Consumer-Lag-Akkumulation
Langsame Consumer akkumulieren unbegrenzt Lag lautlos. Wir verdrahten Prometheus-Lag-Exporter, setzen Lag-Alarme und implementieren KEDA-Consumer-Autoscaling.
KRaft Schema Registry MSK SOC 2-ready
Kafka trägt unsere Hochdurchsatz-Event-Pipelines — Scooter Sharings Fahrt-Telemetrie-Stream, der Tausende IoT-Events pro Sekunde verarbeitet, xRoutens Logistik-Event-Bus, Loan Conveyors Audit-Event-Sourcing. MSK auf AWS, Confluent Cloud und selbst gehostete KRaft-Cluster — alle in Produktion für uns.

Wir liefern Kafka Engineering für FinTech-Event-Sourcing, IoT- und Telematik-Ingestion, Microservice-Event-Buses und Change-Data-Capture-Pipelines, die Datenbanken mit nachgelagerten Konsumenten verbinden. Schema Registry hält Producer-Consumer-Verträge über Deployments hinweg sicher. Kafka Connect und Debezium bewegen Daten zwischen Kafka und Datenbanken ohne benutzerdefinierte Pipelines. KRaft eliminiert ZooKeeper für neue Cluster.
Herausforderungen
Langsame Consumer akkumulieren unbegrenzt Lag lautlos. Wir verdrahten Prometheus-Lag-Exporter, setzen Lag-Alarme und implementieren KEDA-Consumer-Autoscaling.
Producer-Schema-Änderungen brechen Consumer auf alten Versionen. Wir erzwingen Schema-Registry-BACKWARD-Kompatibilitätsprüfungen in der CI.
Zu wenige Partitionen begrenzen die Consumer-Parallelität und erzeugen Hotspots. Wir dimensionieren Partitionen zur Designzeit auf die maximale gewünschte Consumer-Nebenläufigkeit.
Häufige Consumer-Neustarts lösen Rebalancing aus, das die Verarbeitung für Sekunden anhält. Wir stimmen session.timeout.ms ab, verwenden kooperatives Sticky Rebalancing und minimieren unnötige Consumer-Neustarts.
At-least-once mit Duplikat-Behandlung ist oft sicherer als transaktionales Exactly-Once. Wir entwerfen idempotente Consumer mit Deduplizierungstabellen, bevor wir Kafka-Transaktionen einsetzen.
Die ZooKeeper-Abhängigkeit fügt ein separates Quorum hinzu, das betrieben werden muss. Wir migrieren zu KRaft-Modus für neue Cluster und planen die ZooKeeper-Entfernung für bestehende.
Lösungen
Domain-Events, die von Producern veröffentlicht und von mehreren nachgelagerten Diensten konsumiert werden — mit DLQ, Retry und Event-Schema-Verträgen.
Debezium Kafka Connect erfasst PostgreSQL- oder MySQL-WAL-Events als Kafka-Topics — für Cache-Invalidierung, Such-Index-Sync und Audit.
Hochfrequente Sensorströme nach Geräte-ID partitioniert, von Stream-Prozessoren konsumiert und in Zeitreihendatenbanken gespeichert.
Unveränderliche Event-Logs für Finanztransaktionen — komprimierte Topics, Exactly-Once-Producer und Audit-Consumer-Groups.
Kafka → S3/BigQuery/Snowflake-Pipelines über Kafka Connect S3 Sink oder benutzerdefinierte Flink-Jobs für Echtzeit-Analytik.
Managed-Kafka-Setup mit Schema Registry, Monitoring, Alerting und IAM/SASL-Authentifizierung ab Tag eins verdrahtet.
Stack
Apache Kafka 3.8, KRaft, Schema Registry, Kafka Connect, Debezium, ksqlDB, AWS MSK, Confluent Cloud, kafka-go, node-kafka (kafkajs), KEDA, Prometheus Kafka exporter.
