CIS-Benchmark-Lücken
Standard-Kubernetes-Installationen bestehen die meisten CIS-Benchmarks nicht. Wir setzen Cluster mit Pod Security Standards, RBAC Least-Privilege und Netzwerk-Policies auf die Baseline, bevor der erste Workload deployt wird.
EKS / AKS / GKE Argo CD SOC 2-ready Karpenter
Dreiundzwanzig produktive Kubernetes-Cluster verwaltet — ANTs PropTech-Marktplatz auf EKS mit Karpenter, LiMPs Consumer-VPN auf einem gehärteten Cluster, ArgoViews klinische Workstation auf einem AKS-Cluster, der HealthTech-Kontrollen entspricht. GitOps mit Argo CD, Cilium-Netzwerk-Policies, Falco-Runtime-Schutz und PITR-Backup ab Tag eins.

Wir liefern Kubernetes Engineering für Produktteams, die über Single-Server-Deployments hinauswachsen, regulierte Branchen, die Netzwerk-Policy-Isolation und prüfsichere Zugriffskontrollen benötigen, mandantenfähige SaaS-Plattformen mit Namespace- oder vCluster-Isolation und Organisationen, die von Docker Compose oder Nomad migrieren. EKS, AKS und GKE sind alle in Produktion für uns. Argo CD übernimmt GitOps-Deployments. Karpenter übernimmt kosteneffizientes Knoten-Skalieren. Falco und Trivy übernehmen die Runtime-Sicherheit.
Herausforderungen
Standard-Kubernetes-Installationen bestehen die meisten CIS-Benchmarks nicht. Wir setzen Cluster mit Pod Security Standards, RBAC Least-Privilege und Netzwerk-Policies auf die Baseline, bevor der erste Workload deployt wird.
StatefulSets mit dynamischer PVC-Provisionierung über AZs erfordern sorgfältiges Storage-Class-Design. Wir konfigurieren topologiebewusste Provisionierung und PodDisruptionBudgets für sichere Rolling-Updates.
Standard-CPU-basiertes HPA reagiert zu langsam auf Event-Driven-Spitzen. Wir verdrahten KEDA mit Queue-Tiefen-Metriken für Sub-Minuten-Scale-out.
Manuelle Secret-Rotation über Cluster hinweg führt zu Drift und Ausfällen. Wir zentralisieren auf External Secrets Operator, der aus einem einzigen Secrets-Backend abruft.
In-Place-Upgrades auf Produktions-Clustern verursachen Kubelet-Neustarts und potenzielle Pod-Evictions. Wir verwenden Blue-Green-Cluster-Upgrades für zustandslose Workloads und testen Upgrades zuerst in der Staging-Umgebung.
Zu hoch gesetzte Pod-Ressourcen-Requests und -Limits verschwenden Knoten-Kapazität. Wir implementieren OpenCost für Namespace-Kostenzuordnung und Goldilocks für VPA-Empfehlungen.
Lösungen
Produktionsbereites EKS/AKS/GKE mit Karpenter, Argo CD, Cilium, Prometheus-Stack, Falco und CIS-Benchmark-Baseline — in zwei Wochen.
Pod Security Standards, Netzwerk-Policies, RBAC-Audit, Trivy-CI-Scanning, Falco-Runtime-Regeln und CIS-Benchmark-Sanierung.
Migration von kubectl apply oder Helm-CI-Skripten zu Argo-CD-ApplicationSets — vollständiges GitOps mit Rollback, Sync-Status und Slack-Alarmen.
Namespace-RBAC, Netzwerk-Isolation und vCluster-virtuelle Cluster für SaaS-Plattformen mit strikten Mandanten-Trennungsanforderungen.
OpenCost-Namespace-Kostenberichte, Karpenter-Spot-Konsolidierung, Goldilocks-VPA-Empfehlungen und Cluster-Bin-Packing-Audits.
Blue-Green-Cluster-Upgrades, Namespace-Migrations-Playbooks und Versions-Upgrade-Pfad-Dokumentation mit Rollback-Verfahren.
