GIL und Async-Verwirrung
Das Mischen von Threading, Multiprocessing und asyncio ohne klares Konzept erzeugt Deadlocks und Durchsatzminderung. Wir entwerfen Nebenläufigkeitsstrategien explizit und dokumentieren sie.
FastAPI LangChain EU AI Act GDPR
Python ist unser Standard für KI-, ML- und Data-Engagements — FastAPI für latenzarme Inferenz-Gateways, LangChain und LlamaIndex für RAG über private Korpora, PyTorch für Fine-Tuning, Pydantic für Contract-First-APIs. Jedes KI-Engagement wird am ersten Tag mit einem EU-KI-Verordnungs-Risikoklassifizierungsdokument ausgeliefert.

Wir liefern Python Engineering für vier Käuferprofile: KI- und LLM-Produktteams, die RAG-Pipelines, Agenten und Inferenzdienste bauen; Data-Engineering-Teams, die ETL von operativen Datenbanken zu Analytics-Warehouses orchestrieren; SaaS-Teams, die FastAPI für hochdurchsatzfähige APIs oder Django für admin-lastige Portale wählen; sowie regulierte Branchen — HealthTech, FinTech, LegalTech — wo EU-KI-Verordnungs-Compliance, DSGVO-Datenverarbeitung und erklärbare Modellentscheidungen Lieferanforderungen sind.
Herausforderungen
Das Mischen von Threading, Multiprocessing und asyncio ohne klares Konzept erzeugt Deadlocks und Durchsatzminderung. Wir entwerfen Nebenläufigkeitsstrategien explizit und dokumentieren sie.
Konflikte in transitiven Abhängigkeiten brechen Deployments lautlos. Wir verwenden Poetry für deterministisches Locking, mehrstufige Docker-Builds und einen privaten PyPI-Spiegel.
Nutzer-Prompts enthalten oft Namen, E-Mails und Gesundheitsdaten. Wir implementieren presidio-basierte Schwärzung und Zero-Data-Retention-Endpunktkonfiguration, bevor ein Prompt die Systemgrenze verlässt.
Cold-Start- und Token-Generierungslatenz steigen bei gleichzeitigen Anfragen. Wir batchen, streamen mit SSE, implementieren semantisches Caching und deployen asynchrone FastAPI-Worker.
Prompt-Änderungen werden ohne Regressionsprüfungen ausgeliefert und verschlechtern die Ausgaben lautlos. Wir bauen RAGAS-basierte Evaluierungs-Harnesses, bevor der erste Prompt in Produktion geht.
pgvector, Qdrant, Pinecone, Weaviate — Teams zögern, weil die Landschaft fragmentiert ist. Wir wählen basierend auf Ihrer bestehenden Infrastruktur, Konsistenzanforderungen und Abfragemustern.
Lösungen
Retrieval-Augmented-Generation-Pipelines über interne Dokumente, Wissensdatenbanken und Datenbanken — mit Quellennachweis und Halluzinationskontrolle.
FastAPI-Dienste, die OpenAI, Anthropic oder selbst gehostete Modelle kapseln — mit Streaming, Caching, Rate Limiting und Multi-Provider-Fallback.
Asynchrone Pipelines mit Celery oder Dagster, die Daten von operativen Quellen zu Snowflake, BigQuery oder PostgreSQL-Analyse-Schemata bewegen.
Full-Stack-Django-Anwendungen mit angepasstem Admin, Celery-Hintergrundaufgaben und PostgreSQL — für CMS, Betreiber-Workstations und interne Tools.
Scikit-learn- und PyTorch-Modelltraining, -Validierung, MLflow-Experiment-Tracking und FastAPI-Serving mit A/B-Routing.
gRPC- und REST-Brücken, die Python-KI-Dienste mit Node.js- oder .NET-Produkt-Backends verbinden — mit generierten Clients und Contract-Tests.
Stack
Python 3.12, FastAPI, Pydantic v2, SQLAlchemy 2, Celery, LangChain, LlamaIndex, PyTorch, MLflow, Ragas, Poetry, Docker, Kubernetes.
