Training-Serving-Skew
Features, die in Notebooks und in der Produktion unterschiedlich berechnet werden, verschlechtern still und leise die Live-Genauigkeit, und ohne gemeinsame Transformationen ist diese Drift schwer zu erkennen.
PyTorch Deep Learning MLOps ONNX
Wir entwickeln, trainieren und liefern PyTorch-Modelle, die den Kontakt mit der Produktion überstehen. Von Datenpipelines und verteiltem GPU-Training bis hin zu latenzarmen Inferenz-APIs decken unsere Entwickler den gesamten Lebenszyklus ab. Teams in den USA und der EU verlassen sich auf uns, um Research-Notebooks in gesteuerte, überwachte Services zu verwandeln — nicht in einmalige Experimente. Jedes Deployment ist reproduzierbar, beobachtbar und von Grund auf konform.

Wir entwickeln, trainieren und liefern PyTorch-Modelle, die den Kontakt mit der Produktion überstehen. Von Datenpipelines und verteiltem GPU-Training bis hin zu latenzarmen Inferenz-APIs decken unsere Entwickler den gesamten Lebenszyklus ab. Teams in den USA und der EU verlassen sich auf uns, um Research-Notebooks in gesteuerte, überwachte Services zu verwandeln — nicht in einmalige Experimente. Jedes Deployment ist reproduzierbar, beobachtbar und von Grund auf konform.
Herausforderungen
Features, die in Notebooks und in der Produktion unterschiedlich berechnet werden, verschlechtern still und leise die Live-Genauigkeit, und ohne gemeinsame Transformationen ist diese Drift schwer zu erkennen.
Nicht erfasste Runs, Zufalls-Seeds und Datenversionen machen Ergebnisse Monate später unmöglich reproduzierbar oder auditierbar.
Ungenutzte GPUs, überdimensionierte Instanzen und naives verteiltes Training verbrennen still das Budget, während Jobs trotzdem zu lange dauern.
Ohne Live-Metriken und Drift-Erkennung verfallen Modelle angesichts sich verschiebender Daten, und niemand bemerkt es, bis Nutzer sich beschweren.
Modelle in Research-Qualität sind oft zu schwer, um sie ohne ONNX-Export, Quantisierung oder Distillation mit der Ziel-Latenz und zu den Zielkosten auszuliefern.
Personenbezogene Daten gelangen in Trainingskorpora, verletzen DSGVO und CCPA und erzeugen Modelle, die Löschanfragen nicht erfüllen können.
Lösungen
Wir bauen reproduzierbare PyTorch- und Lightning-Trainingspipelines mit gemeinsamen Feature-Transformationen, verteiltem Multi-GPU-Support über Ray und versionierten Daten.
MLflow erfasst Parameter, Metriken, Artefakte und Lineage für jeden Run, sodass Ergebnisse vergleichbar, reproduzierbar und audit-fähig sind.
Wir stellen Modelle über TorchServe oder FastAPI mit Batching, Autoscaling und Health-Checks hinter sauberen, versionierten Endpunkten bereit.
ONNX-Export, Quantisierung und Distillation reduzieren Modellgröße und Latenz, damit Sie Ihre Kosten- und SLA-Ziele auf CPU oder GPU erreichen.
Automatisiertes Retraining, Evaluierungs-Gates und Deployment laufen über CI/CD, mit Live-Monitoring von Drift, Latenz und Qualität in der Produktion.
Wir verfolgen die Herkunft von Datensätzen, setzen PII-Kontrollen durch und integrieren Löschvorgänge in die Pipelines, damit Modelle den EU- und US-Vorschriften entsprechen.
Stack
PyTorch, Lightning, TorchServe, ONNX, CUDA, Hugging Face, MLflow, Ray, FastAPI, Docker, Kubernetes.
Compliance
EU-KI-Verordnung · DSGVO-Trainingsdaten · Modell-Governance · SOC 2
Fallstudien

Plattformübergreifende Sport-News-App und Webportal — Telegram-Bot-CMS statt eines individuellen Admin-Bereichs, Markdown-Publishing-Pipeline.
