GIL and async confusion
Mixing threading, multiprocessing and asyncio without a clear mental model produces deadlocks and degraded throughput. We design concurrency strategies explicitly and document them.
FastAPI LangChain EU AI Act GDPR
Python is our default for AI, ML and data engagements — FastAPI for low-latency inference gateways, LangChain and LlamaIndex for RAG over private corpora, PyTorch for fine-tuning, Pydantic for contract-first APIs. Every AI engagement ships with an EU AI Act risk classification document on day one.

We deliver Python engineering for four buyer profiles: AI and LLM product teams building RAG pipelines, agents and inference services; data engineering teams orchestrating ETL from operational databases to analytics warehouses; SaaS teams choosing FastAPI for high-throughput APIs or Django for admin-heavy portals; and regulated industries — healthtech, fintech, legaltech — where EU AI Act compliance, GDPR data handling and explainable model decisions are delivery requirements.
Challenges
Mixing threading, multiprocessing and asyncio without a clear mental model produces deadlocks and degraded throughput. We design concurrency strategies explicitly and document them.
Conflicting transitive dependencies break deployments silently. We use Poetry for deterministic locking, multi-stage Docker builds and a private PyPI mirror.
User prompts often contain names, emails and health data. We implement presidio-based redaction and zero-data-retention endpoint configuration before any prompt leaves the perimeter.
Cold-start and token generation latency spike under concurrent requests. We batch, stream with SSE, implement semantic caching and deploy async FastAPI workers.
Prompt changes ship without regression checks and silently degrade outputs. We build RAGAS-based eval harnesses before the first prompt goes to production.
pgvector, Qdrant, Pinecone, Weaviate — teams delay because the landscape is fragmented. We select based on your existing infrastructure, consistency requirements and query patterns.
Solutions
Retrieval-augmented generation pipelines over internal documents, knowledge bases and databases — with source attribution and hallucination controls.
