Den richtigen Index wählen
HNSW oder IVFFlat? Die falsche Wahl von Indextyp und dessen Parametern (m, ef_construction, lists, probes) führt zu langsamen Builds, aufgeblähtem Speicher oder schlechtem Recall.
pgvector PostgreSQL HNSW Vektorsuche
Wir unterstützen Teams in den USA und der EU dabei, PostgreSQL mit der pgvector-Erweiterung um produktionsreife Vektorähnlichkeitssuche zu ergänzen — ohne separate Vektordatenbank, die bereitgestellt, abgesichert oder bezahlt werden muss. Ihre Embeddings liegen direkt neben den relationalen Zeilen, die sie beschreiben, sodass Hybridabfragen, Joins und Zugriffskontrolle in einer Engine bleiben, die Sie bereits betreiben. Vom Index-Tuning bis zu vollständigen RAG-Backends machen wir pgvector schnell, präzise und wartungsfreundlich.

Wir unterstützen Teams in den USA und der EU dabei, PostgreSQL mit der pgvector-Erweiterung um produktionsreife Vektorähnlichkeitssuche zu ergänzen — ohne separate Vektordatenbank, die bereitgestellt, abgesichert oder bezahlt werden muss. Ihre Embeddings liegen direkt neben den relationalen Zeilen, die sie beschreiben, sodass Hybridabfragen, Joins und Zugriffskontrolle in einer Engine bleiben, die Sie bereits betreiben. Vom Index-Tuning bis zu vollständigen RAG-Backends machen wir pgvector schnell, präzise und wartungsfreundlich.
Herausforderungen
HNSW oder IVFFlat? Die falsche Wahl von Indextyp und dessen Parametern (m, ef_construction, lists, probes) führt zu langsamen Builds, aufgeblähtem Speicher oder schlechtem Recall.
Approximative Suche tauscht Genauigkeit gegen Geschwindigkeit. Diesen Kompromiss für Ihre Daten und Abfragelast abzustimmen, ist nicht trivial und leicht falsch zu machen.
Millionen hochdimensionaler Vektoren belasten Speicher und Index-Build-Zeiten; ohne Partitionierungs- und Dimensionierungsstrategie bricht die Performance abrupt ein.
Reale Abfragen kombinieren Vektorähnlichkeit mit SQL-Filtern, Joins und Volltextsuche. Naive Pläne scannen alles und ignorieren Ihre Indizes.
Der Wechsel von Embedding-Modell oder Dimension entwertet gespeicherte Vektoren, und stiller Modell-Drift verschlechtert die Retrieval-Qualität mit der Zeit unbemerkt.
Embeddings müssen aktualisiert werden, wenn sich Quellzeilen ändern. Ohne zuverlässige Pipeline veraltet Ihr Index und liefert falsche Ergebnisse.
Lösungen
Wir installieren und konfigurieren pgvector, wählen je Workload HNSW oder IVFFlat und tunen die Indexparameter gegen Ihre realen Daten für den Recall und die Geschwindigkeit, die Sie benötigen.
Wir schreiben Abfragen, die Ähnlichkeitssuche mit SQL-Filtern, Joins und Volltext verbinden, mit Abfrageplänen, die Ihre Indizes tatsächlich nutzen.
Wir bauen Retrieval-Augmented-Generation-Backends — Chunking, Embedding, Retrieval und Re-Ranking — vollständig auf Ihrem PostgreSQL mit LlamaIndex oder LangChain.
Wir dimensionieren den Speicher, partitionieren große Tabellen und benchmarken Index-Builds, damit die Vektorsuche schnell bleibt, während Ihr Korpus wächst.
Wir bauen Pipelines, die bei Änderungen von Quellzeilen automatisch neu embeddings erzeugen und neu indexieren, sodass Vektoren konsistent mit Ihren Daten bleiben.
Wir migrieren Workloads von eigenständigen Vektordatenbanken wie Pinecone oder Qdrant nach pgvector und führen zwei Datenspeicher zu einem zusammen.
