DAG design & idempotency
Non-idempotent tasks corrupt data on retry, and DAGs that ignore execution-date semantics make backfills and historical reruns dangerous instead of routine.
Airflow DAGs Orchestration Data Pipelines
We build and operate production Apache Airflow for US and EU data teams — orchestrating batch ELT, warehouse loads and analytics pipelines that run on schedule and recover cleanly when they fail. Our engineers write idempotent DAGs, choose the right executor for your throughput, and wire in monitoring, SLAs and alerting so failures surface before stakeholders notice. Whether you self-host or run managed Airflow on MWAA, Cloud Composer or Astronomer, you get pipelines that are observable, auditable and safe with regulated data.

We build and operate production Apache Airflow for US and EU data teams — orchestrating batch ELT, warehouse loads and analytics pipelines that run on schedule and recover cleanly when they fail. Our engineers write idempotent DAGs, choose the right executor for your throughput, and wire in monitoring, SLAs and alerting so failures surface before stakeholders notice. Whether you self-host or run managed Airflow on MWAA, Cloud Composer or Astronomer, you get pipelines that are observable, auditable and safe with regulated data.
Challenges
Non-idempotent tasks corrupt data on retry, and DAGs that ignore execution-date semantics make backfills and historical reruns dangerous instead of routine.
A single scheduler and the wrong executor choke under hundreds of concurrent tasks, leaving DAGs queued, slots starved and SLAs missed at peak.
Credentials hard-coded in DAGs or stored in plain connections leak through logs and source control, and rotating them becomes a manual, error-prone scramble.
Without tuned retries, SLA miss callbacks and real alert routing, pipelines fail silently and the data team finds out from a broken dashboard.
