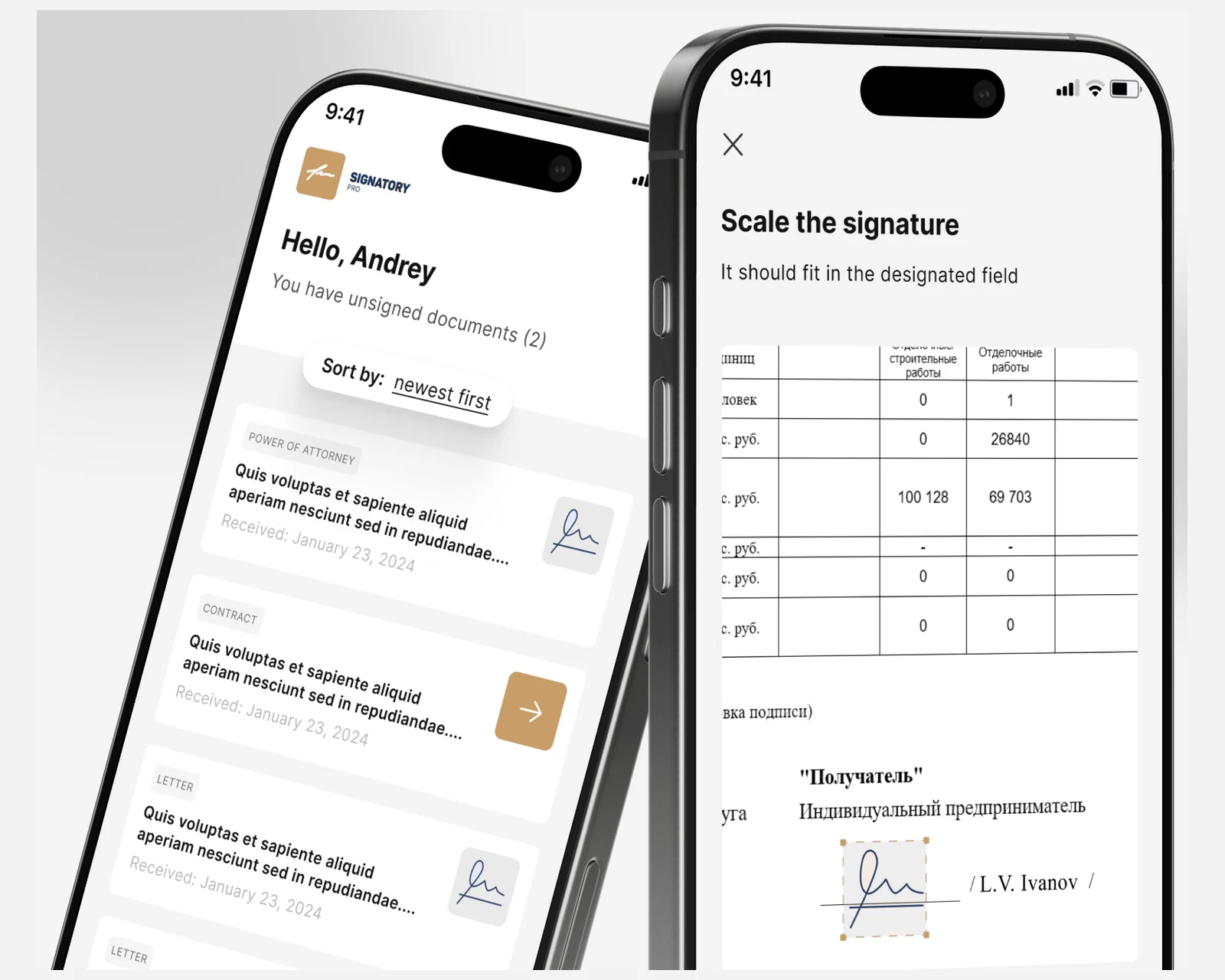
Corpus-Ingestion & Chunking
Konnektoren für SharePoint, Confluence, Google Drive, S3, Slack, Notion und Datenbankextrakte. Rekursive Splitter, abgestimmt auf Ihre Dokumentverteilung — juristischer Fließtext, technische Dokumente mit Code, Transkripte — mit auf Ihrem Eval-Set kalibrierter Überlappung.