Stack
Kubernetes 1.31, EKS, AKS, GKE, Helm, Argo CD, Karpenter, Cilium, Istio, kube-prometheus-stack, OpenTelemetry, Falco, Trivy, External Secrets Operator, OpenCost.
Compliance
DSGVO-konform · SOC-2-fähig · HIPAA-berechtigt · PCI-DSS-bewusst
Gemeinsam: CIS-Kubernetes-Benchmark, SBOM über Trivy SBOM, SLSA-Lieferketten-Kontrollen.
Fallstudien
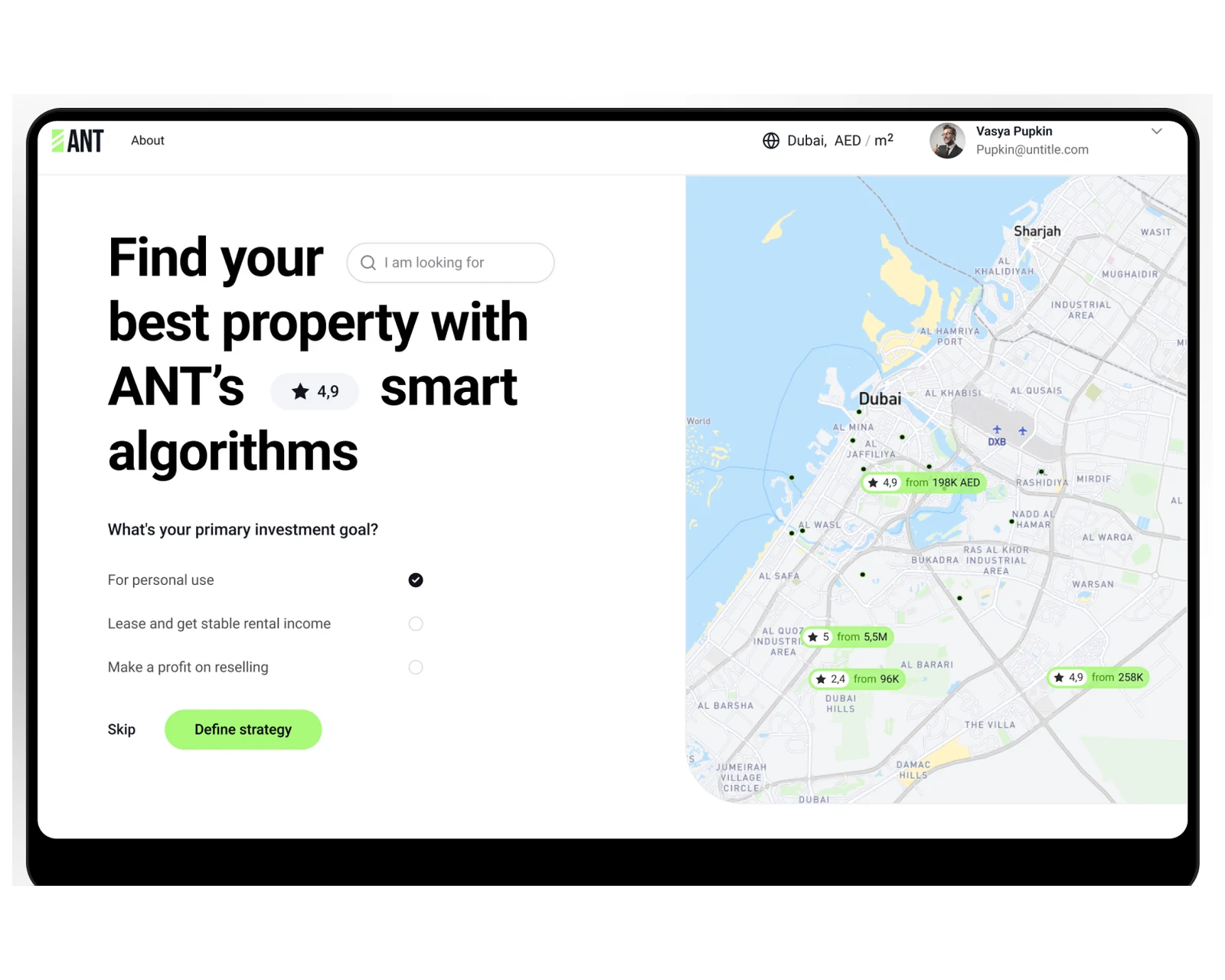
Immobilien-Marktplatz-Webplattform mit Listing-CMS, Suchfunktion und B2B-Admin-Konsole für US- und EU-Betreiber.