Compliance
DSGVO-konform · SOC-2-fähig · HIPAA-fähig · PCI-DSS-bewusst
Gemeinsam: TLS + SASL/SCRAM, Schema-Registry-BACKWARD-Kompatibilitätserzwingung, SBOM für Client-Bibliotheken.
Fallstudien
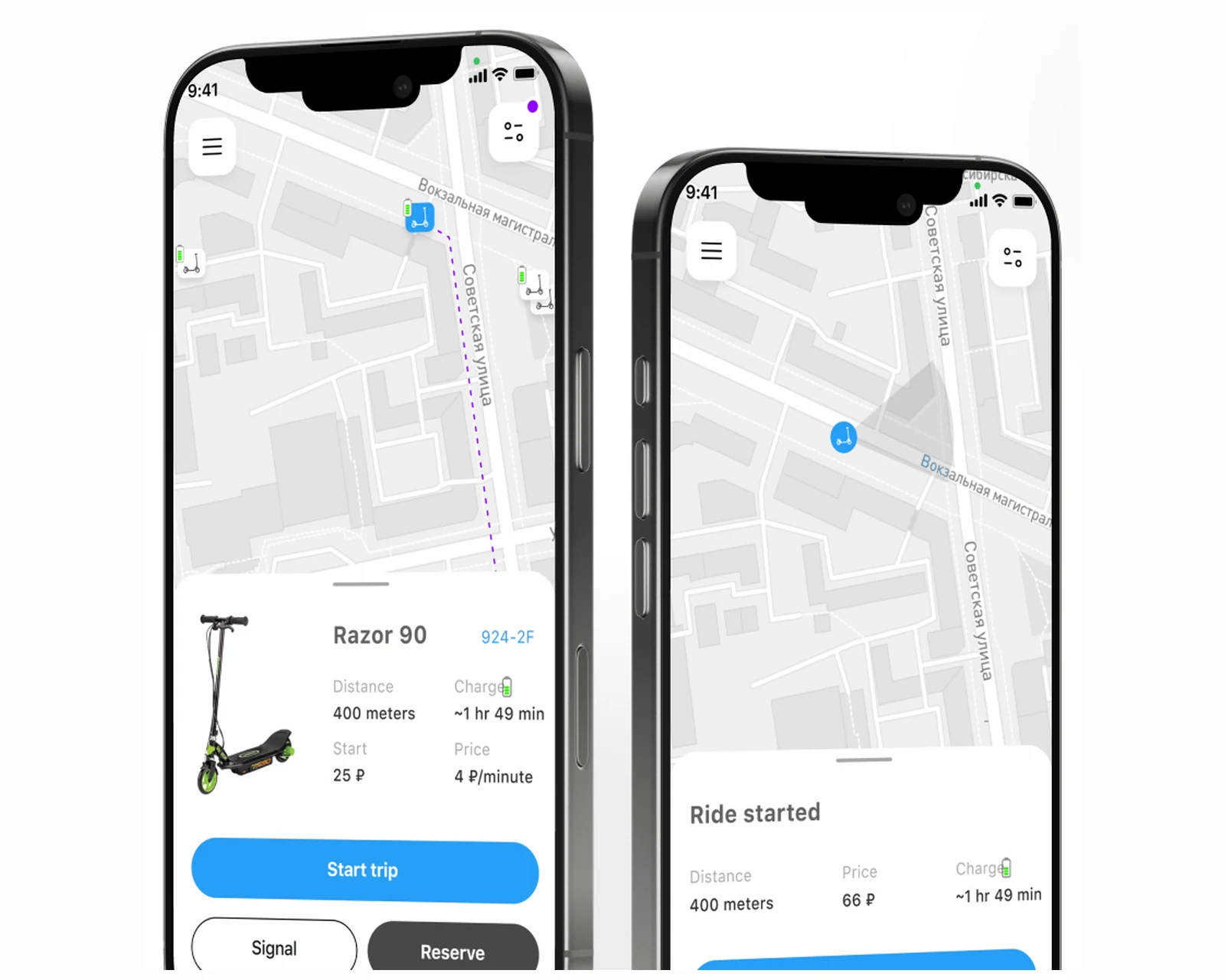
E-Scooter-Sharing-App mit Live-Karte, QR-Entsperr- und Fahrt-Wallet für iOS und Android — 5.000+ Fahrer, für US- & EU-Rollouts gebaut.
