DAG-Design & Idempotenz
Nicht-idempotente Tasks beschädigen Daten beim Retry, und DAGs, die die Execution-Date-Semantik ignorieren, machen Backfills und historische Reruns gefährlich statt zur Routine.
Airflow DAGs Orchestrierung Data Pipelines
Wir bauen und betreiben produktives Apache Airflow für Datenteams in den USA und der EU — und orchestrieren Batch-ELT, Warehouse-Loads und Analytics-Pipelines, die planmäßig laufen und sich nach einem Fehler sauber erholen. Unsere Entwickler schreiben idempotente DAGs, wählen den richtigen Executor für Ihren Durchsatz und integrieren Monitoring, SLAs und Alerting, sodass Fehler sichtbar werden, bevor Stakeholder sie bemerken. Ob Sie selbst hosten oder Managed Airflow auf MWAA, Cloud Composer oder Astronomer betreiben — Sie erhalten Pipelines, die beobachtbar, auditierbar und auch mit regulierten Daten sicher sind.

Wir bauen und betreiben produktives Apache Airflow für Datenteams in den USA und der EU — und orchestrieren Batch-ELT, Warehouse-Loads und Analytics-Pipelines, die planmäßig laufen und sich nach einem Fehler sauber erholen. Unsere Entwickler schreiben idempotente DAGs, wählen den richtigen Executor für Ihren Durchsatz und integrieren Monitoring, SLAs und Alerting, sodass Fehler sichtbar werden, bevor Stakeholder sie bemerken. Ob Sie selbst hosten oder Managed Airflow auf MWAA, Cloud Composer oder Astronomer betreiben — Sie erhalten Pipelines, die beobachtbar, auditierbar und auch mit regulierten Daten sicher sind.
Herausforderungen
Nicht-idempotente Tasks beschädigen Daten beim Retry, und DAGs, die die Execution-Date-Semantik ignorieren, machen Backfills und historische Reruns gefährlich statt zur Routine.
Ein einzelner Scheduler und die falsche Executor-Wahl geraten bei hunderten gleichzeitigen Tasks ins Stocken — DAGs bleiben in der Warteschlange, Slots sind ausgehungert und SLAs werden zu Spitzenzeiten verfehlt.
In DAGs hartkodierte oder in einfachen Connections gespeicherte Zugangsdaten gelangen über Logs und Versionskontrolle nach außen, und ihre Rotation wird zu einem manuellen, fehleranfälligen Kraftakt.
Ohne abgestimmte Retries, SLA-Miss-Callbacks und echtes Alert-Routing scheitern Pipelines stillschweigend, und das Datenteam erfährt es von einem kaputten Dashboard.
Große Payloads oder PII durch XCom zu schieben bläht die Metadaten-Datenbank auf und gibt sensible Daten preis; Tasks sollten Referenzen übergeben, keine Datensätze.
Von Hand kopierte DAG-Dateien, fehlende Abhängigkeitsparität und ungetestete Änderungen verursachen Import-Fehler und gebrochene Zeitpläne, sobald ein DAG in Produktion geht.
Lösungen
Wir gestalten DAGs rund um idempotente, retry-sichere Tasks mit expliziten Abhängigkeiten und sauberem Backfill-Verhalten — mit Execution-Date-Logik und der TaskFlow API.
Wir orchestrieren ELT durchgängig — Ingestion, dbt-Transformationen und Warehouse-Loads in Snowflake oder BigQuery — mit Datenqualitätsprüfungen, die nachgelagerte Tasks freigeben.
Wir dimensionieren und optimieren den Celery- oder Kubernetes-Executor, Pools und Concurrency, sodass DAGs horizontal skalieren und Pipelines mit hoher Priorität nie aushungern.
Wir integrieren SLA-Miss-Callbacks, Fehler-Alerting an Slack/PagerDuty und Metriken, sodass jeder Lauf beobachtbar ist und Vorfälle früh erkannt werden.
Wir verlagern Zugangsdaten in ein Secrets-Backend (Vault, AWS-/GCP-Secret-Manager) mit eingegrenzten Connections, Rotation und ohne sensible Werte in Code oder Logs.
Wir richten Airflow auf MWAA, Cloud Composer oder Astronomer ein oder migrieren es — dimensionieren Umgebungen, konfigurieren CI/CD für DAGs und stellen ohne Datenverlust um.
