Stakeholder-Interviews
Gründer- und Floristen-Interviews, Analytik zum bestehenden Betrieb, Customer-Journey-Mapping für Geschenkkäufer in den USA und der EU, Abgrenzung der Substitutionsrichtlinie.
Fallstudie · Retail · Floristik
Wie wir eine vollständige Discovery für FlowDelivery durchgeführt haben — ein gepaartes Kunden-und-Floristen-Mobilprodukt, das Analytik, UX und Systemarchitektur abdeckt, mit einem bestandsbewussten Katalog, dynamischen Produktkarten, einem dreistufigen Kunden-Checkout und einem einheitlichen Datenmodell, das den Erwartungen von US- und EU-Zielgruppen unter DSGVO und CCPA vom ersten Tag an standhält.

Die Gründer von FlowDelivery kamen mit einem koordinierten Paar von Mobilprodukten zur Gestaltung zu uns: einer kundenseitigen App zum Bestellen von Sträußen mit Lieferung und einer internen Floristen-App zur Verwaltung des Sortiments und zur Verfolgung der Komponenten-Verfügbarkeit. Die beiden Apps mussten ein Datenmodell teilen, damit die Katalog-Sichtbarkeit den Echtzeit-Bestand ohne manuellen Eingriff widerspiegelt, und das Kundenerlebnis musste die Strauß-Kaufentscheidung — historisch ein angstbehafteter Kauf — auf einen dreistufigen Checkout verdichten. Das Käuferprofil erstreckt sich für die Floristik-Lieferung über die Vereinigten Staaten und die Europäische Union: Geschenkkäufer, die mit weniger als zwei Minuten Aufmerksamkeit, einem starken visuellen Geschmacksfilter und einer realen Erwartung ankommen, dass das, was sie auf der Produktkarte sehen, auch an der Tür des Empfängers ankommt. Code-First-MVP-Ansätze schieden früh aus, weil sich die Bestandsregeln, die Substitutionsrichtlinie und der Multi-Store-Katalog-Abgleich nicht allein aus Bildschirmen ableiten lassen — ein erster Build baut das Datenmodell in den ersten sechs Monaten typischerweise zwei- oder dreimal neu. Marktplatz-Standardvorlagen schieden aus, weil ihr Strauß-als-Produkt-Modell einen flachen SKU-Katalog voraussetzt und die Rezept-aus-Komponenten-Struktur, die die Floristik tatsächlich erfordert, nicht abbilden kann. Das Ergebnis ist ein Figma-getriebenes Discovery-Paket — Customer-Journey-Map, typisiertes Datenmodell, OpenAPI-Spezifikation, klickbarer Prototyp, Design-Tokens, Substitutionsrichtlinien-Tabelle und ein Discovery-zu-Build-Übergabedokument. Das Paket ist das Artefakt, das ein Build-Team nutzen kann, um einen Festpreis-Build abzugrenzen, und das der Gründer nutzen kann, um Anbieterangebote auf gleicher Augenhöhe zu bewerten.
Ein Überblick darüber, was die FlowDelivery-Discovery über die Kunden-App, die Floristen-App und das gemeinsame Datenmodell in ihrem ersten Zyklus geliefert hat.

Die Methodikentscheidung dominiert jede andere Architekturentscheidung bei einem gepaarten Kunden-und-Betreiber-Produkt. Wir wählten einen Figma-getriebenen Discovery-Prozess, der ein typisiertes Datenmodell, eine OpenAPI-Spezifikation und einen klickbaren Prototyp erzeugt, bevor irgendein Produktionscode geschrieben wurde, weil die Abwägungen sauber dazu passen, wie ein gepaartes Kunden-und-Floristen-Produkt tatsächlich scheitert, wenn man es überstürzt. Ein Code-First-MVP baut das Datenmodell in den ersten sechs Monaten typischerweise zwei- oder dreimal neu, weil sich die Bestandsregeln und die Substitutionsrichtlinie nicht allein aus Bildschirmen ableiten lassen — und jeder Neuaufbau kostet mehr, als die Discovery-Phase gekostet hätte. Marktplatz-Standardvorlagen schieden aus, weil ihr Strauß-als-Produkt-Modell einen flachen SKU-Katalog voraussetzt und die Rezept-aus-Komponenten-Struktur, die die Floristik erfordert, nicht abbilden kann.
