Skalierbare Projektstruktur
Ohne eine bewusste Schichtung von Staging → Intermediate → Marts wuchern dbt-Projekte zu Hunderten voneinander abhängiger Modelle, die niemand mehr sicher navigieren oder refactoren kann.
dbt Analytics Engineering ELT SQL
Wir bauen die Transformationsebene Ihres modernen Data Stacks mit dbt — und machen aus rohen Warehouse-Tabellen kontrollierte, getestete und dokumentierte Datenprodukte. Unsere Analytics Engineers betreuen Datenteams in den USA und der EU, die zuverlässige Marts, klare Lineage und schnelle, kostenbewusste Läufe benötigen. Von Greenfield-dbt-Projekten bis zur Rettung verworrenen SQL-Codes liefern wir wartbare Modelle, denen Analysten und Stakeholder wirklich vertrauen.

Wir bauen die Transformationsebene Ihres modernen Data Stacks mit dbt — und machen aus rohen Warehouse-Tabellen kontrollierte, getestete und dokumentierte Datenprodukte. Unsere Analytics Engineers betreuen Datenteams in den USA und der EU, die zuverlässige Marts, klare Lineage und schnelle, kostenbewusste Läufe benötigen. Von Greenfield-dbt-Projekten bis zur Rettung verworrenen SQL-Codes liefern wir wartbare Modelle, denen Analysten und Stakeholder wirklich vertrauen.
Herausforderungen
Ohne eine bewusste Schichtung von Staging → Intermediate → Marts wuchern dbt-Projekte zu Hunderten voneinander abhängiger Modelle, die niemand mehr sicher navigieren oder refactoren kann.
Naive Full-Refresh-Läufe verarbeiten bei jedem Build die gesamte Historie neu und verbrennen Warehouse-Credits; die richtige inkrementelle Strategie zu wählen und spät eintreffende Daten zu handhaben, ist wirklich schwierig.
Ungetestete Modelle zerstören still und leise nachgelagerte Dashboards; Teams ringen mit der Frage, was, wo und wie streng zu testen ist, ohne jeden Lauf zum Kriechen zu bringen.
Übertrieben raffiniertes Jinja und kopiertes SQL verstoßen gegen DRY und werden unleserlich; eine Unternutzung von Makros lässt Logik über Dutzende Modelle hinweg dupliziert zurück.
Nur das Geänderte auszuführen und zu testen (Slim CI) gegen ephemere oder isolierte Umgebungen ist alles andere als trivial — doch ohne dies gefährdet jeder Pull Request das gesamte Warehouse.
Mit der Vervielfachung der Modelle wird die Lineage undurchsichtig, die Dokumentation verrottet und niemand verantwortet einen bestimmten Mart — was Impact-Analysen und Vertrauen unmöglich macht.
Lösungen
Wir strukturieren Projekte in Staging-, Intermediate- und Mart-Ebenen mit konsistenten Namens-, Source- und Ordnerkonventionen, damit das Projekt auch im Wachstum verständlich bleibt.
Wir implementieren die passenden inkrementellen Materialisierungen und Strategien (merge, insert-overwrite, microbatch), behandeln spät eintreffende Daten und die Full-Refresh-Policy und senken die Warehouse-Ausgaben.
Wir ergänzen generische und singuläre Tests, Schema-Contracts, Freshness-Prüfungen und Pakete, damit Fehler in der CI auftauchen — und nicht im Dashboard eines Stakeholders.
Wir extrahieren gemeinsame Logik in gut dokumentierte Makros und setzen geprüfte Pakete ein (dbt_utils, codegen, dbt_expectations), um die Codebasis DRY und konsistent zu halten.
Wir verdrahten Slim CI bei Pull Requests, trennen Dev-/CI-/Prod-Targets und automatisieren Builds, sodass vor dem Merge nur geänderte Modelle und ihre Kinder ausgeführt und getestet werden.
Wir generieren dbt-Docs mit vollständiger Lineage, ergänzen Beschreibungen, Exposures und Ownership-Metadaten und definieren ein Governance-Modell, auf das sich Ihr gesamtes Team verlassen kann.