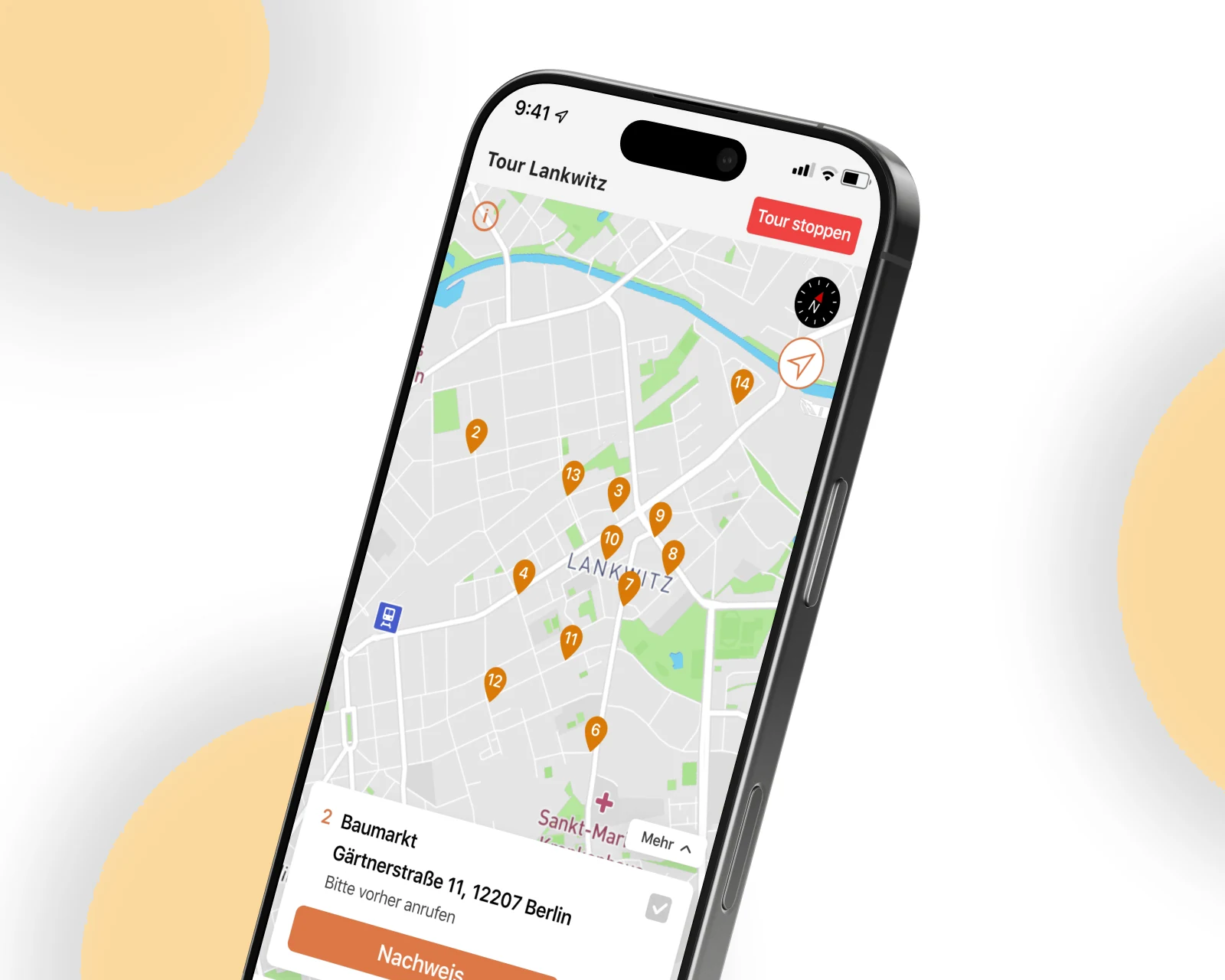
Android + iOS refactor and rebuild for a German last-mile logistics operator — multi-point route planning, real-time driver tracking and in-app invoicing live in the EU.