Der dritte Kandidat, ein reiner UX-Wireframe-Durchlauf ohne Architektur, ist ein legitimer Kostensparer — doch bei einem gepaarten Kunden-und-Betreiber-Produkt ist das Datenmodell das Produkt, und ein Wireframe-Durchlauf, der das typisierte Datenmodell und den API-Vertrag nicht adressiert, überlässt es dem Build-Team, beide zu erfinden. Das Discovery-Paket — Customer-Journey-Map, typisiertes Datenmodell, OpenAPI-Spezifikation, Postman-Sammlung, Komponentenbibliothek mit Design-Tokens, klickbarer Prototyp und Architecture Decision Record — ist durchgängig offen und zitierbar, ohne Anbieter- oder Template-Kette, die das Build-Team an eine einzige Methodik bindet.
| Dimension | Discovery-getrieben (FlowDelivery) | Code-First-MVP | Standardvorlage |
|---|---|---|---|
| Nacharbeitsrate | Niedrig — Datenmodell und API werden im Design validiert | Hoch — zwei oder drei Datenmodell-Neuaufbauten typisch | Versteckt — Template-Einschränkungen erzwingen die Form |
| Spezifikationsqualität | OpenAPI + Postman + Journey-Map | Aus dem Code abgeleitet, während er ausgeliefert wird | Vom Anbieter dokumentiert; variiert |
| Architektur-Klarheit | ADRs für jede bedeutende Abwägung | Implizit; teamabhängig | Anbieter-definiert; undurchsichtig |
| Zeit bis zum investierbaren Artefakt | 6–10 Wochen — auf einem Prototyp finanzierbar | 3–6 Monate — abhängig vom Build-Tempo | 2–4 Wochen — aber undifferenziert |
| Änderungskosten | Niedrig — Spezifikation ändern, nicht Code | Hoch — Code-Refactor bei jeder Iteration | Begrenzt durch die Template-Flexibilität |
| Anbieter-Portabilität | Hoch — Spezifikation ist build-team-agnostisch | Niedrig — Code ist an das Build-Team gekoppelt | Null — an den Anbieter gebunden |