Pushing large payloads or PII through XCom bloats the metadata database and leaks sensitive data; tasks should pass references, not rows.
Hand-copied DAG files, missing dependency parity and untested changes cause import errors and broken schedules the moment a DAG hits production.
Solutions
We design DAGs around idempotent, retry-safe tasks with explicit dependencies and clean backfill behaviour using execution-date logic and the TaskFlow API.
We orchestrate ELT end to end — ingestion, dbt transformations and warehouse loads into Snowflake or BigQuery — with data-quality checks gating downstream tasks.
We size and tune the Celery or Kubernetes executor, pools and concurrency so DAGs scale horizontally and high-priority pipelines never starve.
We wire in SLA miss callbacks, failure alerting to Slack/PagerDuty and metrics so every run is observable and incidents are caught early.
We move credentials into a secrets backend (Vault, AWS/GCP secret managers) with scoped connections, rotation and no sensitive values in code or logs.
We set up or migrate Airflow on MWAA, Cloud Composer or Astronomer — sizing environments, configuring CI/CD for DAGs and cutting over with zero data loss.
Stack
Apache Airflow, DAGs, operators & hooks, TaskFlow API, Celery/Kubernetes executor, dbt, Snowflake/BigQuery, MWAA/Astronomer/Cloud Composer, and Docker.
Compliance
GDPR · audit-grade run history · HIPAA-ready · SOC 2
Cases
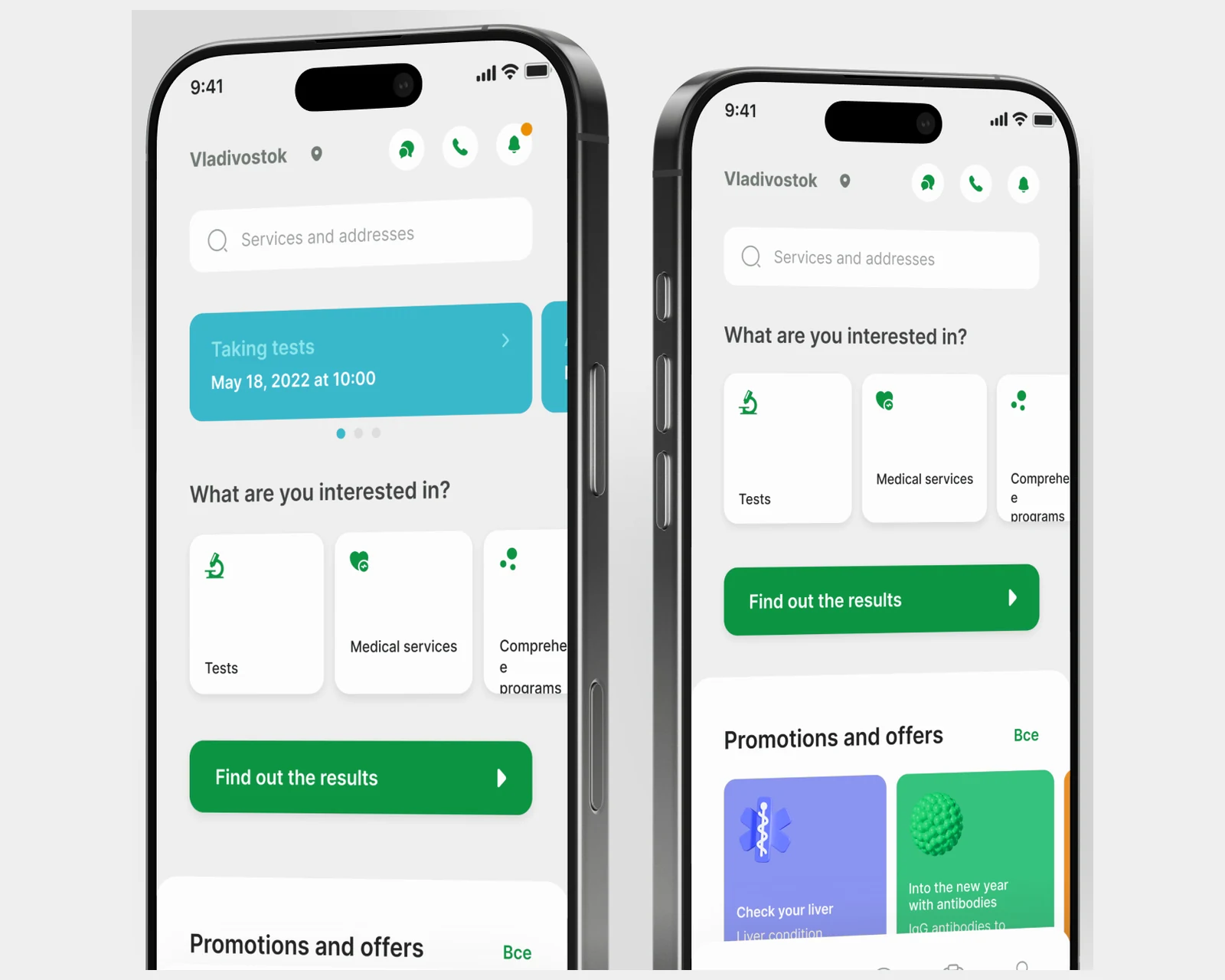
Patient app for a 40-city lab network — appointment booking, digital results, 2,500+ tests, scheduling and accounting integrations.
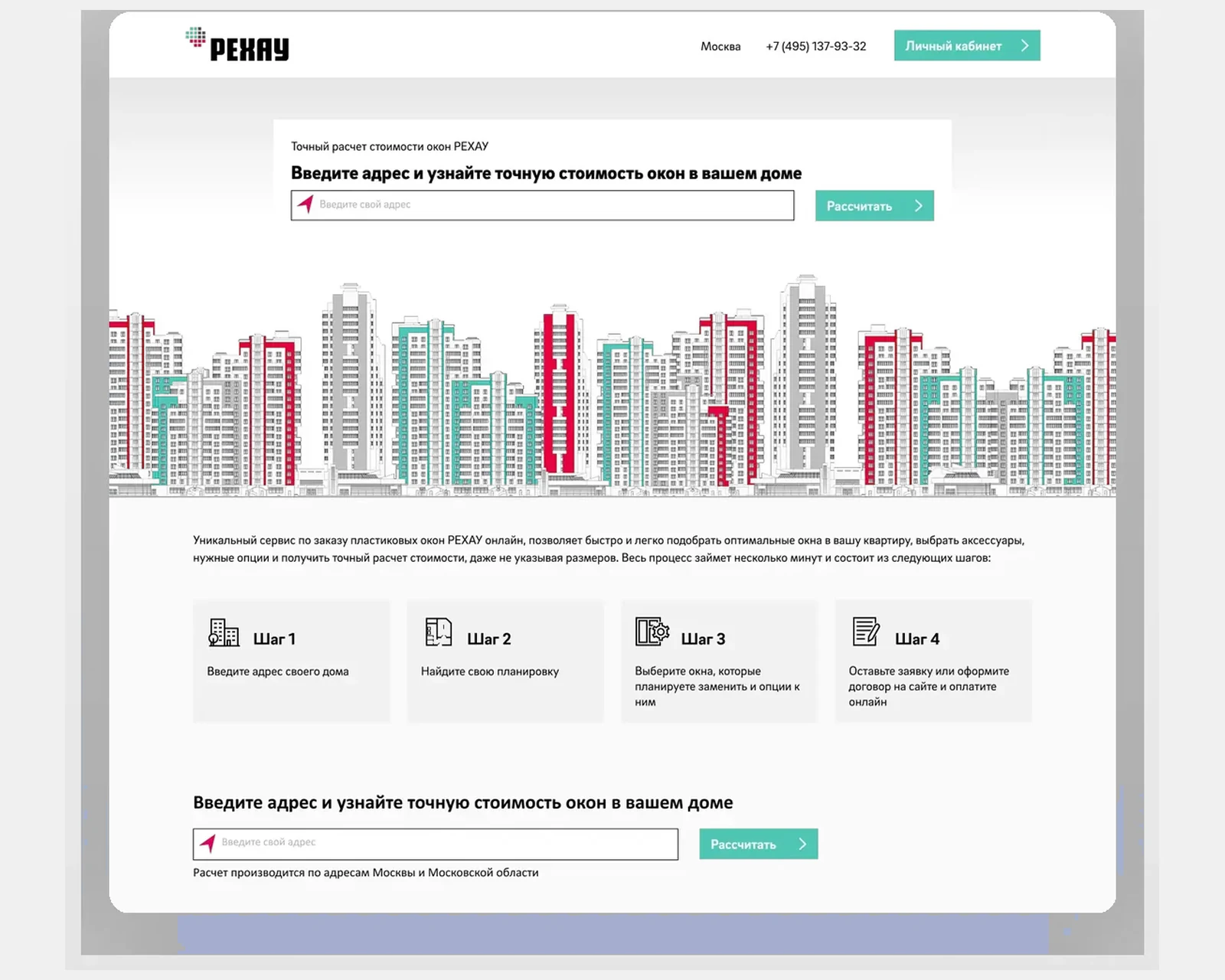
B2B e-commerce and product configurator for a global polymer manufacturer with multi-region pricing, stock and dealer workflows.
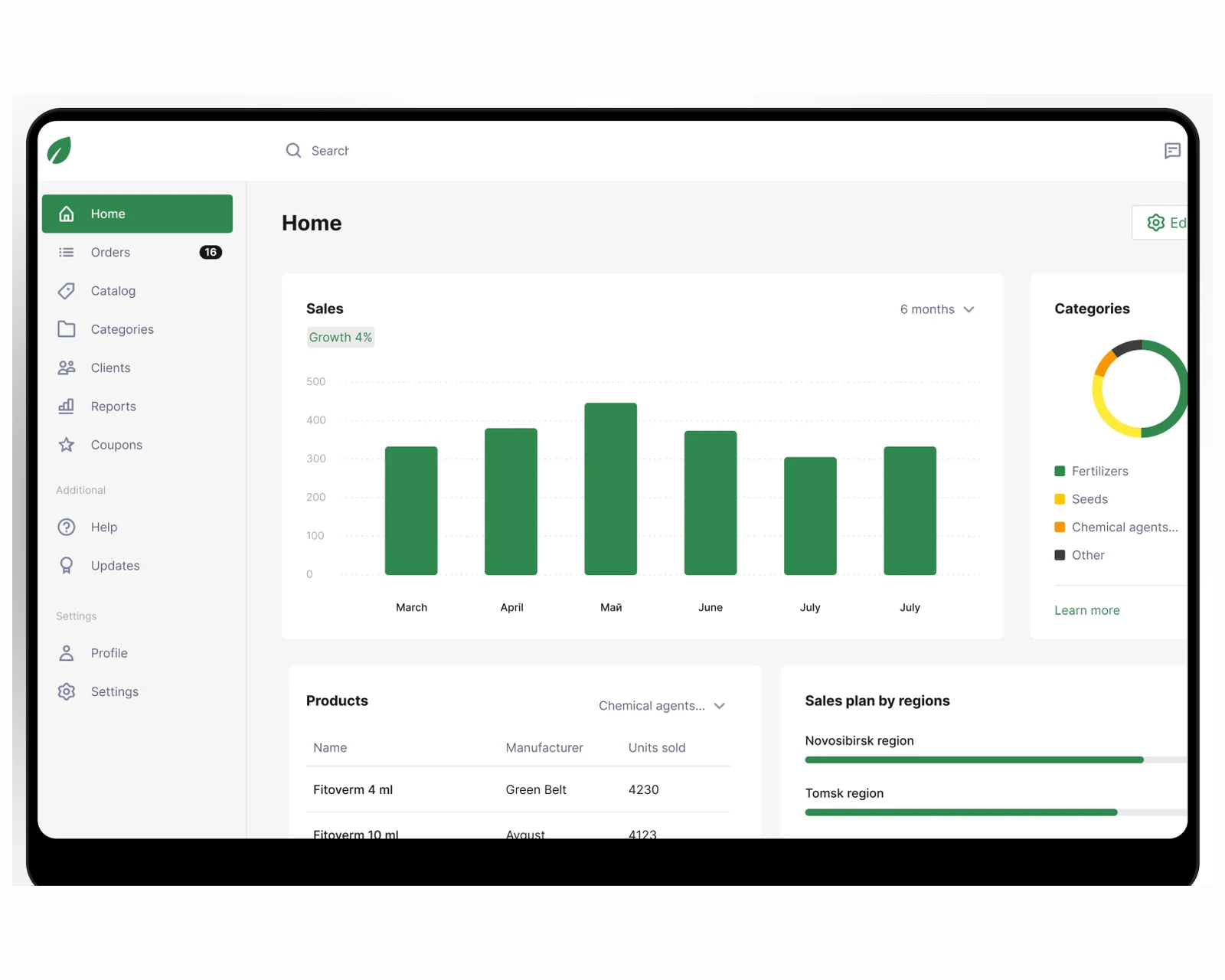