Stack
dbt Core, dbt Cloud, Adapter für Snowflake/BigQuery/Databricks/Redshift, Jinja-Makros, Tests & Snapshots, Exposures, dbt-Docs/-Lineage, Git, CI.
Compliance
DSGVO · getestete Datenqualität · Lineage/Governance · SOC 2
Cases
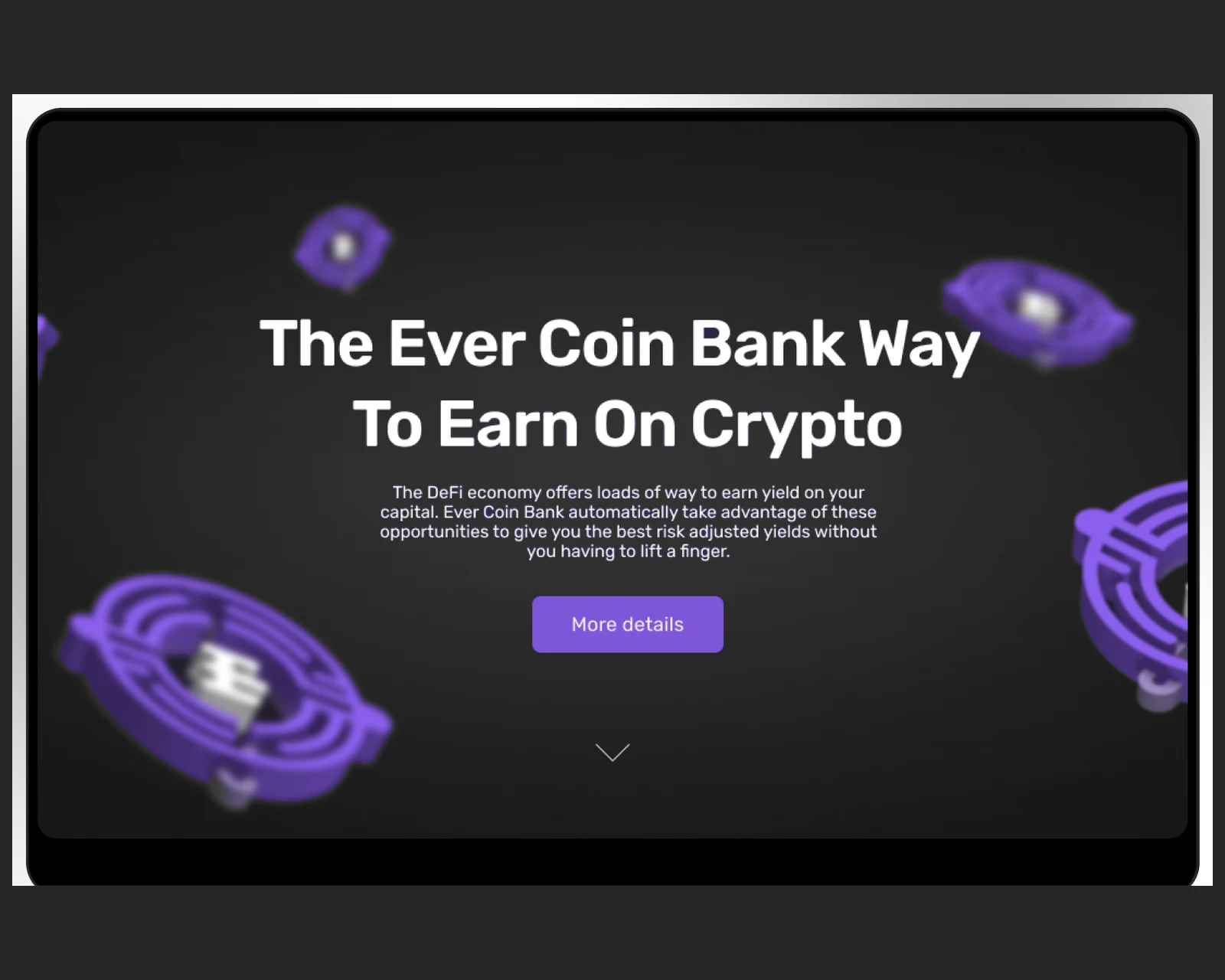
Vereinheitlichter Krypto-Ökosystem-Hub, der mehrere Tokens aggregiert — Live-Börsendaten, Suche, Charts, direkter Einstiegspunkt zum Kauf.