| Compliance-Eignung (USA & EU) | Eingeplant — Einwilligung im Nutzer-Flow | Nachträglich aufgesetzt | Anbieter-kontrolliert; variiert |
Methodik-Referenzen: OpenAPI Initiative, Figma-Dokumentation, Postman-Learning-Center.
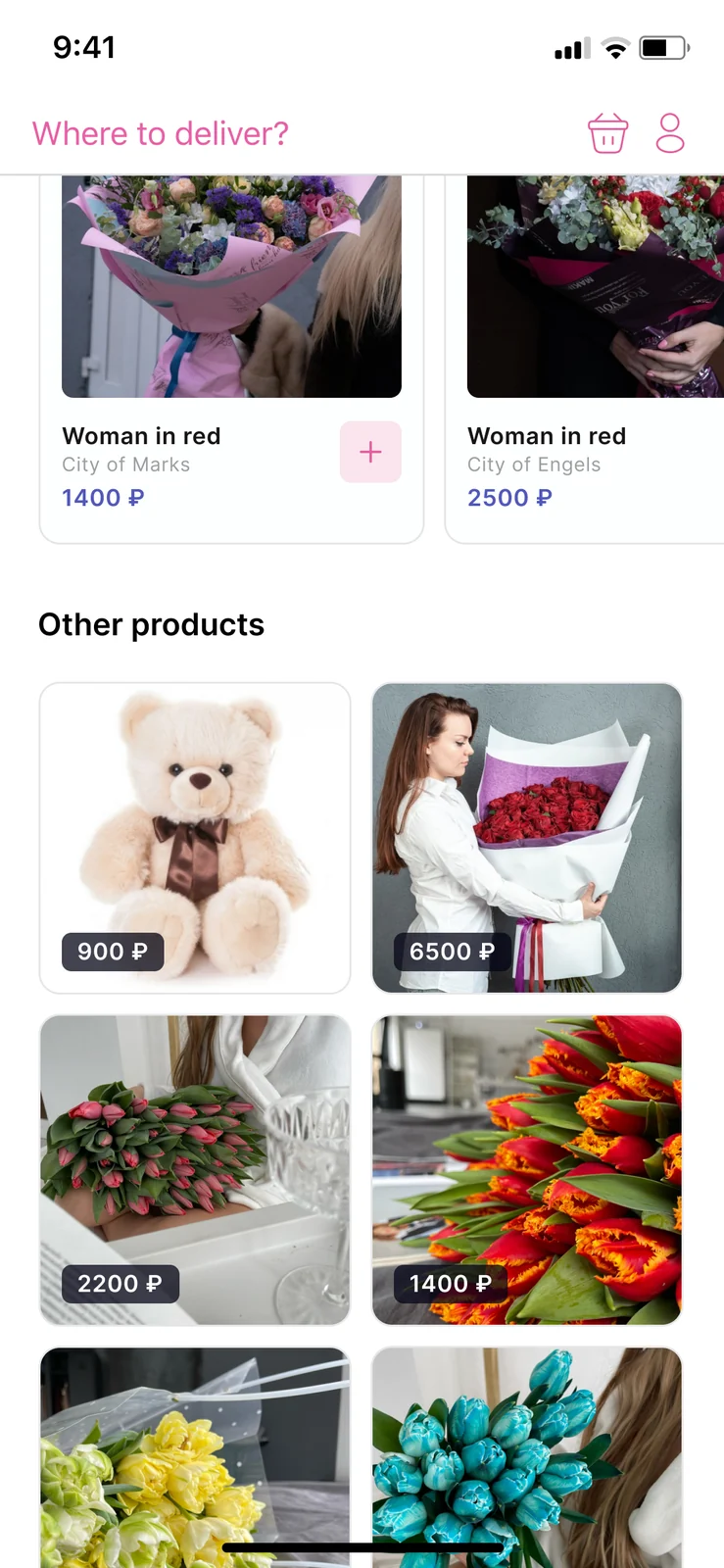
Die Kunden-App ist um einen Smart-Katalog herum gestaltet, der Sträuße ausblendet, deren Komponentenblumen nicht verfügbar sind, statt einen Käufer sich in ein Gesteck verlieben zu lassen, das er heute nicht haben kann. Dynamische Produktkarten berechnen den Preis aus den aktuellen Wareneinstandskosten neu, statt einen denormalisierten Cache zu lesen, sodass ein Preis, den der Käufer auf der Karte sieht, der Preis ist, den er beim Checkout zahlt. Die Karten-Hierarchie stellt das Visuelle an erste Stelle (ein übergroßes Foto mit konsistentem Zuschnitt), den empfängerfertigen Preis an zweite und die Lieferfenster-Option an dritte — die Reihenfolge der Entscheidungen, die ein Geschenkkäufer im Aufmerksamkeitsfenster von unter zwei Minuten tatsächlich trifft.
Der Checkout hat drei Schritte — Warenkorb, Lieferauswahl, Zahlung — und jeder Schritt ist umkehrbar, ohne den vorherigen Kontext zu verlieren. Der erste Schritt zeigt den Warenkorb mit Substitutions-Badges, falls ein Rezept an der Grenze der Verfügbarkeit ist; der zweite Schritt wählt die Adresse des Empfängers, das Lieferfenster und einen optionalen Schalter für kontaktlose Übergabe; der dritte Schritt ist die Zahlung mit gespeicherter Karte und Ein-Tipp-Wiederkauf-Unterstützung. Der gesamte Flow ist Mobile-First, die Design-Tokens sind in einer Figma-Bibliothek dokumentiert, und der Prototyp ist klickbar genug für Nutzertests, ohne Code zu schreiben. Die Kunden-App ist die Oberfläche, die unsere Praxis für Mobile App-Entwicklung in die Build-Phase trägt.
