Choosing the right index
HNSW or IVFFlat? Picking the index type and its parameters (m, ef_construction, lists, probes) wrong means slow builds, bloated memory or poor recall.
pgvector PostgreSQL HNSW Vector Search
We help US and EU teams add production-grade vector similarity search to PostgreSQL with the pgvector extension — no separate vector database to provision, secure or pay for. Your embeddings live next to the relational rows they describe, so hybrid queries, joins and access control stay in one engine you already operate. From index tuning to full RAG backends, we make pgvector fast, accurate and easy to maintain.

We help US and EU teams add production-grade vector similarity search to PostgreSQL with the pgvector extension — no separate vector database to provision, secure or pay for. Your embeddings live next to the relational rows they describe, so hybrid queries, joins and access control stay in one engine you already operate. From index tuning to full RAG backends, we make pgvector fast, accurate and easy to maintain.
Challenges
HNSW or IVFFlat? Picking the index type and its parameters (m, ef_construction, lists, probes) wrong means slow builds, bloated memory or poor recall.
Approximate search trades accuracy for speed. Tuning that trade-off for your data and query load is non-obvious and easy to get wrong.
Millions of high-dimension vectors strain memory and index build times; without partitioning and sizing strategy, performance falls off a cliff.
Real queries combine vector similarity with SQL filters, joins and full-text search. Naive plans scan everything and ignore your indexes.
Changing the embedding model or dimension invalidates stored vectors, and silent model drift quietly degrades retrieval quality over time.
Embeddings must update when source rows change. Without a reliable pipeline, your index goes stale and returns wrong results.
Solutions