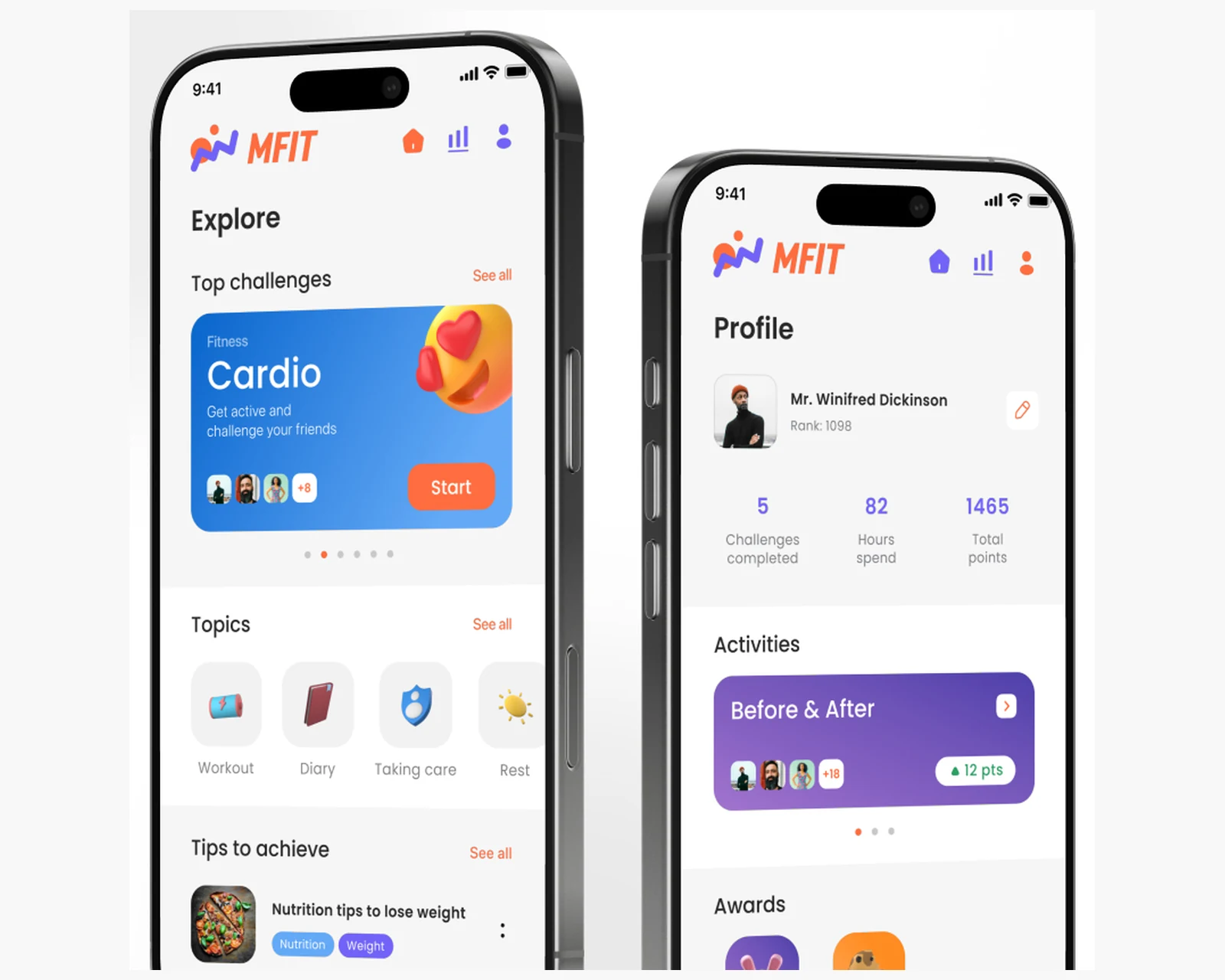
Native iOS- & Android-App für Fitness-Marathons und Challenges — Programme, Statistiken und Bestenlisten auf einem Laravel-Backend, für die USA & EU.
