Training-serving skew
Features computed differently in notebooks and production silently degrade live accuracy, and the drift is hard to spot without shared transforms.
PyTorch Deep Learning MLOps ONNX
We build, train and ship PyTorch models that survive contact with production. From data pipelines and distributed GPU training to low-latency inference APIs, our engineers cover the full lifecycle. US and EU teams rely on us to turn research notebooks into governed, monitored services — not just one-off experiments. Every deployment is reproducible, observable and compliant by design.

We build, train and ship PyTorch models that survive contact with production. From data pipelines and distributed GPU training to low-latency inference APIs, our engineers cover the full lifecycle. US and EU teams rely on us to turn research notebooks into governed, monitored services — not just one-off experiments. Every deployment is reproducible, observable and compliant by design.
Challenges
Features computed differently in notebooks and production silently degrade live accuracy, and the drift is hard to spot without shared transforms.
Untracked runs, random seeds and data versions make results impossible to reproduce or audit months later.
Idle GPUs, oversized instances and naive distributed training quietly burn budget while jobs still take too long.
Without live metrics and drift detection, models decay against shifting data and no one notices until users complain.
Research-grade models are often too heavy to serve at target latency and cost without ONNX export, quantisation or distillation.
Personal data leaks into training corpora, breaching GDPR and CCPA and creating models that cannot satisfy erasure requests.
Solutions
We build reproducible PyTorch and Lightning training pipelines with shared feature transforms, distributed multi-GPU support via Ray, and versioned data.
MLflow captures parameters, metrics, artefacts and lineage for every run, so results are comparable, reproducible and audit-ready.
