Chunking- & Parsing-Qualität
Unsaubere PDFs, Tabellen und gemischte Formate erzeugen schlechte Chunks, die das Retrieval ruinieren, bevor ein Modell die Daten überhaupt sieht.
LlamaIndex RAG Retrieval Agenten
Wir konzipieren und liefern Retrieval-Augmented-Generation-Systeme auf Basis von LlamaIndex für Kunden in den USA und der Europäischen Union. Von der Dokumenten-Ingestion und Indexierung bis hin zu hybridem Retrieval, Reranking und fundierten, mit Quellen belegten Antworten verwandeln wir private Wissensdatenbanken in zuverlässige LLM-Anwendungen. Unsere Senior-Entwickler verantworten den gesamten Weg – Parsing-Pipelines, Vektorspeicher, Evaluation und Observability – mit Compliance von Tag eins an.

Wir konzipieren und liefern Retrieval-Augmented-Generation-Systeme auf Basis von LlamaIndex für Kunden in den USA und der Europäischen Union. Von der Dokumenten-Ingestion und Indexierung bis hin zu hybridem Retrieval, Reranking und fundierten, mit Quellen belegten Antworten verwandeln wir private Wissensdatenbanken in zuverlässige LLM-Anwendungen. Unsere Senior-Entwickler verantworten den gesamten Weg – Parsing-Pipelines, Vektorspeicher, Evaluation und Observability – mit Compliance von Tag eins an.
Herausforderungen
Unsaubere PDFs, Tabellen und gemischte Formate erzeugen schlechte Chunks, die das Retrieval ruinieren, bevor ein Modell die Daten überhaupt sieht.
Naive Vektorsuche liefert Beinahe-Treffer; ohne Reranking erreichen die relevantesten Passagen nie den Prompt.
Antworten, die von den Quelldokumenten abweichen, untergraben das Vertrauen und schaffen in regulierten Bereichen Compliance-Risiken.
Dokumente ändern sich ständig, und veraltete Indizes liefern Nutzern überholte oder widersprüchliche Antworten.
Das Retrieval kann Inhalte preisgeben, die ein bestimmter Nutzer nicht sehen darf, sofern Berechtigungen nicht zur Abfragezeit durchgesetzt werden.
Ohne Retrieval- und Antwortmetriken gehen Regressionen unbemerkt in Produktion, und die Qualität lässt sich gegenüber Stakeholdern nicht belegen.
Lösungen
Robuste Loader, layout-bewusstes Parsing und abgestimmtes Chunking, die Struktur und Bedeutung für hochwertiges Retrieval bewahren.
Kombiniertes dichtes und schlagwortbasiertes Retrieval mit Cross-Encoder-Rerankern, um den wirklich relevantesten Kontext sichtbar zu machen.
Query Engines, die die Generierung auf abgerufene Belege beschränken und für jede Aussage Inline-Quellenangaben zurückgeben.
Änderungsbewusste Pipelines, die Embeddings und Indizes aktualisieren, sobald Quelldokumente hinzugefügt, bearbeitet oder entfernt werden.
Nutzerspezifische Metadaten-Filterung und Zugriffsrichtlinien, die innerhalb des Retrievals durchgesetzt werden, sodass Nutzer nur autorisierte Inhalte sehen.
Evaluation von Retrieval und Antwortqualität, Regressionstests und Produktions-Observability für Latenz, Kosten und Genauigkeit.
Stack
LlamaIndex, Vektorspeicher (pgvector, Qdrant, Pinecone, Weaviate), Embeddings, LLMs von OpenAI, Anthropic und Hugging Face, Reranker, FastAPI, Postgres, Docker.