Offline-first iOS & Android field-sales app for an agricultural distributor — structured catalog, deal reporting, plan vs actual.
Why YuSMP
You work with engineers who run Airflow against real warehouses and dbt in production, not generalists wiring their first DAG.
We operate in overlapping hours with US and EU data teams and build to GDPR, HIPAA and SOC 2 from the first DAG.
Idempotent DAGs, executor tuning, secrets hygiene, monitoring and DAG CI/CD ship as standard, so your pipelines are maintainable, not fragile.
FAQ
Airflow is the mature, batch-oriented standard for scheduled data orchestration, with the widest ecosystem of operators and managed options. Dagster and Prefect are strong modern alternatives with better local development and asset/data-aware models, while Temporal targets durable application workflows rather than data pipelines. We recommend Airflow when you need proven, schedule-driven batch ETL/ELT and a large operator library, and will say so when one of the others fits your team better.
A DAG (Directed Acyclic Graph) is the definition of a pipeline as Python code — a set of tasks and the dependencies between them, with no cycles. Operators are the building blocks that define what each task actually does, such as running SQL, calling an API or launching a container, while hooks handle the connections to external systems. Together they let you express complex, scheduled pipelines as version-controlled code.
Idempotency means a task produces the same correct result whether it runs once or is retried — essential because Airflow retries failed tasks and you will rerun history. We design tasks to overwrite or upsert a specific execution-date partition rather than blindly append, so reruns never duplicate or corrupt data. Backfills then become safe: you can replay any date range to load historical data or recover from an incident with confidence.