We expose models through TorchServe or FastAPI with batching, autoscaling and health checks behind clean, versioned endpoints.
ONNX export, quantisation and distillation cut model size and latency, letting you hit cost and SLA targets on CPU or GPU.
Automated retraining, evaluation gates and deployment run through CI/CD, with live drift, latency and quality monitoring in production.
We track dataset provenance, enforce PII controls and wire erasure into pipelines so models stay compliant with EU and US rules.
Stack
PyTorch, Lightning, TorchServe, ONNX, CUDA, Hugging Face, MLflow, Ray, FastAPI, Docker, Kubernetes.
Compliance
EU AI Act · GDPR training data · model governance · SOC 2
Cases

Cross-platform sports news app and web portal — Telegram-bot CMS instead of a custom admin, Markdown publishing pipeline.
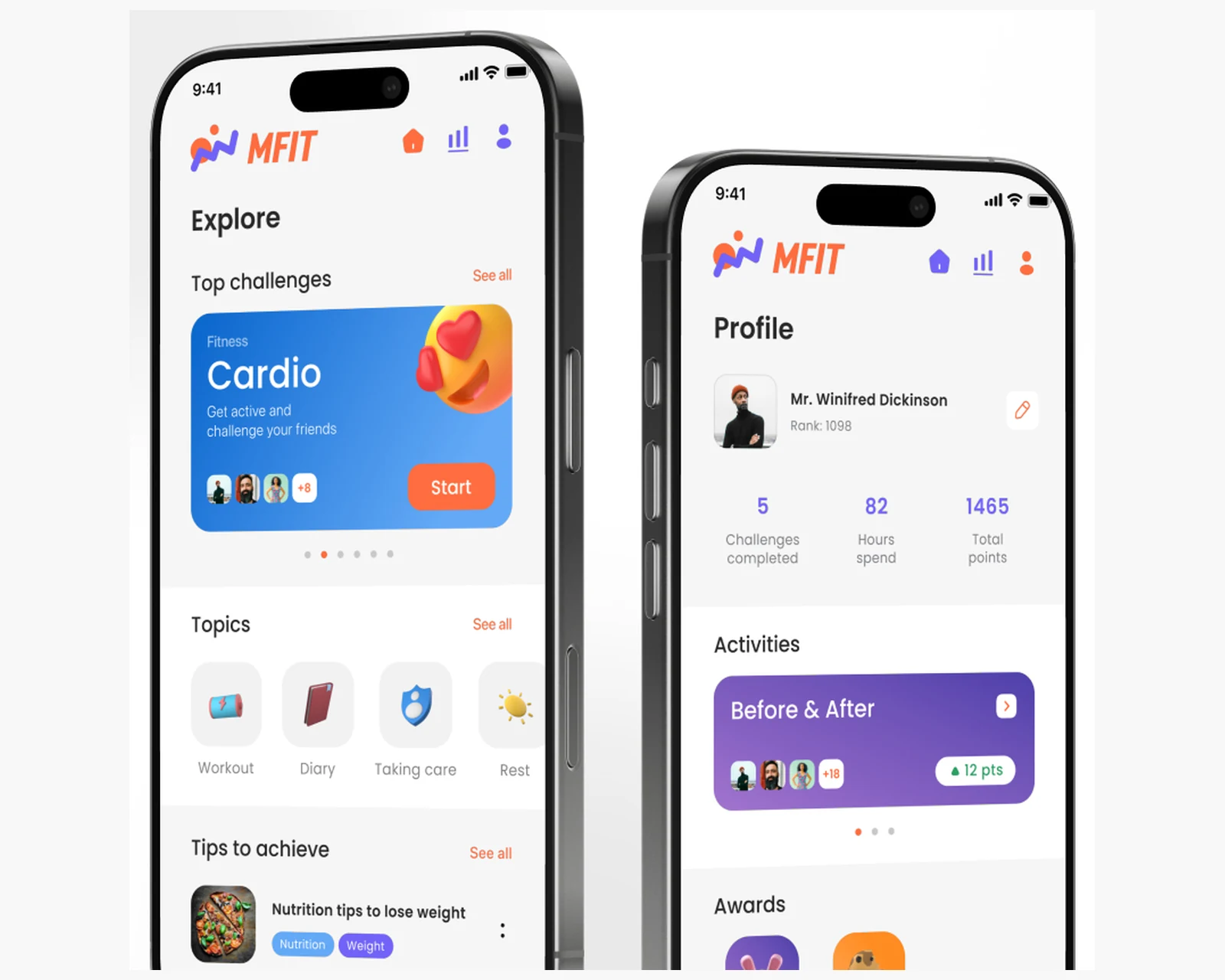
Native iOS & Android fitness-marathon and challenge app — programs, stats, and leaderboards on a Laravel backend, for the US & EU.
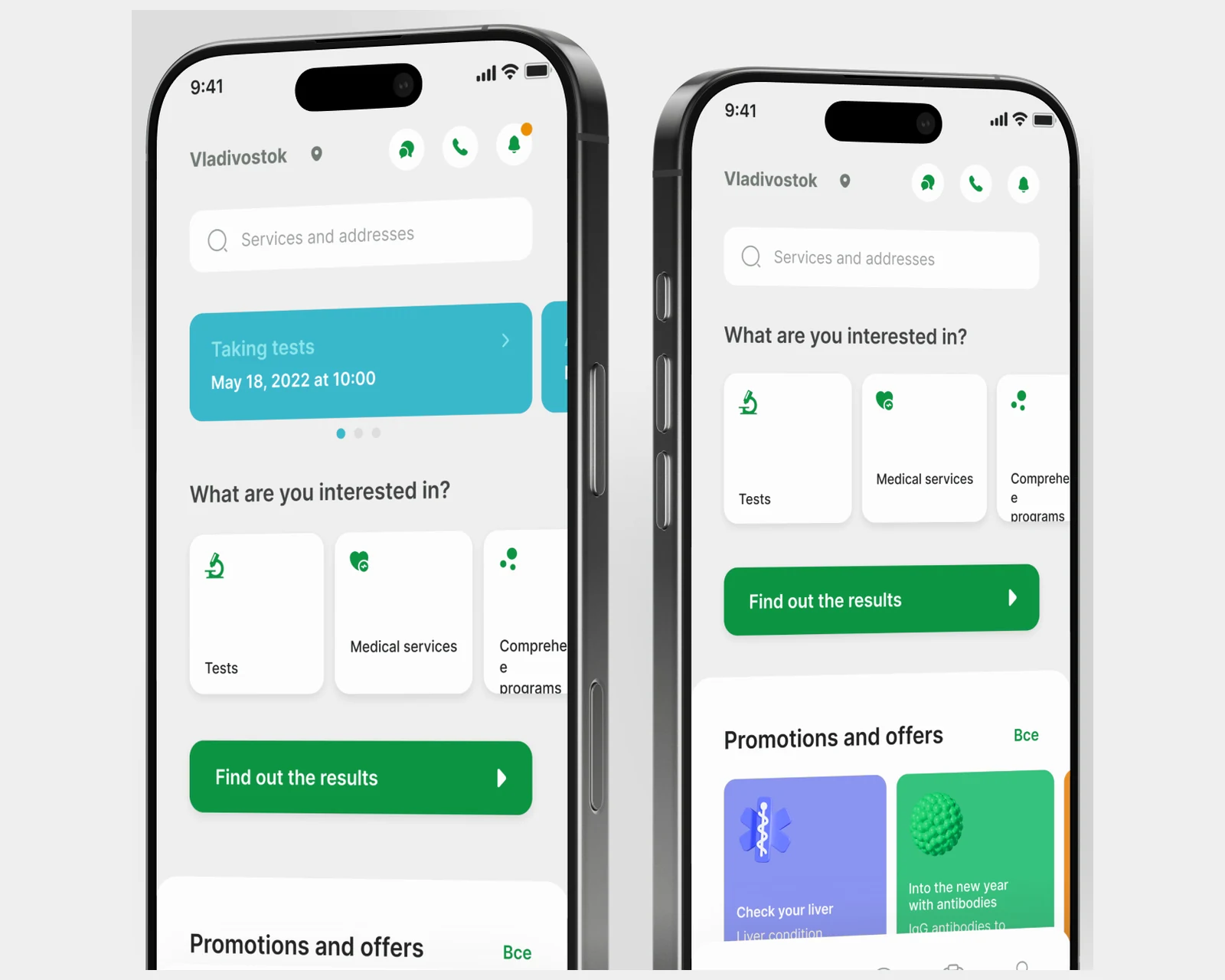
Patient app for a 40-city lab network — appointment booking, digital results, 2,500+ tests, scheduling and accounting integrations.
Why YuSMP
From data engineering to GPU training, serving and monitoring, the same senior engineers own the model end to end — no handoff gaps.
We design for the EU AI Act, GDPR, NIST AI RMF and SOC 2 from the first commit, not as an afterthought before launch.
Reproducible pipelines, optimised inference and live monitoring mean your models stay fast, accurate and observable under real load.
FAQ
For most new deep-learning work we recommend PyTorch: its eager execution, debugging experience and ecosystem (Lightning, Hugging Face) make research and iteration faster. TensorFlow still has strengths in some mobile and legacy serving stacks. We are happy to assess your existing assets and pick the framework that minimises risk and total cost.