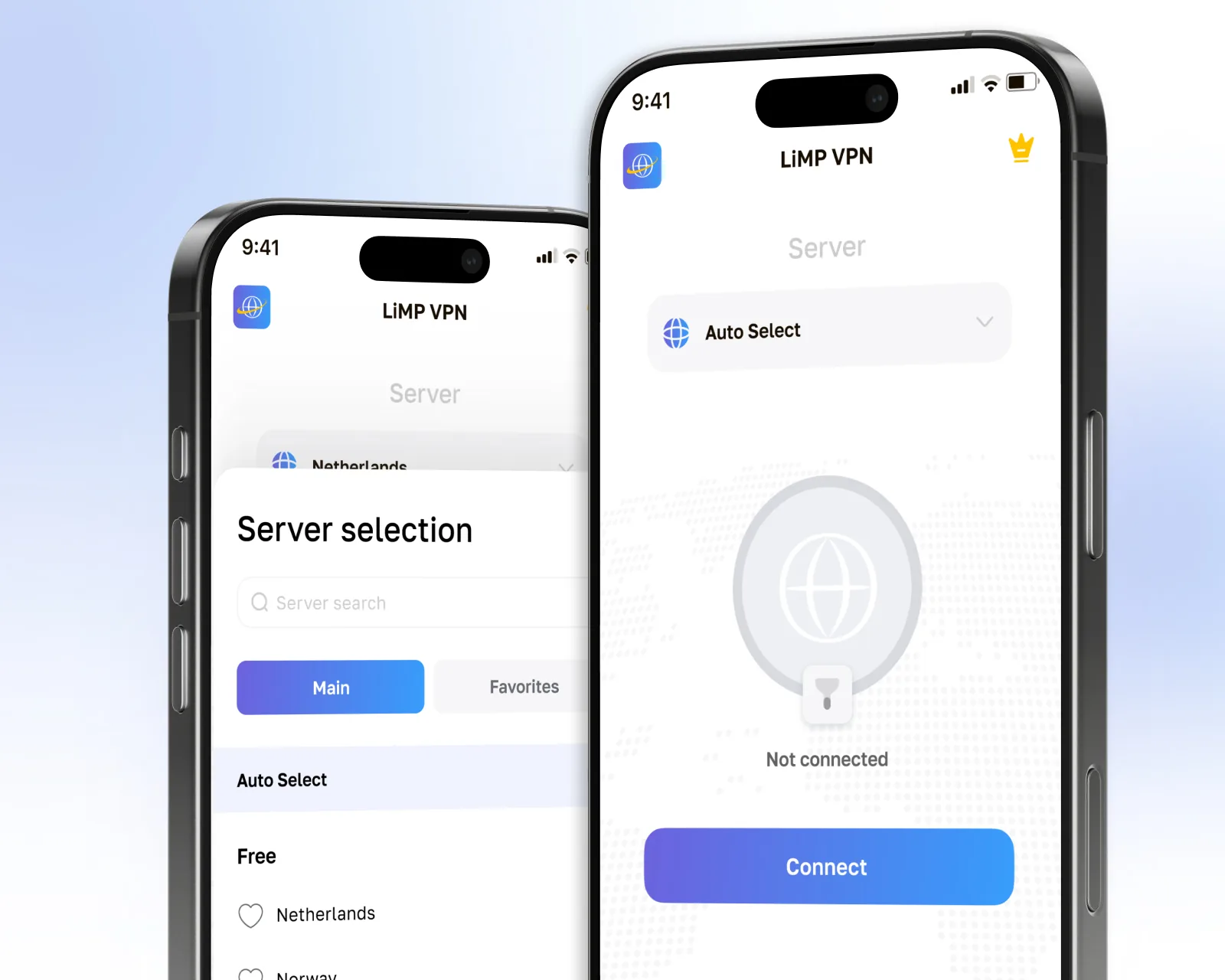
Consumer-WireGuard-VPN-App für iOS und Android mit Zero-Log-Architektur, veröffentlicht in den USA und der EU.