Compliance
DSGVO-konform · EU-KI-Verordnung berücksichtigt · SOC-2-fähig · HIPAA-fähig · CCPA-berücksichtigt
Gemeinsam: OWASP LLM Top 10, Prompt-Injection-Härtung, SBOM pro Build.
Fallstudien

Production social platform — App Store + Google Play, live across the US and EU — with geo Radar, encrypted messaging and a virtual economy.
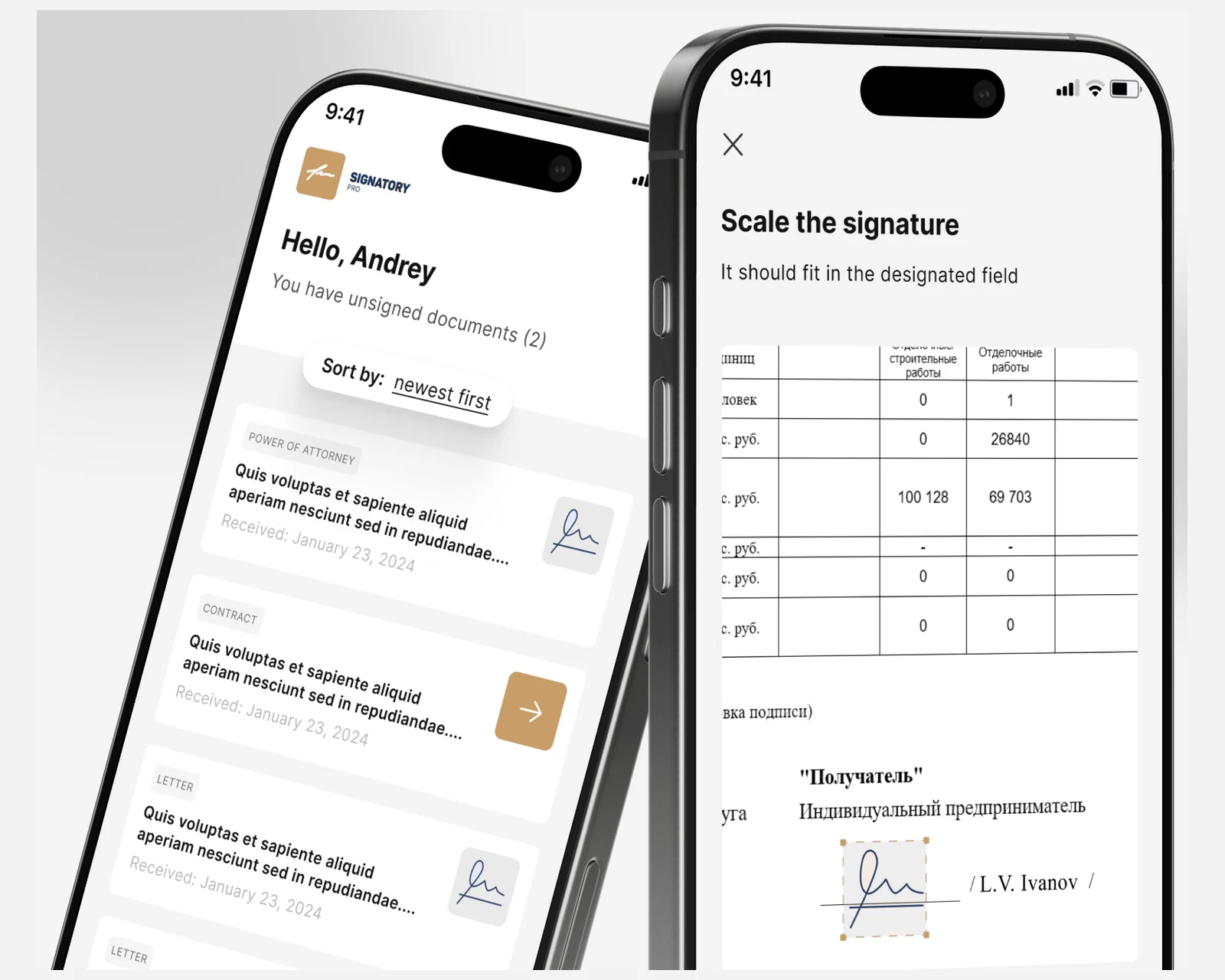
Native iOS- und Android-E-Signatur-Clients mit einem Symfony+React-CRM für eine grenzüberschreitende Anwaltskanzlei — KYC-Onboarding und ein belastbarer Beweispfad für US- und EU-Fälle.