The Celery executor runs tasks on a pool of long-lived workers and is efficient for many short, frequent tasks with predictable resource needs. The Kubernetes executor launches an isolated pod per task, giving per-task resources, dependency isolation and elastic scale-to-zero, at the cost of pod start-up latency. We pick based on your task profile and infrastructure, and often pair them so heavy or specialised tasks run on Kubernetes while routine ones use Celery.
Managed options — AWS MWAA, Google Cloud Composer or Astronomer — remove the operational burden of running the scheduler, database and workers, and are usually the right call unless you have specific control or cost requirements. Self-hosting on Kubernetes gives maximum flexibility but means you own upgrades, scaling and availability. We help you weigh cost, compliance and team capacity, then set up or migrate to whichever model fits.
Credentials never live in DAG code or plain Airflow connections; we integrate a secrets backend such as HashiCorp Vault or your cloud secret manager, with scoped access and rotation. For PII we keep personal data out of task logs and XCom entirely — tasks pass references and operate on data in place inside the warehouse, with masking on any unavoidable logging. This keeps pipelines compliant with GDPR and HIPAA while remaining debuggable.
Airflow is a batch scheduler, not a streaming engine. If you need real-time or sub-minute processing — event streams, continuous CDC or low-latency reactions — you want Kafka, Flink, Spark Streaming or a streaming warehouse pattern instead, with Airflow optionally orchestrating the surrounding batch jobs. We will tell you when your latency requirements rule Airflow out rather than forcing a fit.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.