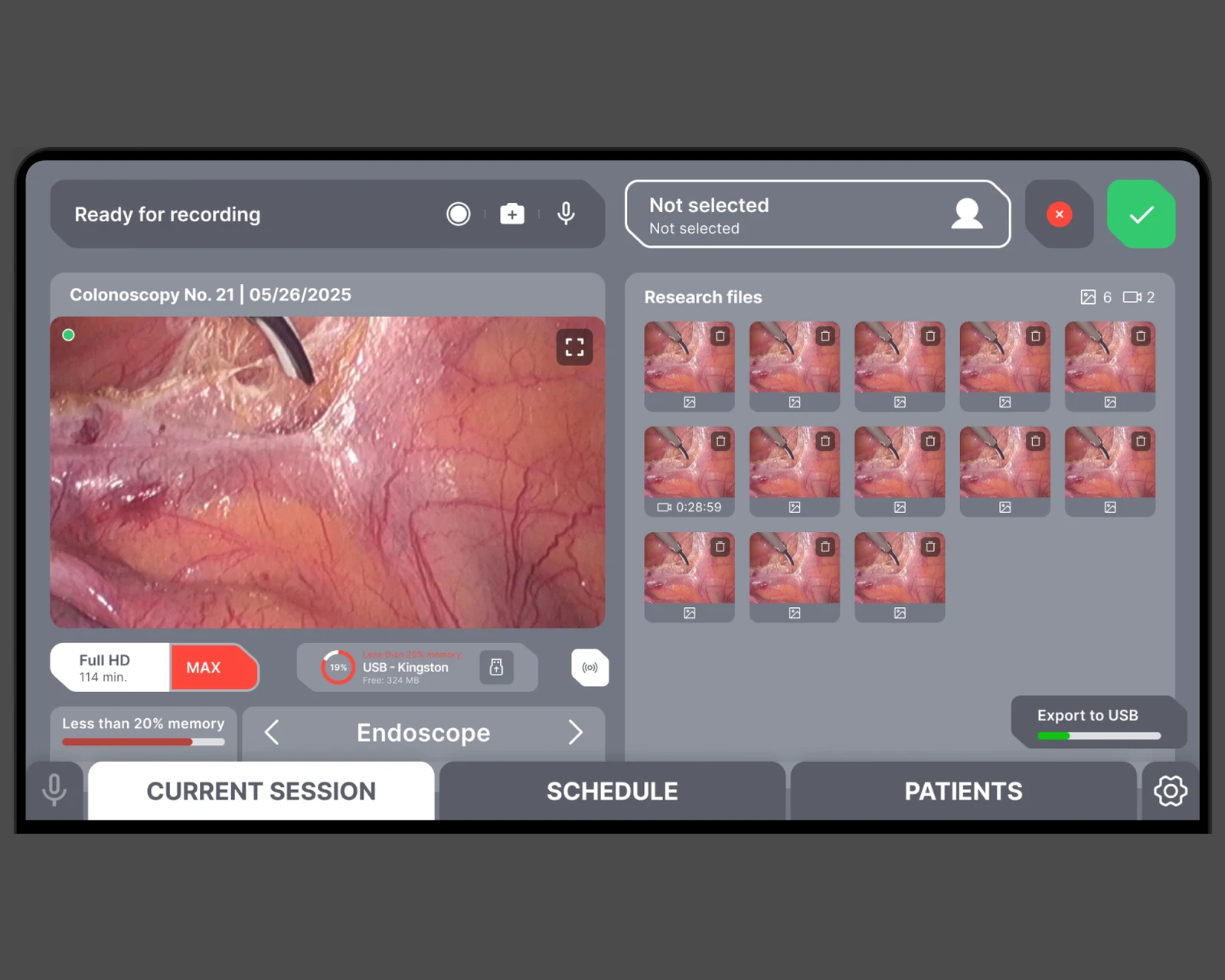
Tablet-first-Endoskopie-Aufzeichnung, Patientenakten und DICOM/HL7-Export — auf Laravel + React mit WebRTC-Erfassung im Browser für US- und EU-Kliniken.