We install and configure pgvector, choose HNSW or IVFFlat per workload, and tune index parameters against your real data for the recall and speed you need.
We write queries that blend similarity search with SQL filters, joins and full-text, with query plans that actually use your indexes.
We build retrieval-augmented generation backends — chunking, embedding, retrieval and re-ranking — entirely on your PostgreSQL with LlamaIndex or LangChain.
We size memory, partition large tables and benchmark index builds so vector search stays fast as your corpus grows.
We build pipelines that re-embed and re-index automatically when source rows change, keeping vectors consistent with your data.
We migrate workloads off standalone vector databases like Pinecone or Qdrant into pgvector, collapsing two datastores into one.
Stack
pgvector, PostgreSQL, HNSW & IVFFlat indexes, embeddings, Supabase/Aurora/Cloud SQL, SQLAlchemy, LlamaIndex/LangChain, Docker.
Compliance
GDPR · data residency · HIPAA-ready · SOC 2
Cases
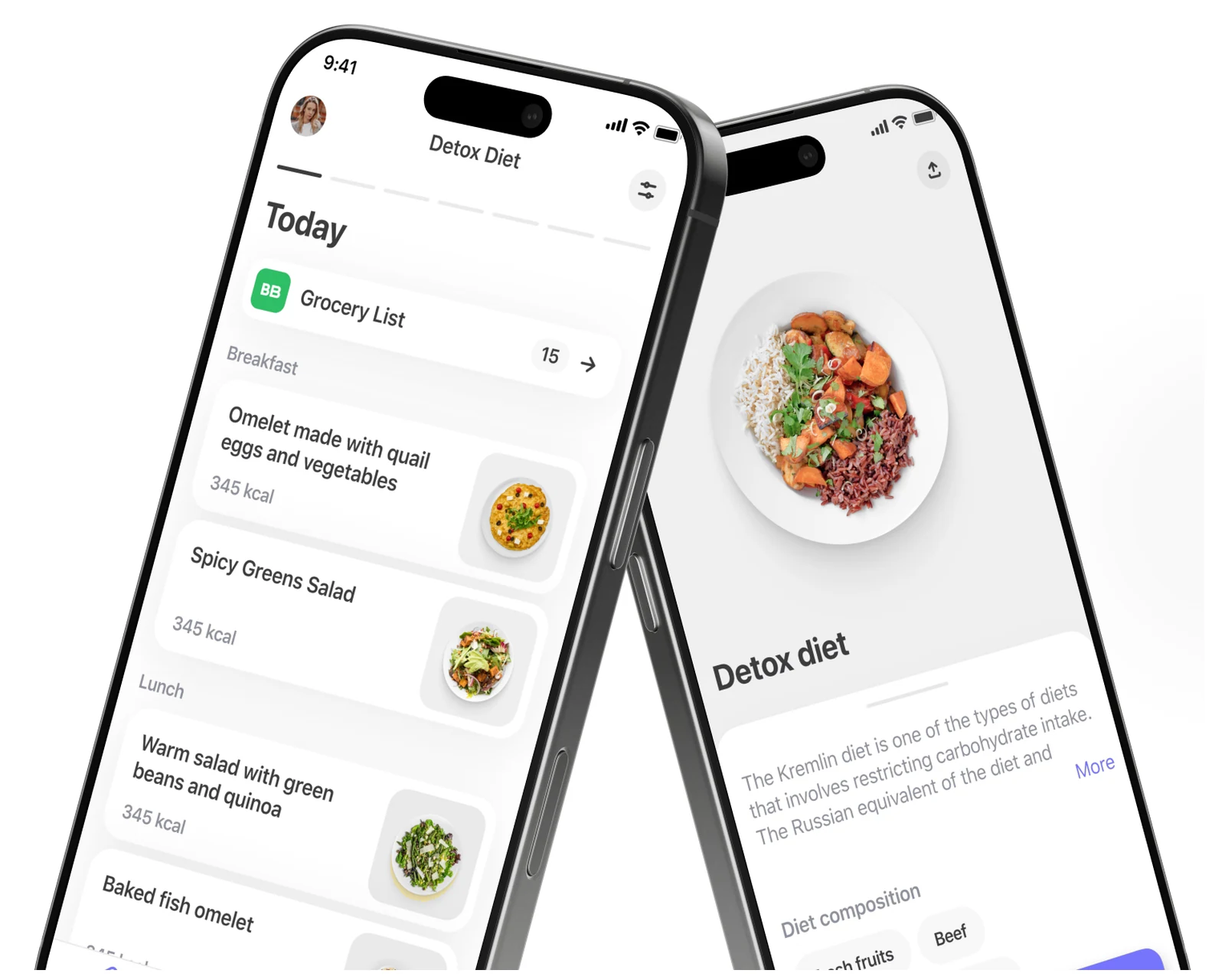
Cross-platform diet and meal-planning app on Flutter — calorie engine, recipe library, weekly meal-plan, grocery ordering.

Cross-platform sports news app and web portal — Telegram-bot CMS instead of a custom admin, Markdown publishing pipeline.
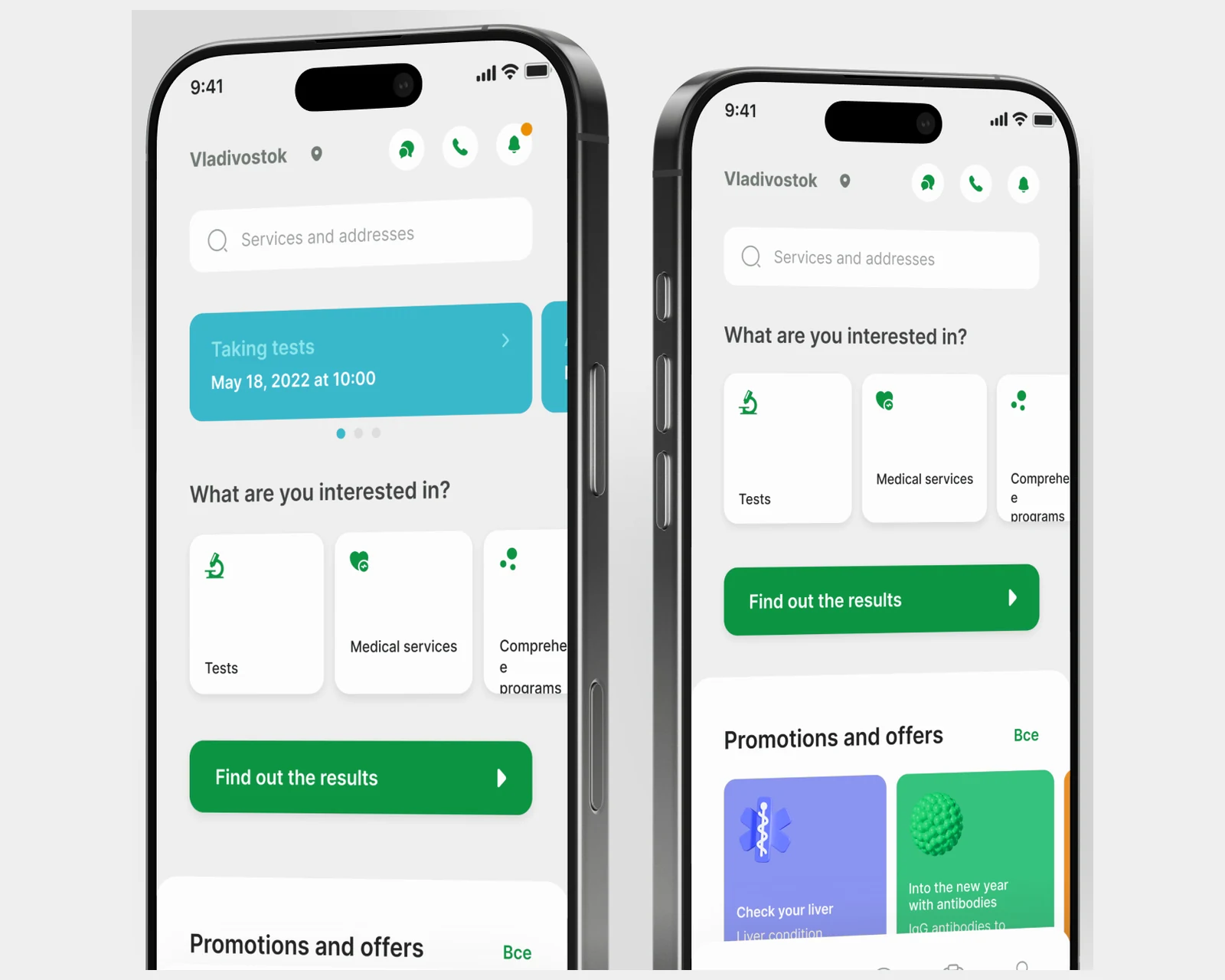
Patient app for a 40-city lab network — appointment booking, digital results, 2,500+ tests, scheduling and accounting integrations.
Why YuSMP
Your vectors stay in the PostgreSQL you already run, back up and secure — no separate vector database to provision, monitor or pay for, and one engine to reason about.
We tune indexes, memory and query plans against your real data and load, not defaults, so recall and latency meet your targets in production.
For US and EU clients we keep embeddings of regulated data inside your compliant region, with the access controls, logging and erasure paths auditors expect.
FAQ