Stack
pgvector, PostgreSQL, HNSW- & IVFFlat-Indizes, Embeddings, Supabase/Aurora/Cloud SQL, SQLAlchemy, LlamaIndex/LangChain, Docker.
Compliance
DSGVO · Datenresidenz · HIPAA-fähig · SOC 2
Fallstudien
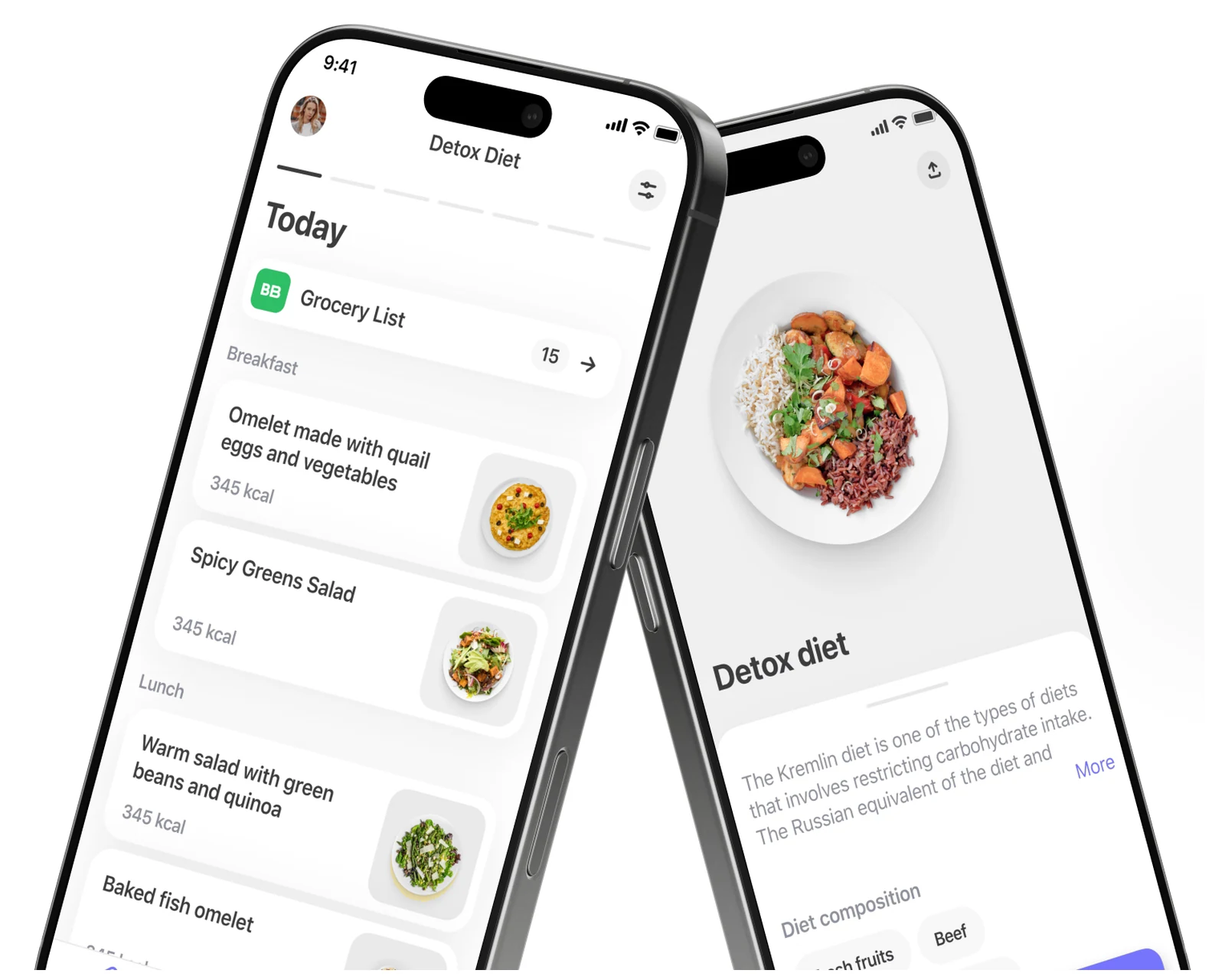
Plattformübergreifende App für Ernährung und Mahlzeitenplanung auf Flutter — Kalorien-Engine, Rezeptbibliothek, Wochen-Mahlzeitenplan, Lebensmittelbestellung.