Stack
Apache Airflow, DAGs, Operators & Hooks, TaskFlow API, Celery-/Kubernetes-Executor, dbt, Snowflake/BigQuery, MWAA/Astronomer/Cloud Composer und Docker.
Compliance
DSGVO · auditfähige Lauf-Historie · HIPAA-fähig · SOC 2
Cases
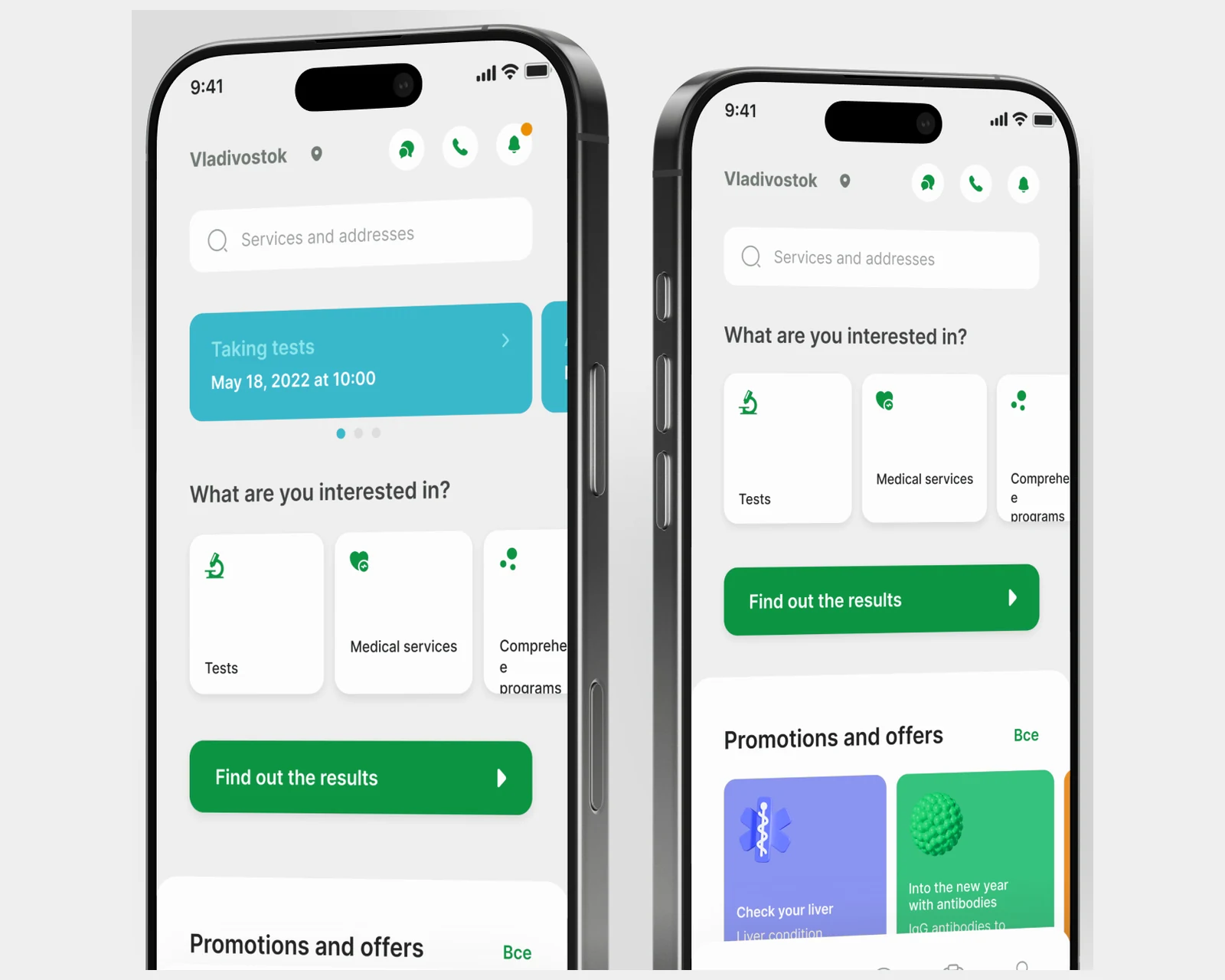
Patienten-App für ein Labornetzwerk in 40 Städten — Terminbuchung, digitale Ergebnisse, 2.500+ Tests, Integrationen für Terminplanung und Buchhaltung.
