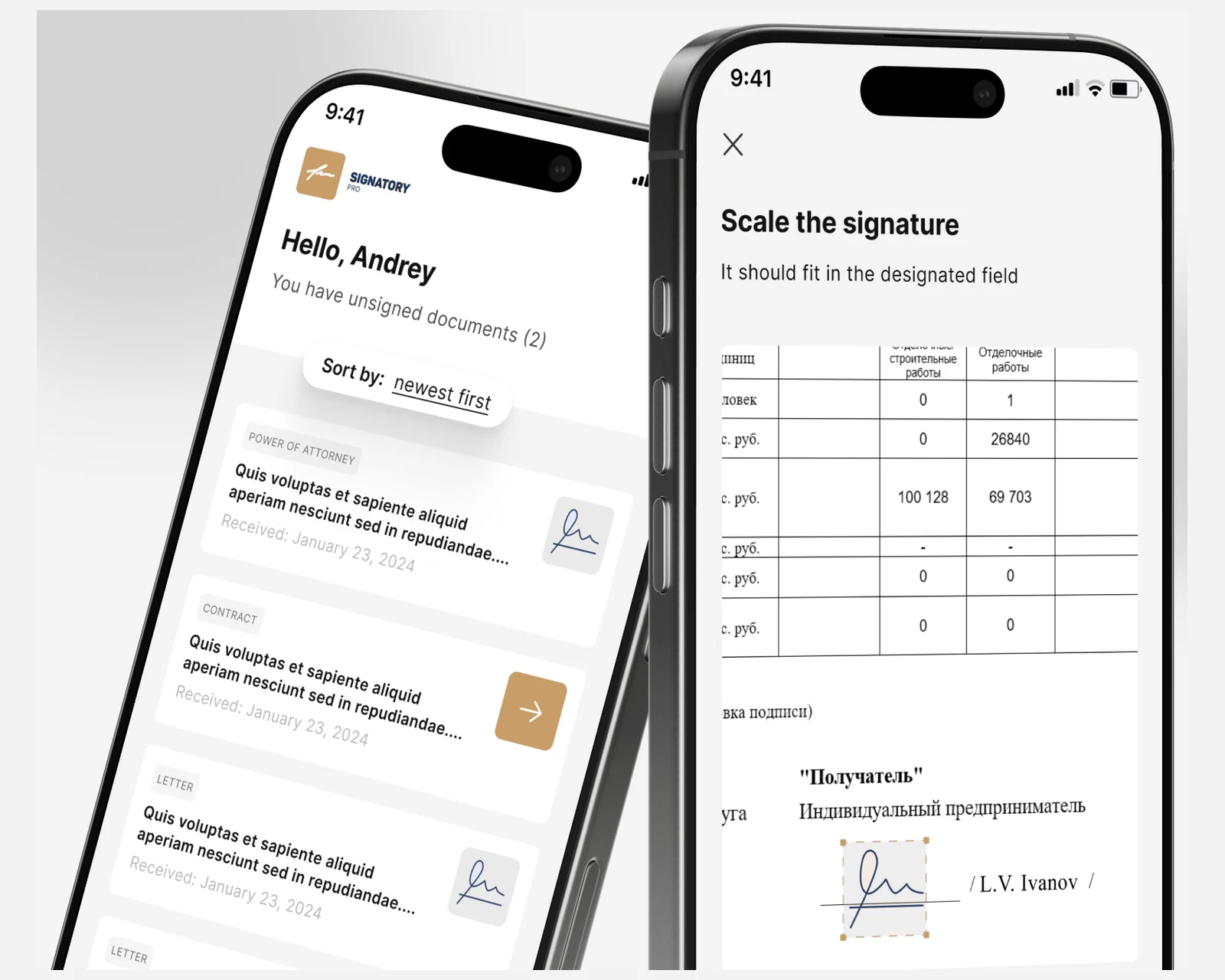
Absichtsdesign & Gesprächsflows
Workshop mit Ihrem Support-, Vertriebs- oder Operations-Team zur Abbildung echter Nutzerabsichten aus Ticket- und Chat-Daten. Flow-Diagramme, Slot-Filling-Logik, Eskalationsregeln und ein schriftliches Gesprächsdesign-Dokument, bevor Code ausgeliefert wird.