-KI-Verordnung auf.
Ja. Microsoft Azure OpenAI Service bietet einen DSGVO-konformen Auftragsverarbeitungsvertrag (AVV) gemäß Art. 28, EU-Rechenzentren in Deutschland und Irland (Data Residency), kein Training auf Kundendaten sowie eine No-Logging-Konfiguration. Wir empfehlen Azure OpenAI für Unternehmen mit strengen Datenschutzanforderungen im DACH-Raum — besonders in regulierten Branchen wie Finanzdienstleistungen und Gesundheitswesen.
Wir implementieren semantisches Caching (GPTCache oder benutzerdefiniertes Redis-basiertes), um identische Prompts nicht erneut abzufragen, wählen Modell-Tiers je Aufgabe (gpt-4o-mini für Routing, gpt-4o für Analyse), setzen max_tokens-Budgets, überwachen Token-Ausgaben je Feature in Echtzeit und alarmieren bei Anomalien.
Wir bauen einen Evaluierungs-Harness, bevor wir den ersten Prompt schreiben: Golden-Set-Q&As, RAGAS-Metriken für die Retrieval-Qualität und geschäftsspezifische Metriken je Feature. Jede Prompt-Template-Änderung führt die Evaluierungssuite in der CI durch. Kein Prompt wird ohne Regressions-Gate ausgeliefert.
Wir führen einen strukturierten Workshop durch, der Zweckbestimmung, Nutzergruppe, Entscheidungsautonomie und Sektor abdeckt, um die korrekte Risikoklasse zuzuweisen. Hochrisikosysteme (Lebenslauf-Bewertung, medizinische Entscheidungsunterstützung) erhalten einen Konformitätsbewertungsplan; Systeme mit begrenztem Risiko erhalten Transparenzmitteilungsvorlagen. Die Klassifizierung wird in einer technischen Akte dokumentiert.
RAG für dynamische Korpora, bei denen die Quellenattribution wichtig ist — Rechtsdokumente, Produktkataloge, Support-Wissensdatenbanken. Fine-Tuning für stabilen Ton, Format oder Fachvokabular, das RAG allein nicht zuverlässig erzeugen kann. Wir empfehlen RAG zuerst und evaluieren Fine-Tuning nur, wenn RAG ein Plateau erreicht.
Strukturierte Ausgabe-Schemata (JSON-Modus + Pydantic), klare System-/Nutzer-Inhalt-Trennung mit expliziten Trennzeichen, Ausgabe-Schema-Validierung, adversarielle Injection-Testsuiten in der CI und Überwachung auf anomale Ausgabemuster in der Produktion.
Ja. Wir implementieren einen Modell-Router, der je nach Aufgabentyp, Kostenbudget und Latenz-SLA an OpenAI, Anthropic Claude, Mistral oder ein selbst gehostetes Modell weiterleitet. Die Anwendungsschicht ruft den Router auf, nicht ein spezifisches Modell — sodass ein Anbieterwechsel keine Änderungen am Anwendungscode erfordert.
Antwort innerhalb eines Werktages. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.