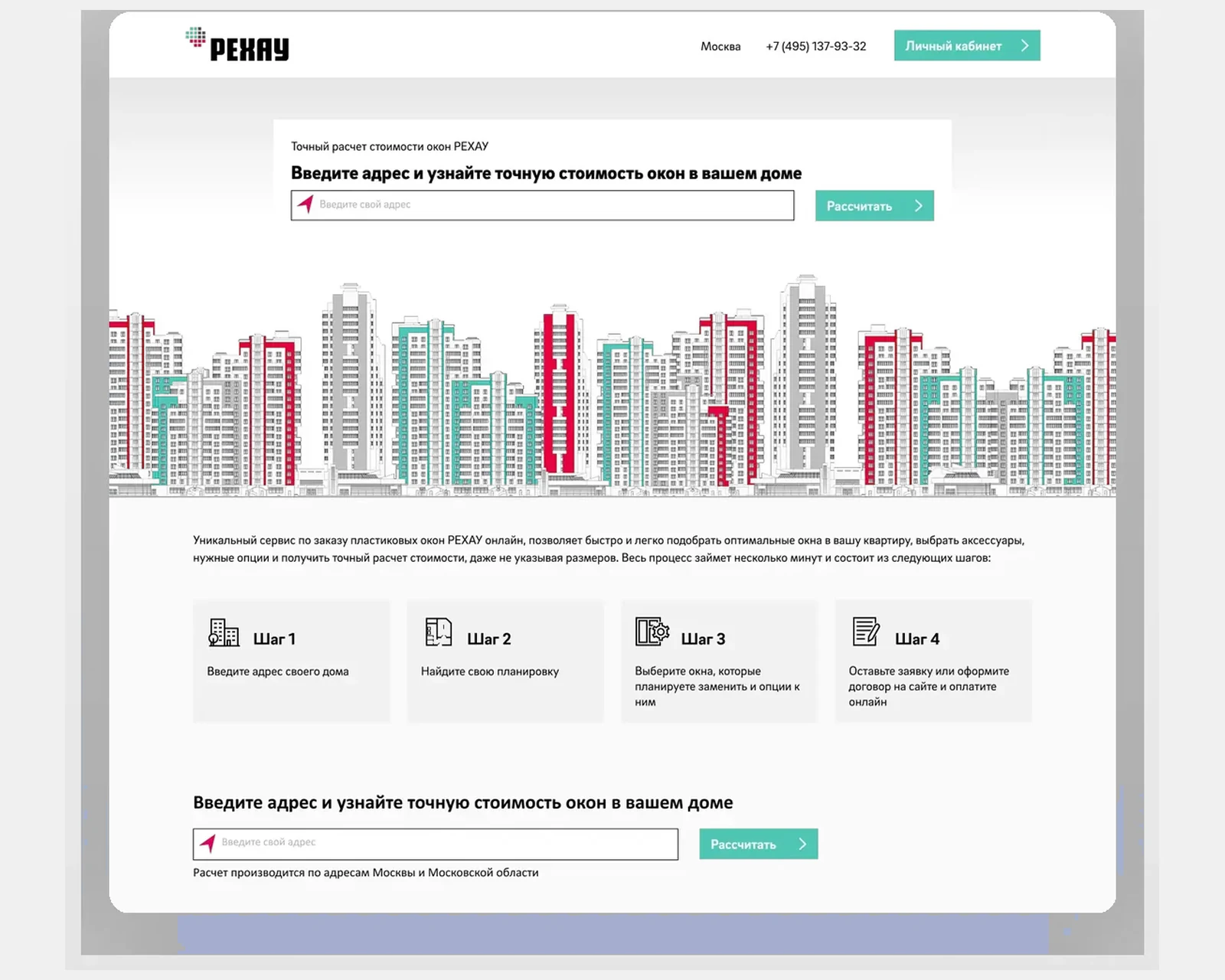
B2B-E-Commerce und Produktkonfigurator für einen globalen Polymerhersteller mit Preisgestaltung, Beständen und Händler-Workflows über mehrere Regionen.