Training is bursty and GPU-heavy — you need powerful, often distributed hardware for hours or days, then release it. Inference is steady and latency-sensitive, optimised for throughput and cost per request. We design them separately so you never pay for idle training GPUs to serve predictions, and we right-size each independently.
Common paths are TorchServe for native PyTorch serving with built-in batching and metrics, or a FastAPI service wrapping the model for tighter control and custom logic. For high throughput we add ONNX Runtime or Triton. We choose based on your latency targets, scale and existing platform.
ONNX is a portable model format that lets you run PyTorch models on optimised runtimes across hardware. Once a model is accurate enough, we export to ONNX and apply quantisation or distillation to shrink it and cut latency. This typically reduces inference cost substantially with minimal accuracy loss when done carefully.
We standardise on MLflow for experiment tracking and model registry, Ray for distributed workloads, Docker and Kubernetes for deployment, and CI/CD pipelines that gate releases on evaluation metrics. Monitoring covers data drift, prediction quality and latency. The exact tools flex to fit your cloud and existing infrastructure.
We use spot or preemptible instances for training, autoscaling and scale-to-zero for inference, mixed-precision training, and model optimisation to fit smaller hardware. We also profile jobs to remove bottlenecks so GPUs finish faster. Together these often cut compute spend significantly without sacrificing throughput.
The Act classifies AI systems by risk and imposes obligations — technical documentation, data governance, human oversight and conformity assessment — mainly on high-risk uses. We help you classify each model, document it correctly, and build oversight and logging into the inference path so you meet the requirements without stalling delivery.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.