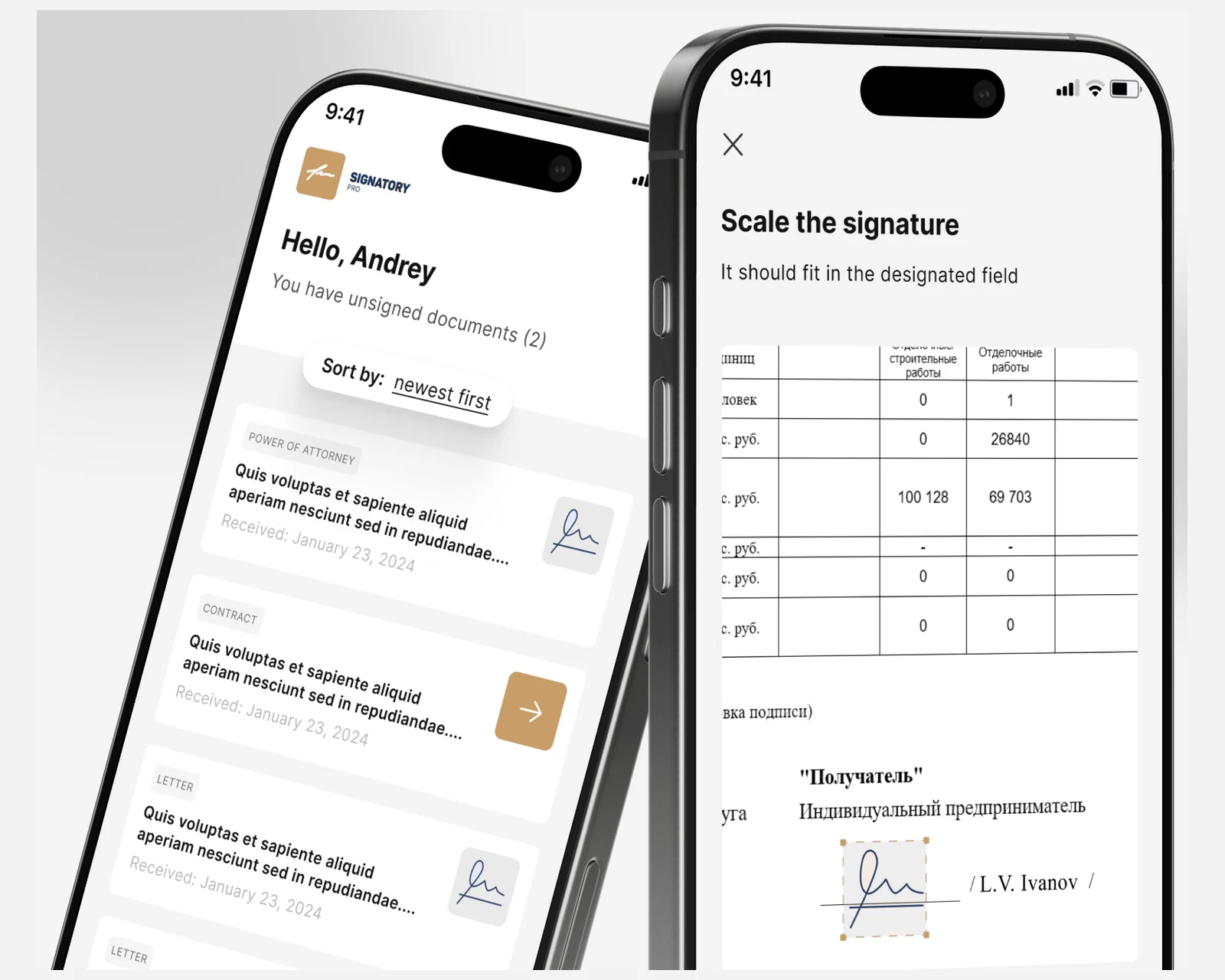
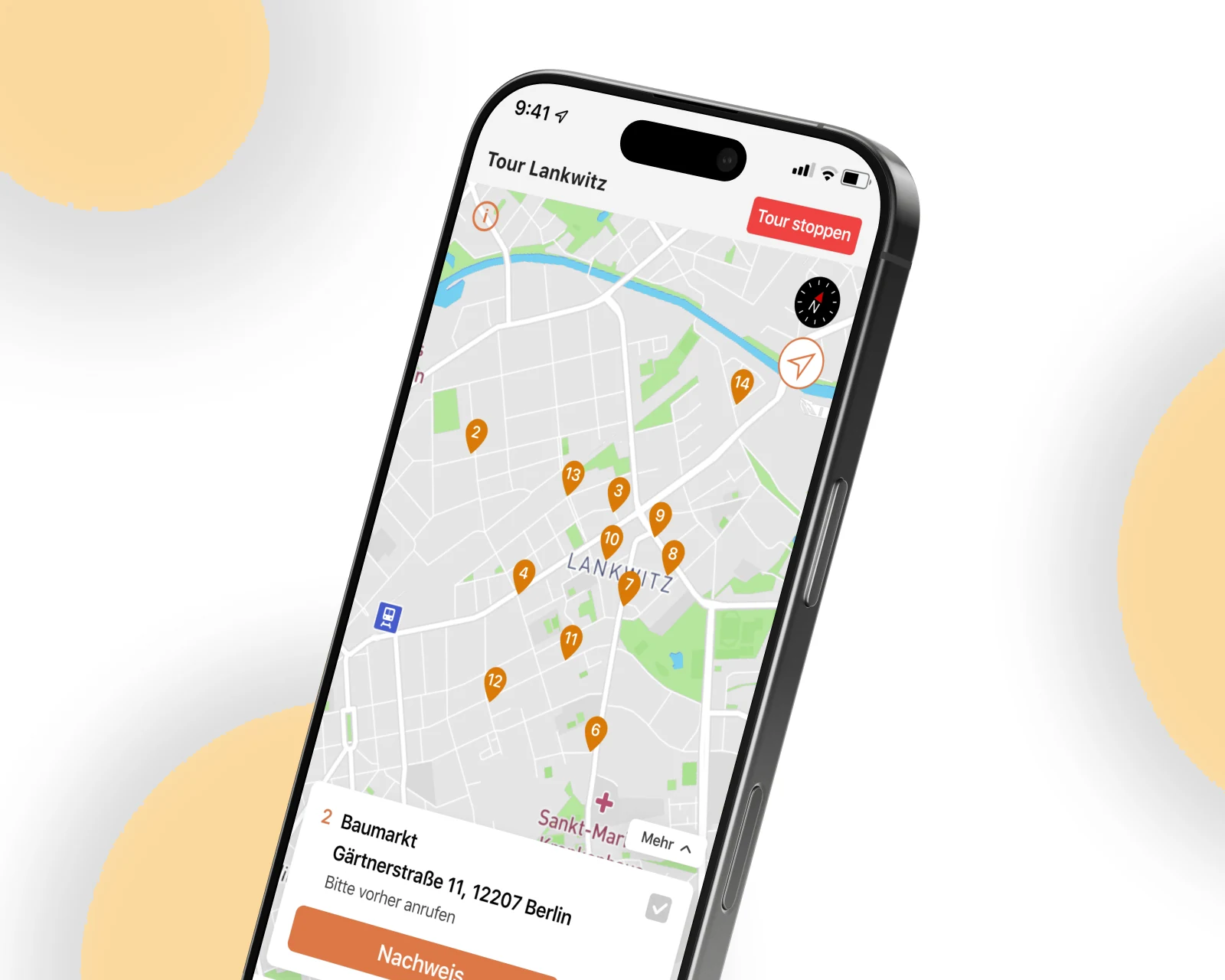
Use-Case-Mapping für Agenten
Wir bewerten Kandidaten-Workflows nach den drei Agenten-Voraussetzungen — nicht-deterministischer Tool-Aufruf, sich entwickelnder Zustand, verifizierbare Erfolgskriterien — und nennen explizit die Fälle, bei denen eine Pipeline plus ein LLM-Aufruf schneller und günstiger liefern würde.