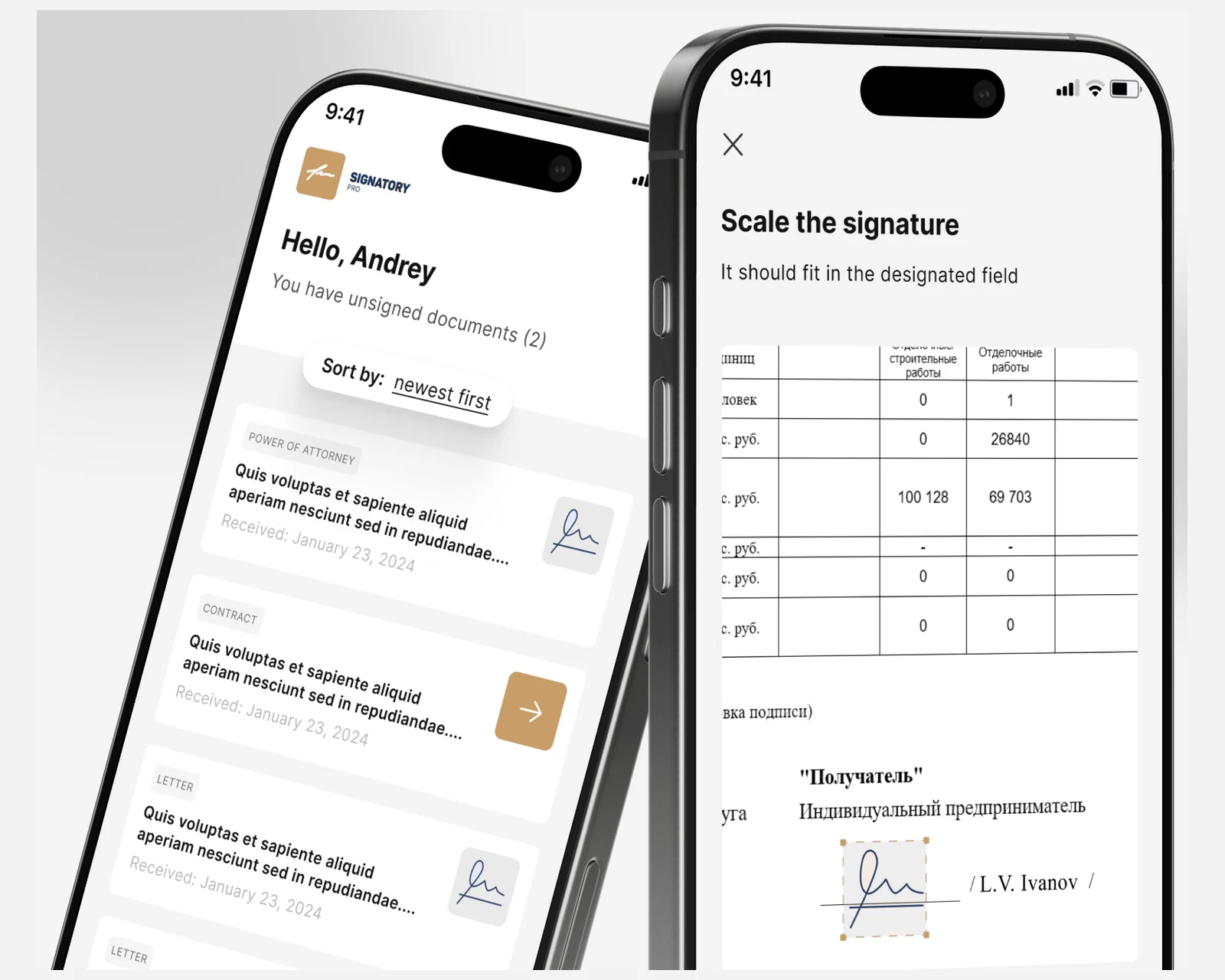
Corpus ingestion & chunking
Connectors for SharePoint, Confluence, Google Drive, S3, Slack, Notion, and database extracts. Recursive splitters tuned to your document distribution — legal prose, technical docs with code, transcripts — with overlap calibrated on your eval set.