Warum YuSMP
Wir liefern keine Kubernetes-Cluster ohne CIS-Benchmark-Baseline. Pod Security Standards, Netzwerk-Policies und RBAC Least-Privilege sind Teil des initialen Cluster-Setups, kein nachträglicher Audit-Retrofit.
OpenCost-Namespace-Kostenberichte, Karpenter-Spot-Konsolidierung und Goldilocks-VPA-Empfehlungen — Kostensichtbarkeit ab dem ersten Sprint.
Kein Mensch berührt die Produktion mit kubectl apply. Argo-CD-ApplicationSets, Diff-Previews und Ein-Klick-Rollback — jede Änderung ist ein Git-Commit mit Review.
FAQ
EKS, wenn Ihre primäre Cloud AWS ist — beste IAM-Integration mit IRSA, größtes Tooling-Ökosystem. AKS für Azure-zentrierte Organisationen mit Entra ID (AAD) Integrationsanforderungen. GKE Autopilot für Teams, die ein möglichst wartungsarmes Cluster-Management bevorzugen. Wir entwickeln cloud-agnostische Workloads, wenn Portabilität eine explizite Anforderung ist.
Argo CD ist unser Standard — UI, ApplicationSets, App-of-Apps-Muster, RBAC und Slack-Benachrichtigungen. Flux für Teams mit bestehenden Flux-Investitionen oder starker Präferenz für das GitOps-Operator-Modell. Beide Tools erzielen dasselbe Ergebnis; die Wahl ist weniger wichtig als Konsistenz.
External Secrets Operator zieht aus AWS Secrets Manager, Azure Key Vault oder HashiCorp Vault — niemals Secrets in Git, auch nicht verschlüsselt. Wir implementieren auch Sealed Secrets für Teams, die Git-gespeicherte verschlüsselte Secrets ohne Cloud-Secrets-Backend-Abhängigkeit benötigen.
Wir setzen jeden Cluster gegen den CIS-Kubernetes-Benchmark auf Baseline: Pod Security Standards, Netzwerk-Policies (Cilium), RBAC Least-Privilege, Audit-Logging, Falco-Runtime-Bedrohungserkennung und Trivy-Image-Scanning in CI. Cluster-Sicherheitsbefunde werden im selben Sprint wie Feature-Arbeit verfolgt.
HPA auf benutzerdefinierten Metriken (KEDA event-driven) für Queue-Consumer, kombiniert mit Karpenter für Scale-out auf Knotenebene. Wir modellieren das Cold-Start-Latenzbudget und wählen zwischen Überprovisionierung (schnelle Reaktion) und Zero-to-Burst (kosteneffizient) basierend auf Ihrem SLA.
Namespace-pro-Mandant mit Netzwerk-Policies und RBAC für moderate Isolation. vCluster-virtuelle Cluster für Teams, die eine stärkere API-Server-Isolation ohne die Kosten dedizierter Cluster benötigen. Dedizierte Cluster für regulierte Mandanten, bei denen die Compliance-Grenze ein Cluster sein muss.
Blue-Green-Cluster-Upgrades für zustandslose Workloads — neuer Cluster, Namespaces migrieren, alten entkoppeln. Rolling-Node-Upgrades mit PodDisruptionBudgets für zustandsbehaftete Workloads. Wir testen den Upgrade-Pfad in der Staging-Umgebung mit produktionsähnlicher Last, bevor wir die Produktion anrühren.
Antwort innerhalb eines Werktages. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.