FastAPI services wrapping OpenAI, Anthropic or self-hosted models — with streaming, caching, rate limiting and multi-provider fallback.
Async pipelines with Celery or Dagster moving data from operational sources to Snowflake, BigQuery or PostgreSQL analytics schemas.
Full-stack Django applications with custom admin, Celery background tasks and PostgreSQL — for CMS, operator workstations and internal tooling.
Scikit-learn and PyTorch model training, validation, MLflow experiment tracking and FastAPI serving with A/B routing.
gRPC and REST bridges connecting Python AI services to Node.js or .NET product backends — with generated clients and contract tests.
Stack
Python 3.12, FastAPI, Pydantic v2, SQLAlchemy 2, Celery, LangChain, LlamaIndex, PyTorch, MLflow, Ragas, Poetry, Docker, Kubernetes.
Compliance
GDPR-aligned · EU AI Act-aware · SOC 2-capable · HIPAA-capable · CCPA-acknowledged
Shared: OWASP LLM Top 10, prompt-injection hardening, SBOM per build.
Cases

Production social platform — App Store + Google Play, live across the US and EU — with geo Radar, encrypted messaging and a virtual economy.
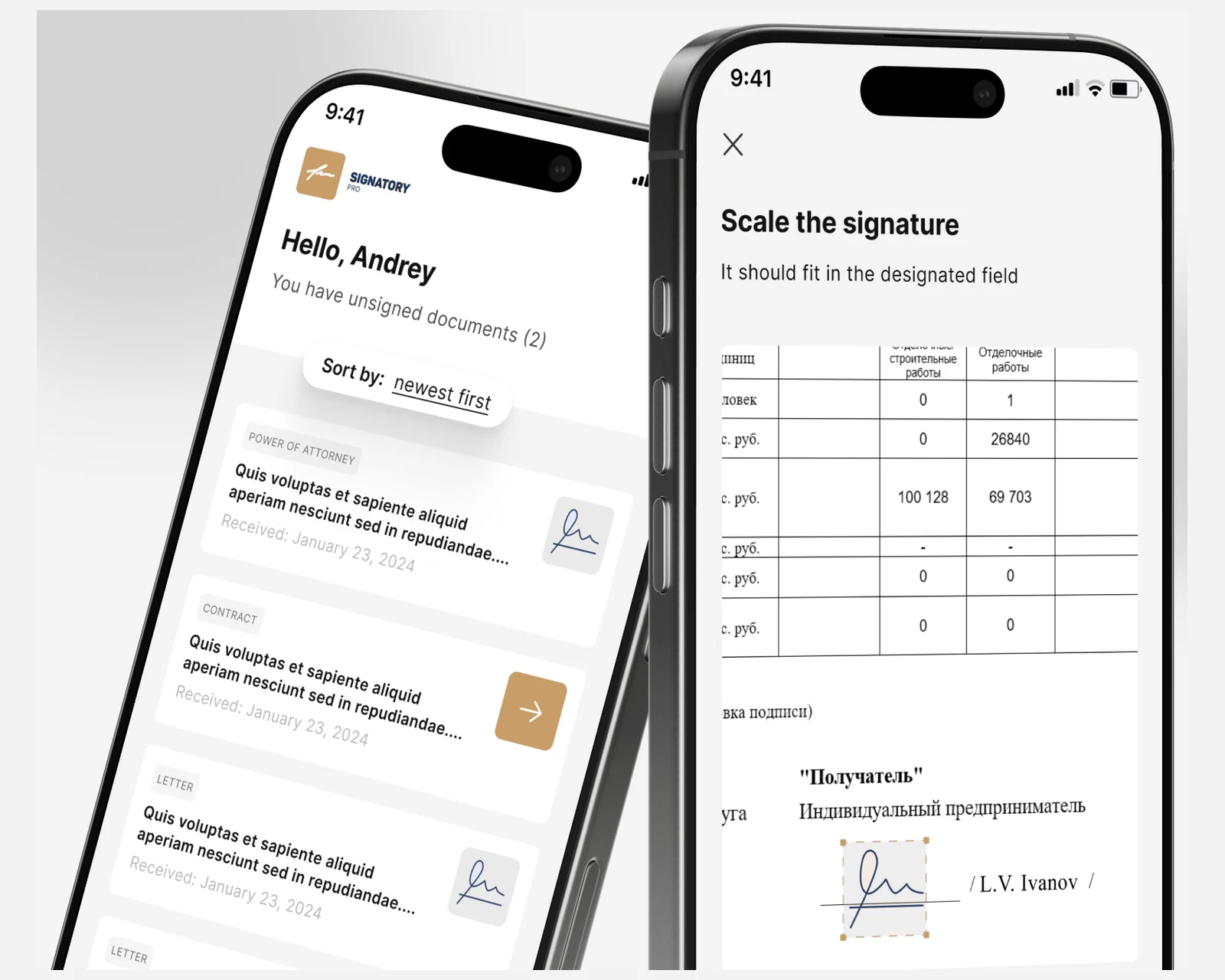
Native iOS and Android e-signature clients with a Symfony + React CRM for a cross-border law firm — KYC onboarding and a defensible evidence trail for US & EU matters.
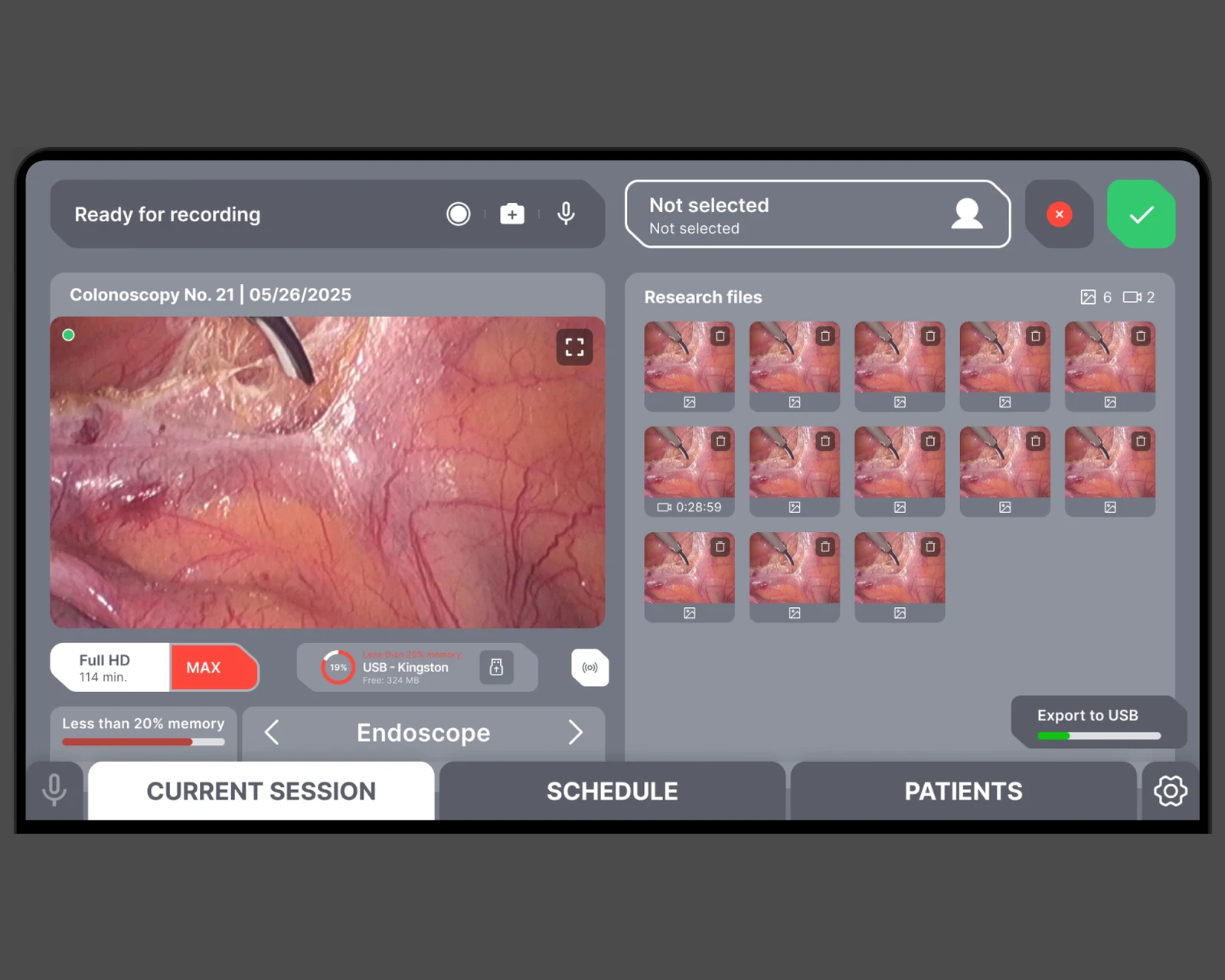
Tablet-first endoscopy recording, patient records, and DICOM/HL7 export — built on Laravel + React with browser-tier WebRTC capture for US & EU clinics.
Why YuSMP
We integrate OpenAI, Anthropic, Mistral and self-hosted models through a unified router — so you can switch providers without rewriting application logic.
No prompt ships without a regression eval. RAGAS metrics, golden-set comparisons and business-specific benchmarks run in CI on every merge.
Every AI engagement starts with a risk classification workshop. High-risk systems get conformity assessment plans; limited-risk systems get transparency disclosure templates.
FAQ