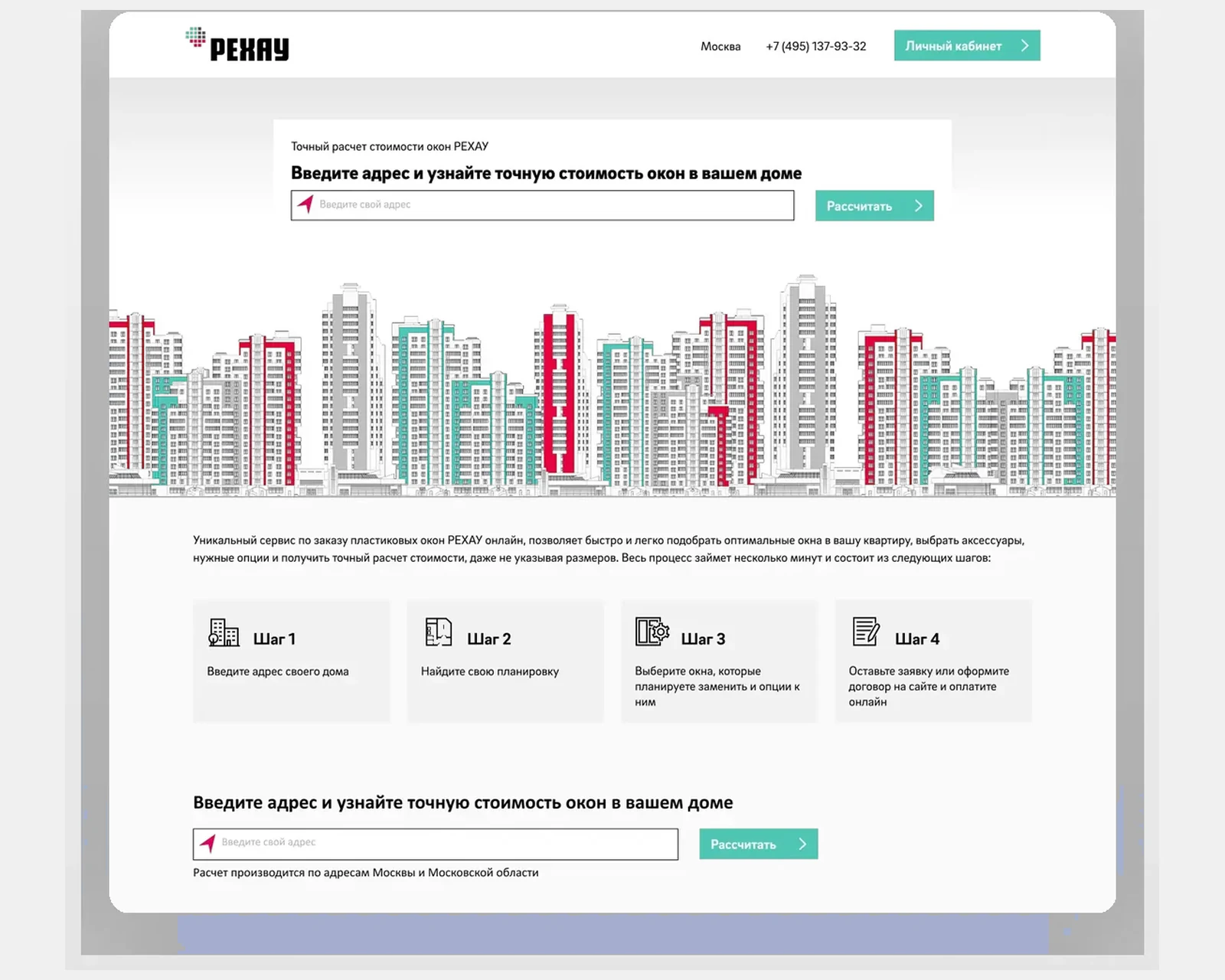
B2B-E-Commerce und Produktkonfigurator für einen globalen Polymerhersteller mit länderübergreifender Preisgestaltung, Bestands- und Händler-Workflows.