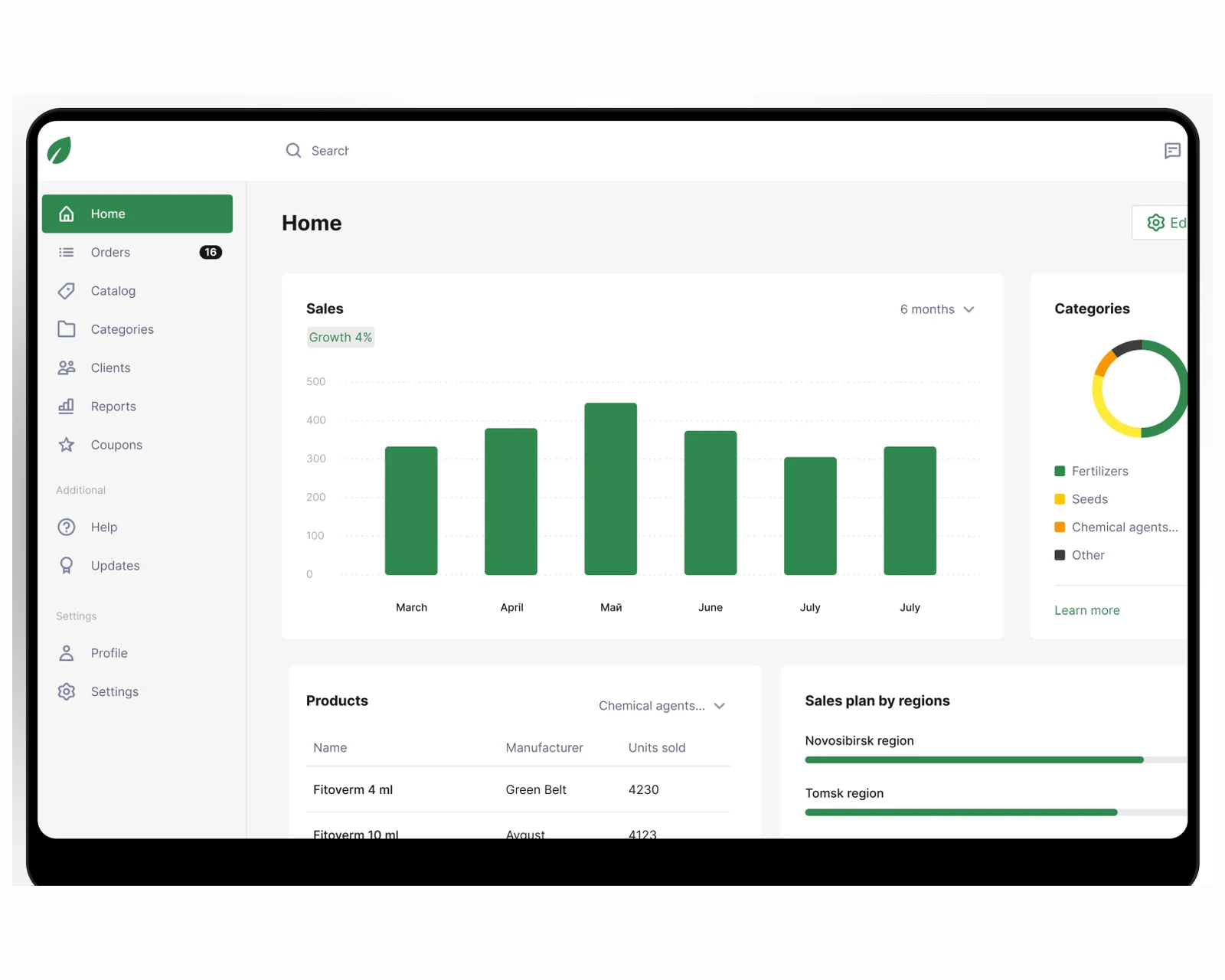
Offline-first iOS- & Android-Außendienst-App für einen Agrardistributor — strukturierter Katalog, Deal-Reporting, Plan vs. Ist.
Warum YuSMP
Sie arbeiten mit Entwicklern, die Airflow gegen echte Warehouses und dbt in Produktion betreiben — keine Generalisten, die ihren ersten DAG verdrahten.
Wir arbeiten in überlappenden Zeiten mit Datenteams in den USA und der EU und bauen vom ersten DAG an nach DSGVO, HIPAA und SOC 2.
Idempotente DAGs, Executor-Tuning, Secrets-Hygiene, Monitoring und DAG-CI/CD gehören zum Standard, sodass Ihre Pipelines wartbar sind statt fragil.