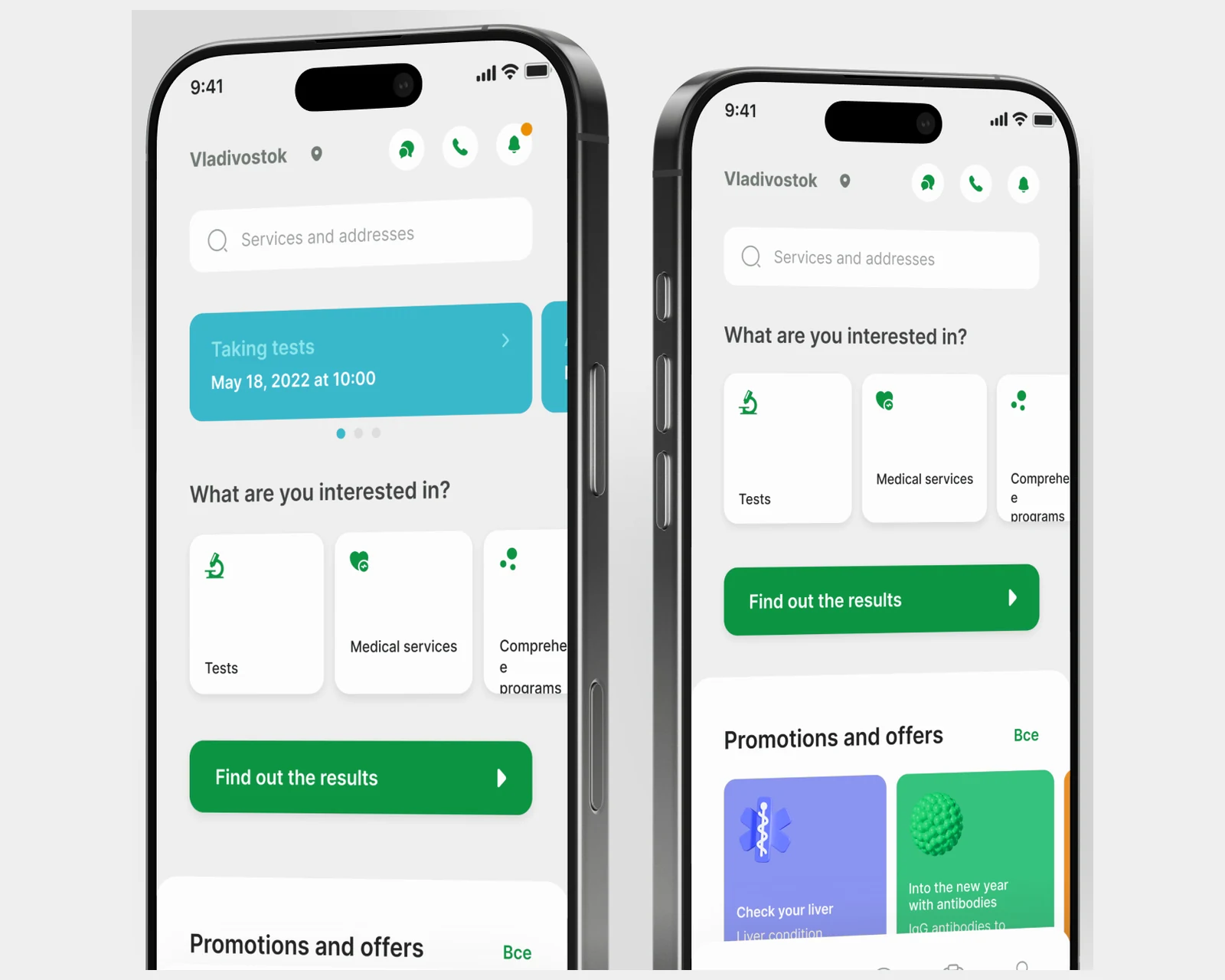
Patienten-App für ein Labornetz in 40 Städten — Terminbuchung, digitale Befunde, 2.500+ Tests, Integrationen für Terminplanung und Buchhaltung.