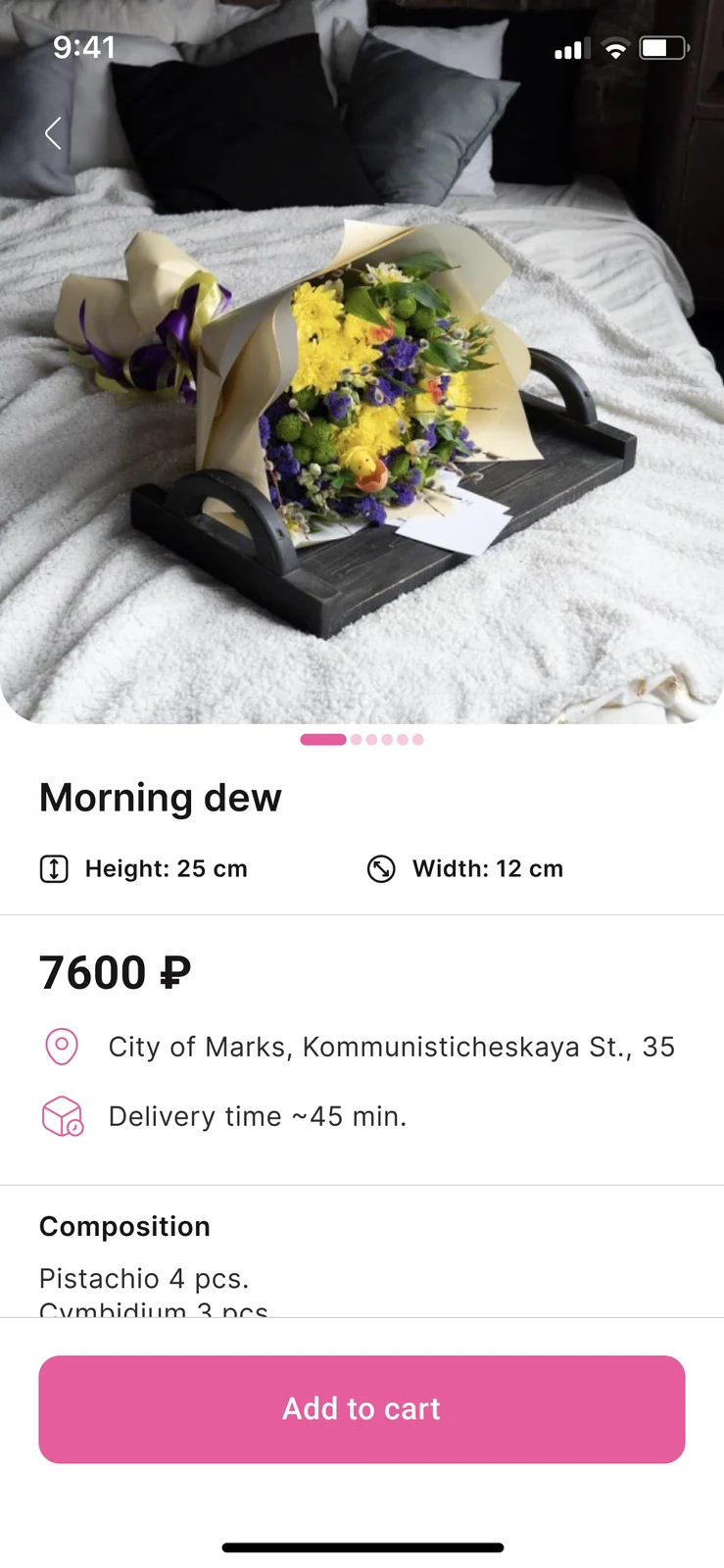
Die Floristen-App ist das operative Herzstück des Produkts und der Teil, der, falsch gemacht, die Kunden-App innerhalb eines Monats versenkt. Der Florist sieht dasselbe Datenmodell, das der Kunde sieht, von der gegenüberliegenden Seite: eine Liste von Strauß-Rezepten, die Komponenten, die jedes Rezept erfordert, den Live-Bestand über Stiele und Zubehör hinweg und eine Substitutionsrichtlinie pro Rezept, die es dem Floristen erlaubt, genehmigte Austausche zu definieren, die die visuelle Identität bewahren. Wenn eine Komponente knapp wird, berechnet der Katalog die Verfügbarkeit automatisch neu; Rezepte, die mit Substitutionen herstellbar sind, zeigen auf der Kundenseite ein dezentes Badge, während Rezepte, die gar nicht herstellbar sind, ausgeblendet werden, bis der Bestand wieder aufgefüllt ist.