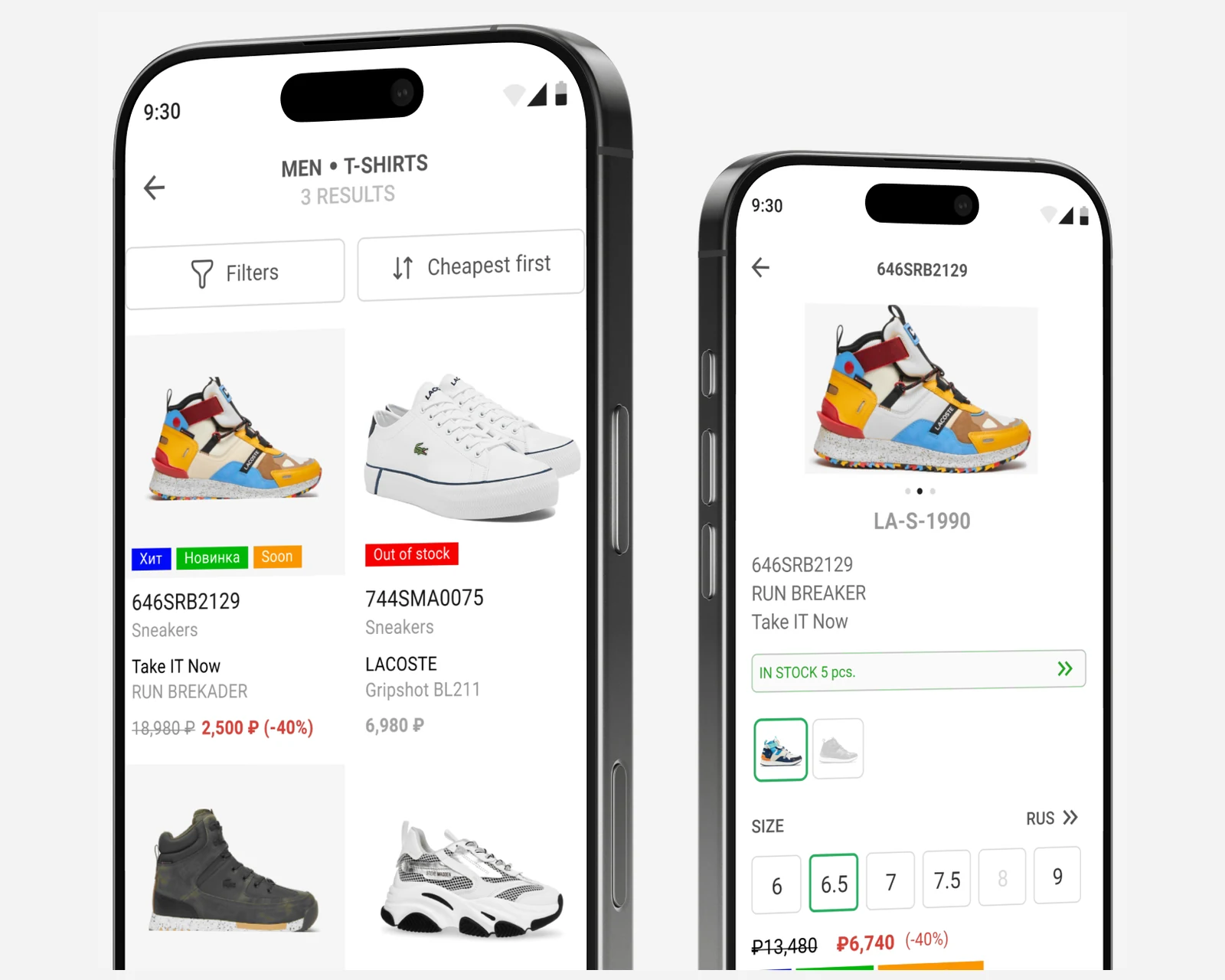
Retail-POS-Begleit-App für eine Multi-Brand-Boutique-Kette — filialübergreifende ElasticSearch-Bestandssuche, Integration in das 1C-System.