We run a structured workshop covering intended purpose, user population, autonomy of decision-making and sector to assign the correct risk tier (unacceptable, high, limited or minimal). High-risk systems get a full conformity assessment plan; limited-risk systems get the transparency disclosures. We document the classification in your technical file.
FastAPI for APIs and inference gateways where latency and async throughput matter. Django for admin-heavy applications, CMS features and teams that prefer batteries-included conventions. We often combine them: Django for auth and admin, FastAPI for performance-critical endpoints.
We implement PII detection and redaction (presidio or custom NER) before prompts leave the perimeter, use zero-data-retention API endpoints where available (OpenAI ZDR, Azure OpenAI with no-logging config), and keep EU personal data within EU-region endpoints.
RAG is right for dynamic, frequently updated corpora where source attribution matters — legal documents, product catalogs, support knowledge bases. Fine-tuning is right for consistent tone, format or domain vocabulary that RAG alone cannot reliably produce. We recommend RAG first and evaluate fine-tuning only when RAG plateaus.
We build an eval harness before writing the first prompt: golden-set Q&As, RAGAS metrics for RAG (faithfulness, relevance, context recall) and custom business metrics. Every model or prompt change runs the eval before merge.
pgvector on PostgreSQL for teams already running Postgres — zero new infrastructure, transactional consistency, SQL joins. Qdrant for standalone deployments needing filtered vector search at scale. We have production experience with both.
Poetry for dependency locking, multi-stage Docker builds to keep images lean, and a private PyPI mirror for air-gapped environments. We pin direct and transitive dependencies and run pip-audit in CI.
We apply structured output schemas (JSON mode / Pydantic), separate system and user content with clear delimiters, validate model outputs against expected schemas, and run adversarial injection test sets in CI. No single technique is complete — defence in depth.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.