Strauß- und Preisbearbeitung leben in der Floristen-App unter einem typisierten Formular, das validierte Aktualisierungen an das gemeinsame Backend sendet. Eine Änderung der Komponentenzahl eines Rezepts, eines Preises oder einer Substitutionsregel propagiert innerhalb von Sekunden in den Kundenkatalog — ohne manuelle Synchronisierung. Wo die ursprüngliche Spezifikation des Gründers ein teures Feature vorsah, schlugen wir eine schlankere Alternative vor, die die volle Funktionalität beibehielt und dabei Budget und Zeitplan verkleinerte: Die Live-Verfügbarkeits-Neuberechnung ist das kanonische Beispiel und ersetzt ein geplantes Dashboard pro Store durch eine einzige sich automatisch neu berechnende Liste. Die gesamte Architektur wird als Teil unserer Praxis für individuelle Softwareentwicklung geliefert.
Die Datenschutz-Ausrichtung von FlowDelivery war eine Design-Entscheidung, bevor sie ein Banner war. Die Spezifikation minimiert personenbezogene Daten von Grund auf: Die Kunden-App speichert nur das, was für Checkout, Lieferung und Wiederkauf notwendig ist, und die Floristen-App speichert nichts über den Käufer außer einem Empfängernamen und einer Adresse, beschränkt auf eine einzige Lieferung. Das Datenmodell kodiert Aufbewahrungsfristen pro Entität, sodass das Build-Team explizite Vorgaben hat, wie lange ein Datensatz einer ausgelieferten Bestellung aufzubewahren und was zu löschen ist.
Consent-Design ist Teil des Discovery-Pakets, keine Nachrüstung nach dem Launch. Der Kunden-Flow rendert eine granulare Einwilligung im DSGVO-Stil für Nutzer in der Europäischen Union und eine Offenlegung im CCPA-Stil („Do Not Sell or Share My Personal Information") für Nutzer in Kalifornien im selben Checkout-Schritt. Die Architektur ist darauf ausgelegt, mit den Pflichten der DSGVO für Nutzer in der Europäischen Union und den Pflichten von CCPA / CPRA für Nutzer in Kalifornien und den übrigen Vereinigten Staaten übereinzustimmen — und die Datenschutzarbeit der Build-Phase zu einer Dokumentationsaufgabe statt einer architektonischen Nachrüstung zu machen.
Compliance-Ausrichtung: DSGVO-konform · ISO-27001-bereit · SOC 2 Type II in Vorbereitung · HIPAA-fähig · CCPA-berücksichtigt.
Eine fünfphasige Discovery, die FlowDelivery von einem einzeiligen Gründer-Pitch zu einer finanzierungsfähigen, build-bereiten Spezifikation für die gepaarte Kunden-und-Floristen-App brachte.
Gründer- und Floristen-Interviews, Analytik zum bestehenden Betrieb, Customer-Journey-Mapping für Geschenkkäufer in den USA und der EU, Abgrenzung der Substitutionsrichtlinie.
Typisiertes Datenmodell für Sträuße, Rezepte, Komponenten, Bestand, Bestellungen und Substitutionen; OpenAPI-Spezifikation; Postman-Sammlung, die jeden Endpunkt durchläuft.
Kunden-App-Prototyp mit dreistufigem Checkout, Floristen-App-Prototyp mit Rezept- und Bestandsverwaltung, Figma-Komponentenbibliothek, Design-Tokens.
Substitutionsrichtlinie pro Rezept, Verfügbarkeits-Neuberechnungslogik, audit-fähige Datenschutz-Ausrichtung, region-bewusstes Consent-Design für den US- und EU-Launch.
Architecture Decision Records, Build-Team-Übergabepaket, Anbieter-Bewertungsrahmen für den Gründer und ein Festpreis-Abgrenzungsdokument für den Build.