Compliance
EU-KI-Verordnung · DSGVO · Datenresidenz · SOC 2
Cases
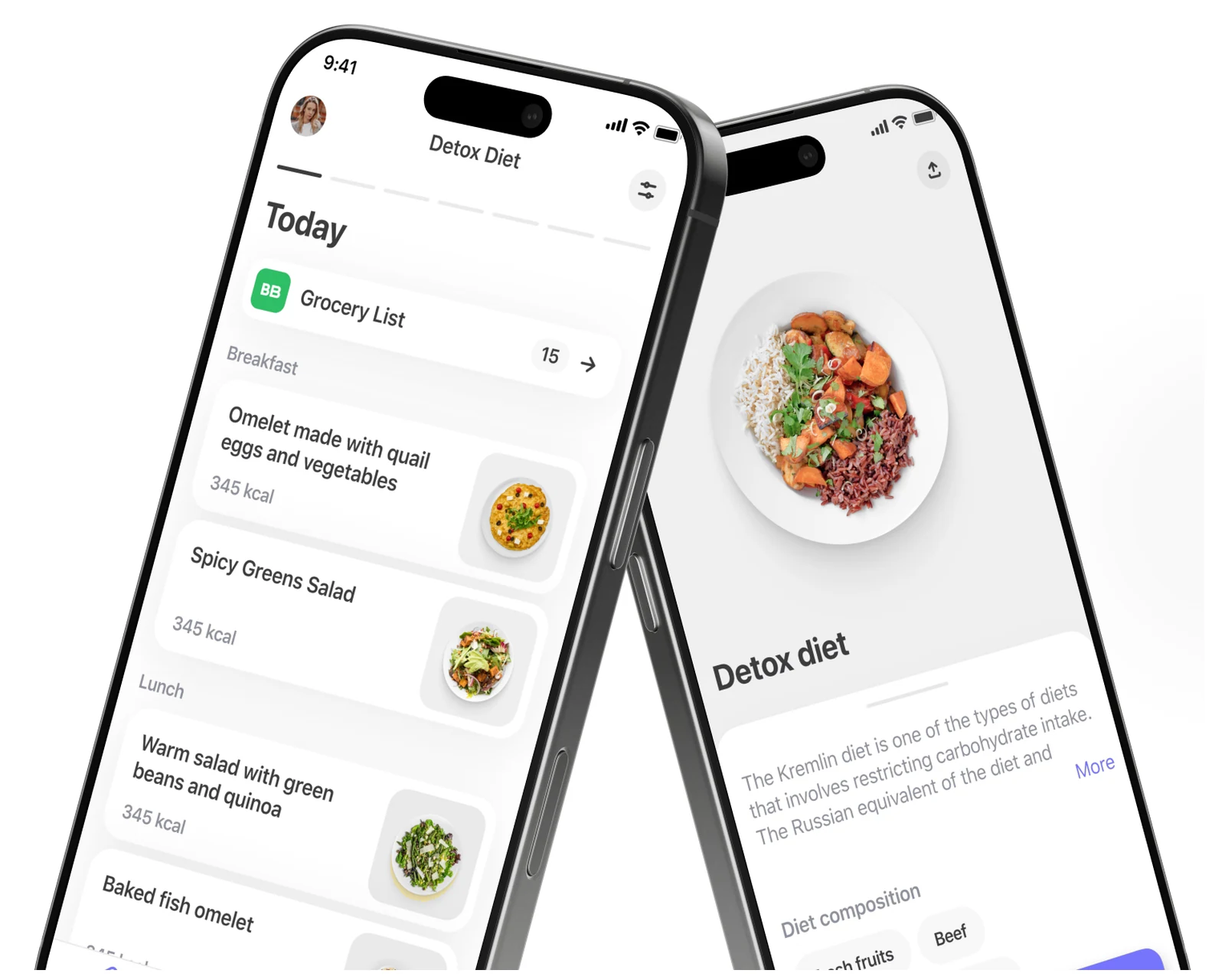
Plattformübergreifende App für Ernährung und Mahlzeitenplanung auf Flutter — Kalorien-Engine, Rezeptbibliothek, Wochen-Mahlzeitenplan, Lebensmittelbestellung.