FAQ
Airflow ist der ausgereifte, batch-orientierte Standard für geplante Datenorchestrierung mit dem breitesten Ökosystem an Operators und Managed-Optionen. Dagster und Prefect sind starke moderne Alternativen mit besserer lokaler Entwicklung und asset- bzw. datenbewussten Modellen, während Temporal auf langlebige Anwendungs-Workflows statt auf Daten-Pipelines abzielt. Wir empfehlen Airflow, wenn Sie bewährtes, zeitplangesteuertes Batch-ETL/ELT und eine umfangreiche Operator-Bibliothek benötigen — und sagen es Ihnen, wenn eine der anderen Lösungen besser zu Ihrem Team passt.
Ein DAG (Directed Acyclic Graph) ist die Definition einer Pipeline als Python-Code — eine Menge von Tasks und ihrer Abhängigkeiten, ohne Zyklen. Operators sind die Bausteine, die festlegen, was jeder Task tatsächlich tut, etwa SQL ausführen, eine API aufrufen oder einen Container starten, während Hooks die Verbindungen zu externen Systemen herstellen. Gemeinsam ermöglichen sie es Ihnen, komplexe, geplante Pipelines als versionierten Code auszudrücken.
Idempotenz bedeutet, dass ein Task dasselbe korrekte Ergebnis liefert, egal ob er einmal läuft oder wiederholt wird — entscheidend, weil Airflow fehlgeschlagene Tasks erneut ausführt und Sie Historien neu durchlaufen werden. Wir gestalten Tasks so, dass sie eine bestimmte Execution-Date-Partition überschreiben oder per Upsert aktualisieren, statt blind anzuhängen, sodass erneute Läufe Daten nie duplizieren oder beschädigen. Backfills werden dadurch sicher: Sie können jeden Datumsbereich erneut abspielen, um historische Daten zu laden oder sich zuverlässig von einem Vorfall zu erholen.
Der Celery-Executor führt Tasks auf einem Pool langlebiger Worker aus und ist effizient für viele kurze, häufige Tasks mit vorhersehbarem Ressourcenbedarf. Der Kubernetes-Executor startet pro Task einen isolierten Pod, was task-spezifische Ressourcen, Abhängigkeitsisolation und elastische Skalierung bis auf null ermöglicht — auf Kosten der Pod-Startlatenz. Wir wählen anhand Ihres Task-Profils und Ihrer Infrastruktur aus und kombinieren beide häufig, sodass schwere oder spezialisierte Tasks auf Kubernetes laufen, während Routineaufgaben Celery nutzen.
Managed-Optionen — AWS MWAA, Google Cloud Composer oder Astronomer — nehmen Ihnen den Betriebsaufwand für Scheduler, Datenbank und Worker ab und sind in der Regel die richtige Wahl, sofern Sie keine besonderen Kontroll- oder Kostenanforderungen haben. Self-Hosting auf Kubernetes bietet maximale Flexibilität, bedeutet aber, dass Sie Upgrades, Skalierung und Verfügbarkeit selbst verantworten. Wir helfen Ihnen, Kosten, Compliance und Teamkapazität abzuwägen, und richten dann das passende Modell ein oder migrieren darauf.
Zugangsdaten liegen niemals im DAG-Code oder in einfachen Airflow-Connections; wir integrieren ein Secrets-Backend wie HashiCorp Vault oder Ihren Cloud-Secret-Manager mit eingegrenztem Zugriff und Rotation. PII halten wir vollständig aus Task-Logs und XCom heraus — Tasks übergeben Referenzen und arbeiten direkt am Ort der Daten im Warehouse, mit Maskierung bei unvermeidbarem Logging. So bleiben Pipelines DSGVO- und HIPAA-konform und dennoch debugfähig.
Airflow ist ein Batch-Scheduler, keine Streaming-Engine. Wenn Sie Echtzeit- oder Sub-Minuten-Verarbeitung benötigen — Event-Streams, kontinuierliches CDC oder Reaktionen mit geringer Latenz — sind Kafka, Flink, Spark Streaming oder ein Streaming-Warehouse-Muster die richtige Wahl, wobei Airflow optional die umgebenden Batch-Jobs orchestriert. Wir sagen Ihnen, wenn Ihre Latenzanforderungen gegen Airflow sprechen, statt es mit Gewalt passend zu machen.
Antwort innerhalb von 1 Werktag. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.