Das Discovery-Paket von FlowDelivery wurde bewusst als Mehrzweck-Artefakt konzipiert. Die erste Zielgruppe ist das Build-Team — intern oder extern —, das das typisierte Datenmodell, die OpenAPI-Spezifikation, die Postman-Sammlung und den klickbaren Prototyp nutzen kann, um einen Festpreis-Build mit Zuversicht und ohne Scope-Creep-Aufschlag abzugrenzen. Die zweite Zielgruppe ist der Gründer, der dasselbe Paket nutzen kann, um Anbieterangebote auf gleicher Augenhöhe zu bewerten — jeder Anbieter sieht dieselbe Spezifikation, gibt ein Angebot gegen denselben Scope ab, und der Gründer ist nicht länger in der unbeneidenswerten Lage, Äpfel mit Birnen über anbietergefärbte Dokumente hinweg zu vergleichen. Die dritte Zielgruppe sind Investoren: Ein klickbarer Prototyp, der ein glaubwürdiges Produkt ohne die Kosten oder das Risiko eines Code-First-Builds demonstriert, ist ein finanzierungsfähiges Artefakt, besonders für einen nicht-technischen Gründer, der zu einer Seed-Runde geht. Wir dokumentierten jede bedeutende Architektur-Abwägung als ADR — Granularität der Substitutionsrichtlinie, Takt der Bestands-Neuberechnung, Auswahl des Zahlungsanbieters, Granularität des Lieferfensters — sodass der Gründer eine belastbare Antwort hat, wenn ein Investor oder ein Anbieter fragt „warum so und nicht anders". Wo die ursprüngliche Spezifikation des Gründers ein teures Feature vorsah, schlugen wir eine schlankere Alternative vor, die die volle Funktionalität beibehielt und dabei Budget und Zeitplan verkleinerte; diese Substitutionen sind als Scope-Abwägungen dokumentiert, die der Gründer erneut aufgreifen kann, wenn das Produkt reift.
Die Discovery von FlowDelivery war auf einen Launch mit einer einzigen Codebasis für US- und EU-Zielgruppen ausgelegt. Das Kunden-App-Design bedient Geschenkkäufer in Kalifornien, New York, Texas, Florida und Washington in den USA sowie Geschenkkäufer in den Niederlanden, Deutschland, Frankreich, Irland und Schweden in der EU, ohne regionsspezifische Forks der Codebasis. Consent-Flows sind auf der Design-Ebene region-bewusst: Kunden aus der EU und dem EWR erhalten einen granularen Einwilligungsbildschirm im DSGVO-Stil mit separaten Schaltern für optionale Produktanalytik; Kunden aus Kalifornien erhalten im selben Checkout-Schritt eine Offenlegung im CCPA-Stil („Do Not Sell or Share My Personal Information"). Die Datenverarbeitungspraktiken sind an der DSGVO für europäische Nutzer und am Flickenteppich der US-Bundesstaaten-Datenschutzgesetze ausgerichtet — CCPA / CPRA (Kalifornien), VCDPA (Virginia), CPA (Colorado), CTDPA (Connecticut), UCPA (Utah), TDPSA (Texas) und Oregon CPA. Da das Datenmodell personenbezogene Daten von Grund auf minimiert und Aufbewahrungsfristen pro Entität kodiert, reduziert sich die regionale Compliance auf ehrliche Offenlegung und einen sauberen Consent-Flow statt einer Datentrennung pro Rechtsraum.
Die Build-Phase ist so konzipiert, dass sie über EU- und US-Regionen parallel ausgerollt wird — Niederlande, Deutschland, Frankreich, Schweden und Irland für die EU-Abdeckung; US-Ost und US-West für Nordamerika — sodass das gepaarte App-Paar beide Märkte ab dem Launch mit geringer Latenz bedient. Die Datenschutzerklärungs-Vorlage, die mit dem Discovery-Paket geliefert wird, dokumentiert die obige Architektur und verweist direkt auf die DSGVO-Pflichten und die kalifornischen CCPA-Pflichten. Das Discovery-Team ist über die MEZ verteilt und arbeitet einen MEZ-Arbeitstag mit Überlappung mit der US-Ostküste (9–13 Uhr ET) für Stakeholder-Interviews, Prototyp-Reviews und ADR-Gespräche — die Zeitzone, die einem US-Gründer und einem EU-Discovery-Team jeden Tag vier Stunden Live-Überlappung ermöglicht. Das Discovery-Paket bedient einen US- & EU-Launch als eine einheitliche Spezifikation.