Plattformübergreifende Sport-News-App und Web-Portal — Telegram-Bot-CMS statt eines eigenen Admin-Bereichs, Markdown-Publishing-Pipeline.
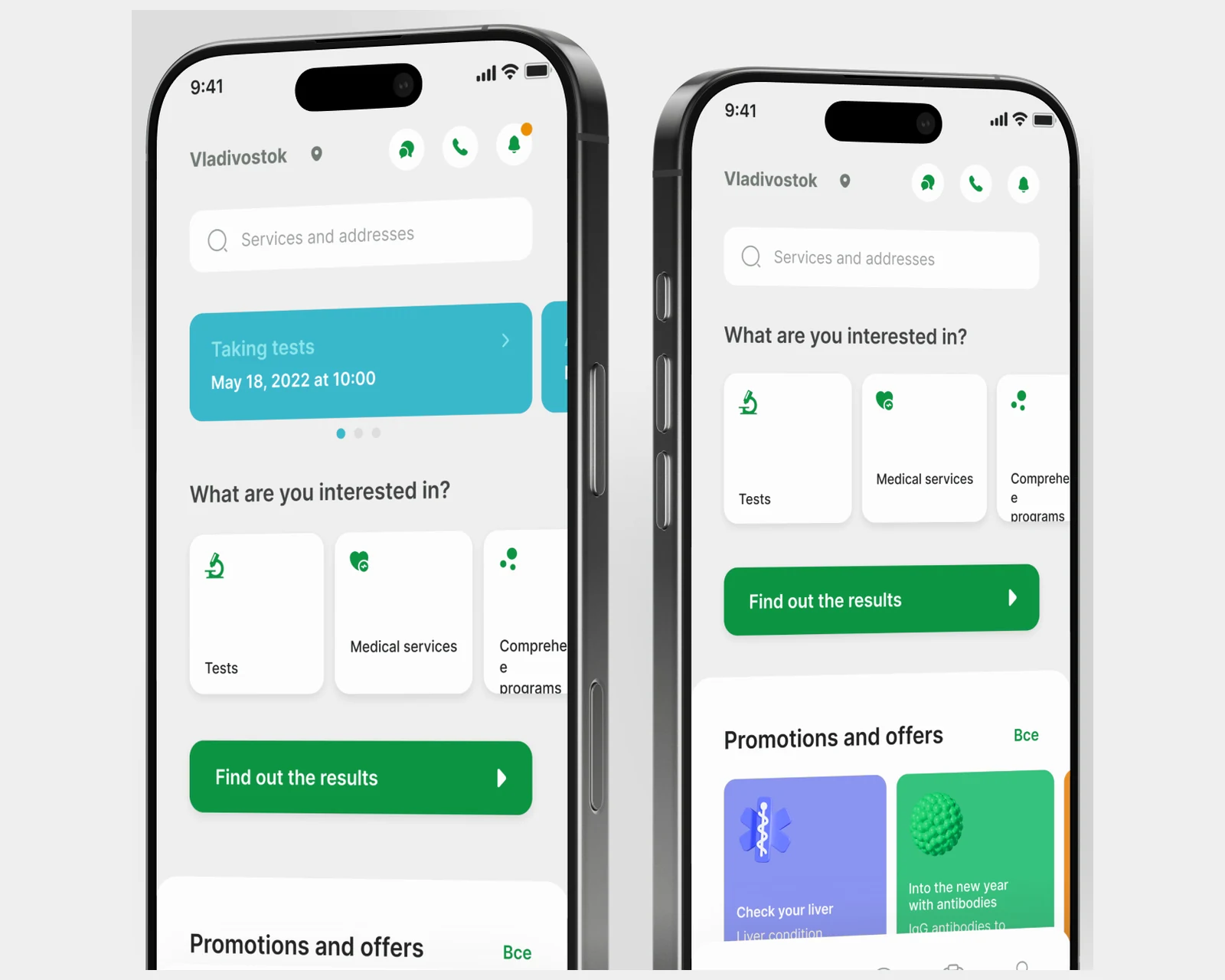
Patienten-App für ein Labornetz in 40 Städten — Terminbuchung, digitale Befunde, 2.500+ Tests, Integrationen für Terminplanung und Buchhaltung.