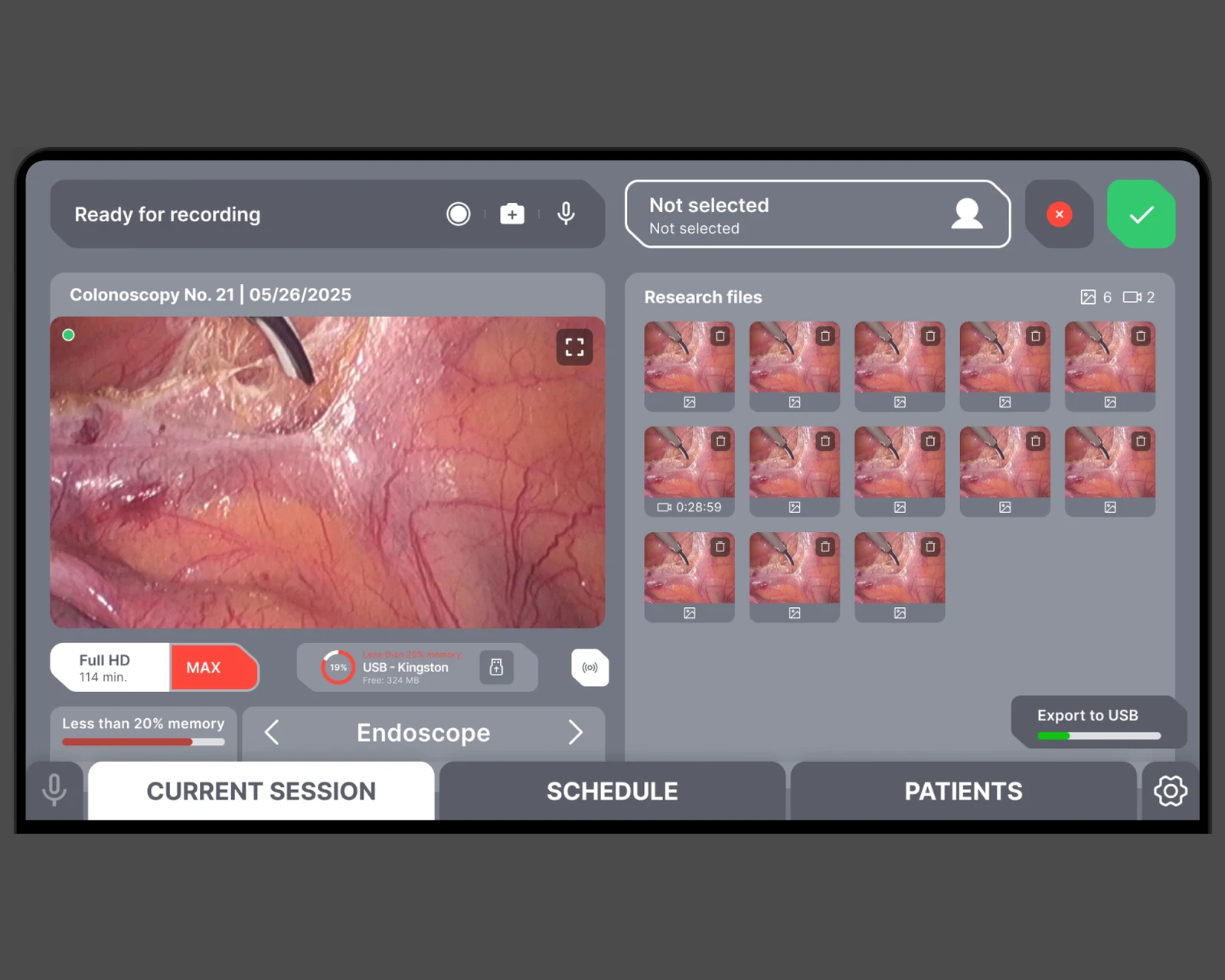
Tablet-first endoscopy recording, patient records, and DICOM/HL7 export — built on Laravel + React with browser-tier WebRTC capture for US & EU clinics.