Die aktive Roadmap für individuelle Softwareentwicklung bei FlowDelivery — sobald die Discovery an den Build übergeben wird — umfasst die Kunden-iOS- und -Android-Clients, den Floristen-Android-Client, ein Symfony- oder Laravel-Backend hinter der OpenAPI-Spezifikation, einen Verfügbarkeits-Neuberechnungs-Worker, eine Zahlungsanbieter-Integration mit Stripe und Apple Pay / Google Pay sowie eine Liefer-Routing-Ebene, die den reibungsärmsten Floristen pro Bestellung auswählt. Eine B2B-Stufe für Firmengeschenke in den USA und der EU ist als Phase-zwei-Erweiterung abgegrenzt, wobei das Berechtigungs-Teilsystem bereits für die Mehrfach-Empfänger-Zuweisung strukturiert ist. Die Infrastrukturpläne umfassen eine künftige unabhängige Readiness-Bewertung, eingebettet in die Cloud & DevOps-Roadmap, plus eine strukturierte Analytics-Pipeline, die den Consent-Flow vom ersten Tag an respektiert.
Wenn Sie ein gepaartes Kunden-und-Betreiber-Produkt, einen Marktplatz oder eine beliebige Plattform planen, bei der das Datenmodell das Produkt ist und eine build-team-agnostische Spezifikation für Zielgruppen in den USA und der EU der richtige Ausgangspunkt ist, haben wir diesen Discovery-Prozess durchgängig durchgeführt und können die Zeit bis zum investierbaren Artefakt spürbar verkürzen. Das Engineering- und Design-Team hinter FlowDelivery sitzt bei YuSMP Group. Wir arbeiten zum Festpreis für gut abgegrenzte Discoveries und mit dedizierten Entwicklerteams für die laufende Lieferung in die Build-Phase — mit einem MEZ-Arbeitstag und einem garantierten Zeitfenster der Überlappung mit der US-Ostküste (9–13 Uhr ET) für Stand-ups, Prototyp-Reviews und ADR-Gespräche.
Eine fokussierte Discovery, die Analytik, UX-Design, Systemarchitektur und das gemeinsame Datenmodell für ein gepaartes Kunden-plus-Betreiber-Produkt abdeckt, kostet typischerweise 35.000–90.000 €. Ergänzt man einen klickbaren Figma-Prototyp, eine OpenAPI-Spezifikation, eine Postman-Sammlung, eine Komponentenbibliothek mit Design-Tokens und ein Discovery-zu-Build-Übergabepaket, ergibt sich eine vollständige Spezifikations-Discovery für 95.000–180.000 €. Die dominierenden Kostentreiber sind das Customer-Journey-Mapping, das Datenmodell-Design und die Bestands- und Substitutionsrichtlinien-Arbeit, die Nacharbeit in der Build-Phase verhindert.
Ein Code-First-MVP bei einem gepaarten Kunden-plus-Betreiber-Produkt baut das Datenmodell in den ersten sechs Monaten typischerweise zwei- bis dreimal neu, weil sich die Bestandsregeln, die Substitutionsrichtlinie und der Multi-Store-Katalog nicht allein aus Bildschirmen ableiten lassen. Discovery-getriebenes Design erzeugt ein typisiertes Datenmodell, einen API-Vertrag und einen UX-Prototyp, bevor irgendein Produktionscode geschrieben wird, was die Build-Phase verkürzt, Nacharbeit reduziert und dem Gründer ein finanzierungsfähiges Artefakt für Investorengespräche lange vor der ersten Swift- oder Kotlin-Zeile liefert.