Warum YuSMP
Von Data-Engineering über GPU-Training bis Serving und Monitoring verantworten dieselben Senior-Entwickler das Modell end-to-end — ohne Übergabelücken.
Wir entwickeln vom ersten Commit an für die EU-KI-Verordnung, DSGVO, NIST AI RMF und SOC 2 — nicht erst als nachträglichen Gedanken vor dem Launch.
Reproduzierbare Pipelines, optimierte Inferenz und Live-Monitoring sorgen dafür, dass Ihre Modelle unter realer Last schnell, genau und beobachtbar bleiben.
FAQ
Für die meisten neuen Deep-Learning-Projekte empfehlen wir PyTorch: Die Eager Execution, das Debugging-Erlebnis und das Ökosystem (Lightning, Hugging Face) beschleunigen Forschung und Iteration. TensorFlow hat weiterhin Stärken bei einigen Mobile- und Legacy-Serving-Stacks. Gern bewerten wir Ihre bestehenden Assets und wählen das Framework, das Risiko und Gesamtkosten minimiert.
Training ist stoßweise und GPU-intensiv — Sie benötigen leistungsstarke, oft verteilte Hardware für Stunden oder Tage und geben sie danach wieder frei. Inferenz ist gleichmäßig und latenzkritisch, optimiert auf Durchsatz und Kosten pro Anfrage. Wir gestalten beide getrennt, damit Sie nie für ungenutzte Trainings-GPUs zahlen, um Vorhersagen auszuliefern, und dimensionieren jede Komponente unabhängig.
Übliche Wege sind TorchServe für natives PyTorch-Serving mit integriertem Batching und Metriken oder ein FastAPI-Service, der das Modell für mehr Kontrolle und individuelle Logik kapselt. Für hohen Durchsatz ergänzen wir ONNX Runtime oder Triton. Wir wählen anhand Ihrer Latenzziele, Skalierung und bestehenden Plattform.
ONNX ist ein portables Modellformat, mit dem Sie PyTorch-Modelle auf optimierten Runtimes über verschiedene Hardware hinweg ausführen können. Sobald ein Modell ausreichend genau ist, exportieren wir nach ONNX und wenden Quantisierung oder Distillation an, um es zu verkleinern und die Latenz zu senken. Bei sorgfältiger Umsetzung reduziert das die Inferenzkosten in der Regel deutlich bei minimalem Genauigkeitsverlust.
Wir standardisieren auf MLflow für Experiment-Tracking und Model Registry, Ray für verteilte Workloads, Docker und Kubernetes für das Deployment sowie CI/CD-Pipelines, die Releases anhand von Evaluierungsmetriken freigeben. Das Monitoring umfasst Data Drift, Vorhersagequalität und Latenz. Die genauen Tools passen wir flexibel an Ihre Cloud und bestehende Infrastruktur an.
Wir nutzen Spot- oder Preemptible-Instanzen für das Training, Autoscaling und Scale-to-Zero für die Inferenz, Mixed-Precision-Training sowie Modelloptimierung für kleinere Hardware. Außerdem profilen wir Jobs, um Engpässe zu beseitigen, sodass GPUs schneller fertig werden. Zusammen senken diese Maßnahmen die Compute-Kosten oft erheblich, ohne den Durchsatz zu beeinträchtigen.
Die Verordnung klassifiziert KI-Systeme nach Risiko und legt Pflichten fest — technische Dokumentation, Daten-Governance, menschliche Aufsicht und Konformitätsbewertung — vor allem für Anwendungen mit hohem Risiko. Wir helfen Ihnen, jedes Modell zu klassifizieren, korrekt zu dokumentieren und Aufsicht sowie Logging in den Inferenzpfad einzubauen, damit Sie die Anforderungen erfüllen, ohne die Auslieferung auszubremsen.
Antwort innerhalb von 1 Werktag. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.