Warum YuSMP
Ihre Vektoren bleiben in dem PostgreSQL, das Sie ohnehin betreiben, sichern und absichern — keine separate Vektordatenbank, die bereitgestellt, überwacht oder bezahlt werden muss, und nur eine Engine, mit der Sie sich befassen.
Wir tunen Indizes, Speicher und Abfragepläne gegen Ihre realen Daten und Last, nicht gegen Standardwerte, sodass Recall und Latenz Ihre Ziele im Produktivbetrieb erreichen.
Für Kunden in den USA und der EU halten wir Embeddings regulierter Daten in Ihrer konformen Region — mit den Zugriffskontrollen, dem Logging und den Löschpfaden, die Auditoren erwarten.
FAQ
Wenn Ihre Daten ohnehin in PostgreSQL liegen, ermöglicht pgvector, die Embeddings direkt daneben zu halten — Hybridabfragen, Joins, Transaktionen, Backups und Zugriffskontrolle bleiben alle in einer Engine. Das spart einen kompletten Datenspeicher, den Sie sonst betreiben, absichern und bezahlen müssten. Dedizierte Vektordatenbanken rechtfertigen sich bei sehr großem Maßstab oder mit spezialisierten Funktionen, doch die meisten Teams erreichen diese Grenzen später, als sie erwarten.
HNSW liefert hohe Recall-Werte und schnelle Abfragen bei langsameren, speicherhungrigeren Builds und ist die Standardwahl für die meisten leselastigen Workloads. IVFFlat baut schneller und benötigt weniger Speicher, erfordert aber abgestimmte lists und probes und reagiert empfindlicher auf die Datenverteilung. Wir benchmarken beide auf Ihren Daten, bevor wir uns festlegen.
pgvector verarbeitet auf einer ausreichend dimensionierten Instanz problemlos Millionen von Vektoren und mit Partitionierung und sorgfältigem Speicher-Tuning auch zehn Millionen. Darüber hinaus werden Index-Build-Zeit, RAM und Abfragelatenz zum limitierenden Faktor — wir benchmarken Ihren Korpus, um die reale Obergrenze zu finden, bevor Sie an sie stoßen.
Ja — das ist einer der Hauptgründe, pgvector einzusetzen. Wir schreiben Hybridabfragen, die Ähnlichkeitssuche mit WHERE-Filtern, Joins und Volltextsuche verbinden, und stimmen den Abfrageplan so ab, dass sowohl der Vektorindex als auch Ihre relationalen Indizes effizient genutzt werden.
Wir tunen Indexparameter (ef_search für HNSW, probes für IVFFlat) und messen den Recall gegen eine Exact-Search-Baseline auf Ihren Daten. Sie geben das Ziel vor — beispielsweise 95 % Recall innerhalb eines Latenzbudgets — und wir tunen, bis es erreicht ist, und dokumentieren dann die Einstellungen.
Wir bauen eine Embedding-Pipeline, die geänderte Quellzeilen erkennt — über Trigger, Change-Data-Capture oder eine Queue — sie neu embeddet und den Index aktualisiert, damit Ihre Vektoren niemals von den Zeilen abweichen, die sie beschreiben.
Wenn Index-Builds, RAM oder Abfragelatenz selbst nach Tuning und Partitionierung die Ziele nicht mehr erreichen oder wenn Sie Funktionen benötigen, die pgvector fehlen. Wir sagen Ihnen ehrlich, wann dieser Punkt erreicht ist, und planen eine Migration zu einer dedizierten Vektordatenbank, wobei wir die bereits gebaute Embedding-Pipeline weiterverwenden.
Antwort innerhalb von 1 Werktag. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.