Ein bestandsbewusster Katalog ist eine Datenmodell-Entscheidung, bevor er eine UI-Entscheidung ist. Jeder Strauß ist ein Rezept aus Komponentenblumen; der Katalog berechnet die Verfügbarkeit pro Rezept, indem er den Live-Bestand über die Standorte des Floristen verknüpft, und blendet Rezepte aus, deren Komponenten nicht verfügbar sind. Dynamische Produktkarten berechnen den Preis aus den aktuellen Wareneinstandskosten neu, statt einen denormalisierten Cache zu lesen. Eine Substitutionsrichtlinien-Tabelle pro Rezept gibt dem Floristen eine genehmigte Austauschliste, die die visuelle Identität bewahrt, wenn eine Komponente knapp wird.
Ein Discovery-getriebenes Übergabepaket enthält eine Customer-Journey-Map, ein typisiertes Datenmodell mit Beziehungen und Constraints, eine OpenAPI-Spezifikation, eine Postman-Sammlung, die jeden Endpunkt durchläuft, eine Figma-Komponentenbibliothek mit Design-Tokens, einen klickbaren Prototyp, der die priorisierten Flows abdeckt, und einen schriftlichen Architecture Decision Record pro bedeutender Abwägung. Das Paket ist das Artefakt, das ein Build-Team — intern oder extern — nutzen kann, um einen Festpreis-Build mit Zuversicht abzugrenzen, und das ein Gründer nutzen kann, um Anbieterangebote auf gleicher Augenhöhe zu bewerten.
Eine fokussierte Discovery für ein gepaartes Kunden-plus-Betreiber-Produkt dauert typischerweise 6–10 Wochen. Die ersten zwei Wochen sind Stakeholder-Interviews und Analytik zum bestehenden Betrieb; die Wochen drei bis sechs decken das Datenmodell, die API-Spezifikation und den UX-Prototyp ab; die letzten zwei bis vier Wochen sind die Substitutionsrichtlinie, die Bestands-Neuberechnungslogik und das Discovery-zu-Build-Übergabepaket. Die audit-fähige Härtung der resultierenden Spezifikation — Secrets- und Datenschutz-Ausrichtung, region-bewusstes Consent-Design — sollte in der letzten Woche eingeplant werden.
Verwandte Fallstudien

Kunden-App, Picker-App, Admin-Panel für eine regionale Lebensmittelkette — von Grund auf entworfener Logistikprozess.
Fallstudie ansehen →
Lokale Marktplatz-Mobil-App für eine Offline-Kette für Kinderartikel — flexibler Katalog, Online-Bestandssynchronisierung.
Fallstudie ansehen →
Autoteile-Marktplatz plus Verkäufer-CRM — VIN-Suche, standortübergreifender Bestand.
Fallstudie ansehen →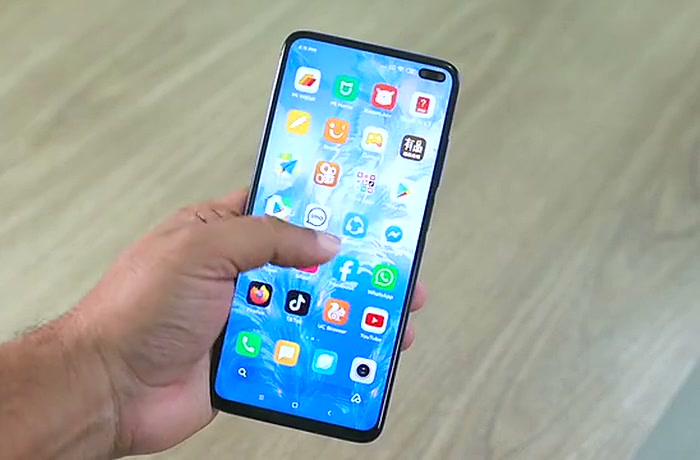
Native iOS, Android, and cross-platform apps with store-ready release pipelines.
Learn more →
Multi-tenant SaaS platforms with SSO, billing, region-pinned residency. SOC 2 in progress.
Learn more →
Senior engineers embedded into your Jira and standups in two weeks. CET workday with US East Coast overlap.
Learn more →Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.