If your data already lives in PostgreSQL, pgvector lets you keep embeddings beside it — hybrid queries, joins, transactions, backups and access control all stay in one engine. That removes an entire datastore to operate, secure and pay for. Dedicated vector databases earn their keep at very large scale or with specialised features, but most teams reach those limits later than they expect.
HNSW gives high recall and fast queries with slower, more memory-hungry builds, and is the default choice for most read-heavy workloads. IVFFlat builds faster and uses less memory but needs tuned lists and probes and is more sensitive to data distribution. We benchmark both on your data before committing.
pgvector comfortably handles millions of vectors on a well-sized instance, and tens of millions with partitioning and careful memory tuning. Beyond that, index build time, RAM and query latency become the constraints — we benchmark your corpus to find the real ceiling before you hit it.
Yes — that is a core reason to use pgvector. We write hybrid queries that mix similarity search with WHERE filters, joins and full-text search, and tune the query plan so both the vector index and your relational indexes are used efficiently.
We tune index parameters (ef_search for HNSW, probes for IVFFlat) and measure recall against an exact-search baseline on your data. You set the target — for example 95% recall under a latency budget — and we tune to meet it, then document the settings.
We build an embedding pipeline that detects changed source rows — via triggers, change-data-capture or a queue — re-embeds them and updates the index, so your vectors never drift out of sync with the rows they describe.
When index builds, RAM or query latency stop meeting targets even after tuning and partitioning, or when you need features pgvector lacks. We will tell you honestly when that point arrives and plan a migration to a dedicated vector database, reusing the embedding pipeline we already built.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.