Warum YuSMP
Wir integrieren OpenAI, Anthropic, Mistral und selbst gehostete Modelle über einen einheitlichen Router — sodass Sie Anbieter wechseln können, ohne Anwendungslogik neu zu schreiben.
Kein Prompt wird ohne Regressions-Evaluierung ausgeliefert. RAGAS-Metriken, Golden-Set-Vergleiche und geschäftsspezifische Benchmarks laufen bei jedem Merge in der CI.
Jedes KI-Engagement beginnt mit einem Risikoklassifizierungs-Workshop. Hochrisikosysteme erhalten Konformitätsbewertungspläne; Systeme mit begrenztem Risiko erhalten Transparenzmitteilungsvorlagen.
FAQ
Wir führen einen strukturierten Workshop durch, der beabsichtigten Zweck, Nutzerpopulation, Entscheidungsautonomie und Branche abdeckt, um die korrekte Risikostufe (unzulässig, hoch, begrenzt oder minimal) zuzuweisen. Hochrisikosysteme erhalten einen vollständigen Konformitätsbewertungsplan; Systeme mit begrenztem Risiko erhalten die Transparenzmitteilungen. Wir dokumentieren die Klassifizierung in Ihrer technischen Akte.
FastAPI für APIs und Inferenz-Gateways, wo Latenz und asynchroner Durchsatz wichtig sind. Django für admin-lastige Anwendungen, CMS-Funktionen und Teams, die Batteries-Included-Konventionen bevorzugen. Wir kombinieren sie oft: Django für Auth und Admin, FastAPI für performance-kritische Endpunkte.
Wir implementieren PII-Erkennung und -Schwärzung (presidio oder benutzerdefiniertes NER), bevor Prompts die Systemgrenze verlassen, nutzen Zero-Data-Retention-API-Endpunkte wo verfügbar (OpenAI ZDR, Azure OpenAI mit No-Logging-Konfiguration) und halten EU-personenbezogene Daten innerhalb von EU-Region-Endpunkten.
RAG ist richtig für dynamische, häufig aktualisierte Korpora, wo Quellennachweis wichtig ist — Rechtsdokumente, Produktkataloge, Support-Wissensdatenbanken. Fine-Tuning ist richtig für konsistenten Ton, Format oder Fachvokabular, das RAG allein nicht zuverlässig produzieren kann. Wir empfehlen zuerst RAG und evaluieren Fine-Tuning erst, wenn RAG an seine Grenzen stößt.
Wir bauen einen Evaluierungs-Harness, bevor wir den ersten Prompt schreiben: Golden-Set-QAs, RAGAS-Metriken für RAG (Treue, Relevanz, Kontext-Recall) und benutzerdefinierte Geschäftsmetriken. Jede Modell- oder Prompt-Änderung durchläuft die Evaluierung vor dem Merge.
pgvector auf PostgreSQL für Teams, die bereits Postgres betreiben — keine neue Infrastruktur, transaktionale Konsistenz, SQL-Joins. Qdrant für eigenständige Deployments, die gefilterte Vektorsuche im großen Maßstab benötigen. Wir haben Produktionserfahrung mit beiden.
Poetry für Abhängigkeits-Locking, mehrstufige Docker-Builds für schlanke Images und einen privaten PyPI-Spiegel für Air-Gapped-Umgebungen. Wir pinnen direkte und transitive Abhängigkeiten und führen pip-audit in der CI durch.
Wir wenden strukturierte Ausgabe-Schemata (JSON-Modus / Pydantic) an, trennen System- und Nutzerinhalt mit klaren Trennzeichen, validieren Modellausgaben gegen erwartete Schemata und führen adversarielle Injection-Testsuiten in der CI durch. Keine einzelne Technik ist vollständig — Defense in Depth.
Antwort innerhalb eines Werktages. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.