Warum YuSMP
Wir wissen, dass dbt das T in ELT erledigt — es transformiert Daten, die bereits in Ihrem Warehouse liegen, es ist kein Ingestion-Tool und kein Orchestrator —, daher konzipieren wir Pipelines, die zur Realität passen.
Jedes Modell, das wir ausliefern, kommt mit Tests, Dokumentation und Lineage, sodass sich Analysten, Führungskräfte und nachgelagerte Systeme auf die Zahlen verlassen können.
Snowflake, BigQuery, Databricks oder Redshift — wir stimmen Materialisierungen, Kosten und Adapter-Spezifika auf Ihre Plattform ab statt auf eine Einheitslösung.
FAQ
dbt (data build tool) übernimmt den Transformationsschritt in ELT. Nachdem die Rohdaten in Ihr Warehouse geladen wurden, führt dbt SQL-Modelle aus, um sie zu bereinigen, zu verknüpfen und zu analysefertigen Tabellen und Views zu aggregieren. Es nimmt keine Daten auf und ist kein Orchestrator — es transformiert Daten, die bereits im Warehouse liegen.
dbt Core ist das kostenlose, quelloffene Kommandozeilen-Tool, das Sie selbst in Ihrer eigenen Infrastruktur oder CI betreiben. dbt Cloud ist das gehostete kommerzielle Produkt, das einen verwalteten Scheduler, eine IDE, CI-Integrationen und eine gehostete Docs-/Metadaten-Ebene ergänzt. Wir arbeiten mit beiden und helfen Ihnen bei der Auswahl je nach Teamgröße, Governance-Anforderungen und Budget.
Inkrementelle Modelle erstellen bei jedem Lauf nur die neuen oder geänderten Zeilen, statt die gesamte Tabelle neu aufzubauen. Bei großen, anhängelastigen Datensätzen senken sie Warehouse-Kosten und Laufzeit drastisch. Sie erhöhen die Komplexität rund um spät eintreffende Daten und Full Refreshes, daher setzen wir sie dort ein, wo das Volumen es rechtfertigt, und belassen kleinere Modelle als einfache Table- oder View-Materialisierungen.
Mit dbt können Sie Tests deklarieren — generische wie not-null, unique und relationships sowie eigene singuläre Tests —, die bei jedem Build mitlaufen. In Kombination mit Source-Freshness-Prüfungen und Paketen wie dbt_expectations fängt das fehlerhafte Daten ab, bevor sie in Dashboards gelangen. Wir konzipieren eine Test-Suite, die gründlich ist, ohne die Läufe unzumutbar zu verlangsamen.
Das Warehouse (Snowflake, BigQuery usw.) speichert und berechnet die Daten; dbt definiert und führt die SQL-Transformationen darin aus; und ein Orchestrator wie Airflow plant und löst dbt-Läufe neben Ingestion und weiteren Aufgaben aus. dbt selbst plant keine Pipelines — es wird von einem Orchestrator oder vom Scheduler von dbt Cloud aufgerufen.
dbt unterstützt über Adapter alle gängigen Cloud-Warehouses, darunter Snowflake, Google BigQuery, Databricks, Amazon Redshift, Postgres und weitere. Wir stimmen Materialisierungen, Performance und Kosten auf Ihre konkrete Plattform ab, da jeder Adapter seinen eigenen SQL-Dialekt und seine eigenen Optimierungshebel besitzt.
Für einen winzigen Datensatz mit ein oder zwei einfachen Tabellen und ohne echte Transformationslogik können ein paar SQL-Views oder ein schlankes Skript genügen — die Projektstruktur, Tests und CI von dbt bringen einen Overhead mit sich, den Sie vielleicht noch nicht benötigen. dbt zahlt sich aus, sobald Sie mehrere Modelle, mehrere Beitragende, wiederkehrende Qualitätsprobleme oder einen Bedarf an Lineage und Dokumentation haben.
Antwort innerhalb eines Werktags. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.