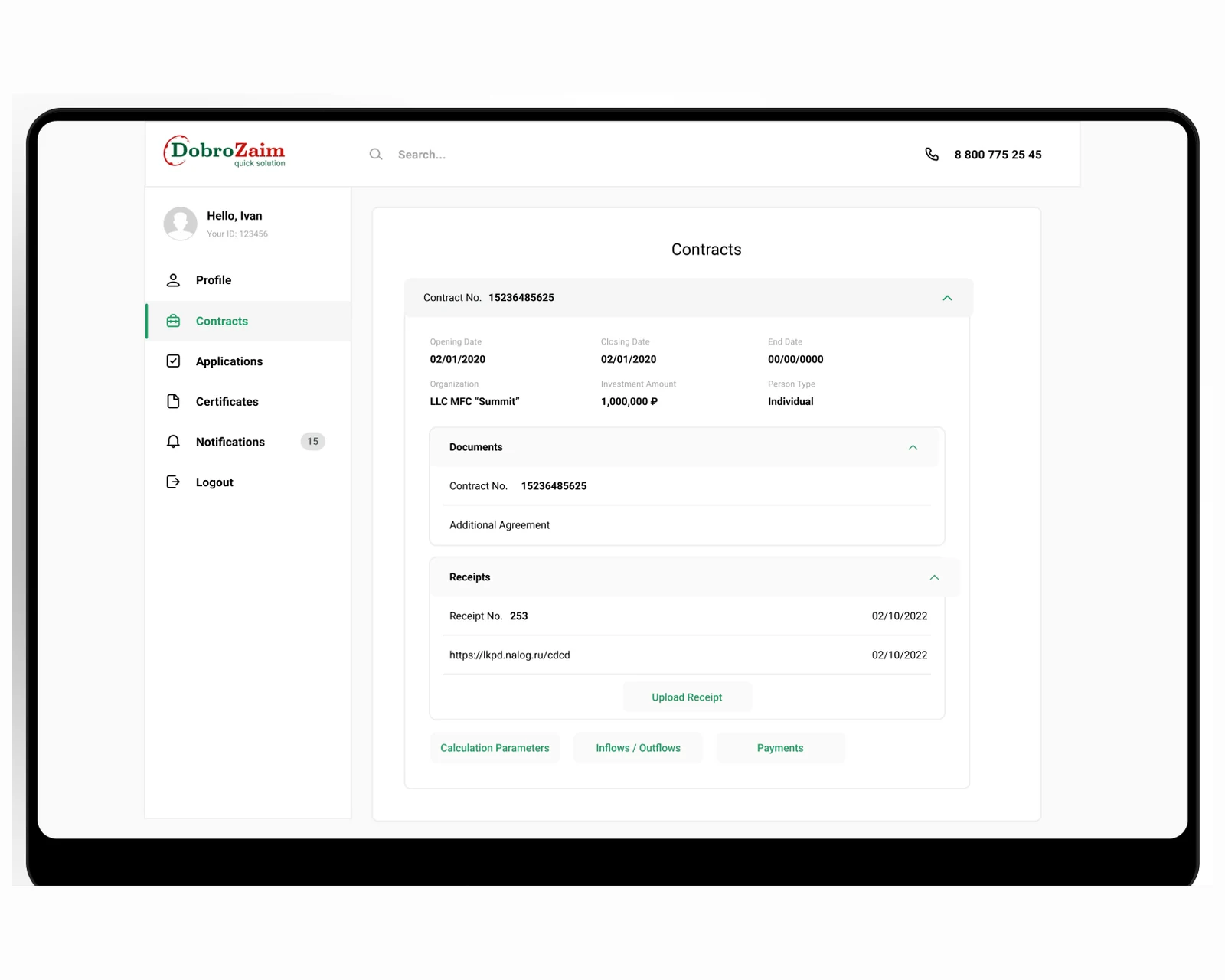
Eine hochdurchsatzfähige Kreditentscheidungs-Engine auf Laravel — automatisiertes Scoring, Kreditbüro-Integration und 10-mal schnellere Entscheidungen für US- und EU-Kreditgeber.
Warum YuSMP
Wir betreiben ZooKeeper-freie KRaft-Kafka-Cluster — der neue Standard für neue Deployments.
Jede Producer-Schema-Änderung durchläuft vor dem Deployment eine Schema-Registry-Kompatibilitätsprüfung in der CI — Consumer erleben nie eine Überraschung.
Consumer-Pods skalieren zwischen Bursts auf null und innerhalb von Sekunden bei Queue-Tiefenwachstum zurück auf Maximum — Kafka-native KEDA-Scaler in unserem Standard-EKS-Setup verdrahtet.
FAQ
Kafka für hoch-durchsatzfähige Multi-Consumer-Pipelines, regionsübergreifende Replikation, langfristige Nachrichtenaufbewahrung und strikte Reihenfolge innerhalb von Partitionen. Redis Streams für leichtgewichtiges Event-Sourcing innerhalb eines einzelnen Rechenzentrums, wo Kafkas Betriebsaufwand nicht gerechtfertigt ist. Kafkas Compacted-Topics und Schema-Registry machen es zur richtigen Wahl, wenn nachgelagerte Consumer Schema-Evolution-Garantien benötigen.
MSK (Amazon Managed Streaming for Kafka) für Teams auf AWS, die Kafka-Betriebsaufwand vermeiden möchten — ZooKeeper in neueren Versionen durch KRaft ersetzt. Confluent Cloud für Teams, die Schema-Registry, ksqlDB und Monitoring ohne eigene Kafka-Infrastruktur wünschen. Self-hosted für Air-gapped- oder On-premises-Umgebungen. Wir betreiben alle drei.
Consumer-Lag-Monitoring mit dem Kafka Consumer Lag Exporter in Prometheus ist nicht verhandelbar. Wir setzen Alerts bei 10.000 Nachrichten Lag für kritische Topics, implementieren Auto-Scaling-Consumer mit KEDA in Kubernetes und gestalten Partition-Anzahlen passend zur maximalen Consumer-Parallelität.
Confluent Schema Registry mit BACKWARD-Kompatibilität als Standardpolicy — neue Schema-Versionen müssen von Consumern der Vorgängerversion lesbar sein. Wir erzwingen Schema-Kompatibilitätsprüfungen in CI vor dem Deployment von Producern. FORWARD-Kompatibilität für Fälle, in denen Consumer zuerst upgraden.
Kafka-Transaktionen (idempotenter Producer + transaktionaler Consumer) für Exactly-Once innerhalb von Kafka. Für systemübergreifendes Exactly-Once (Kafka → Datenbank) verwenden wir das Outbox-Pattern: In derselben Transaktion wie die Geschäftsoperation in eine Datenbank-Outbox-Tabelle schreiben; ein Kafka-Connect-Debezium-Connector liest die CDC-Events aus der Outbox.
TLS für alle Broker-Verbindungen, SASL/SCRAM oder mTLS zur Authentifizierung, ACLs für den Topic-Zugriff pro Consumer-Group und MSK-IAM-Authentifizierung für AWS-verwaltete Deployments. Schema-Registry-Zugriff pro Schema-Subject kontrolliert. Wir auditieren Kafka-ACLs quartalsweise.
Antwort innerhalb eines Werktages. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.