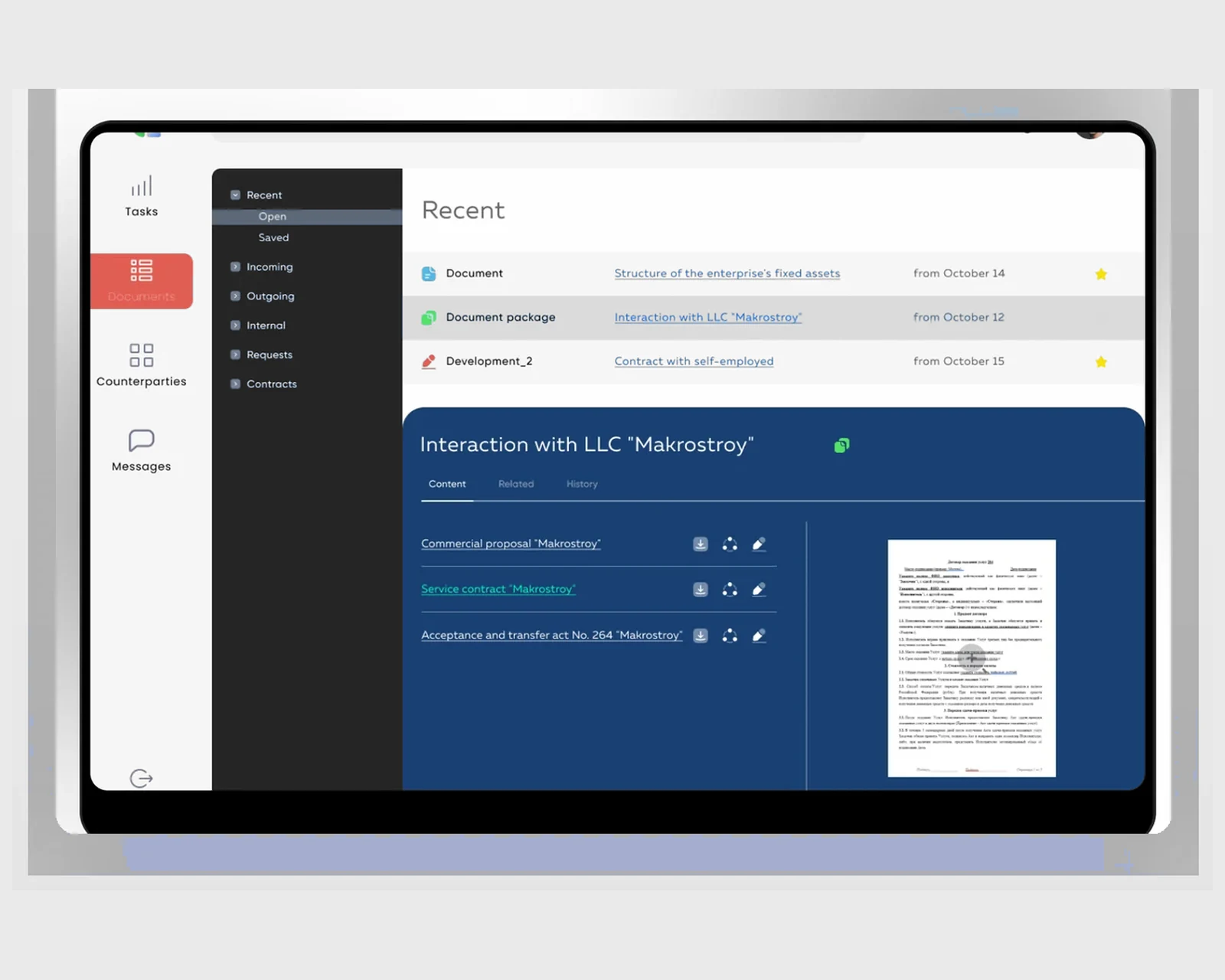
Ein internes EDM für eine Einzelhandelskette — E-Signaturen, Genehmigungs-Routing, Geschäftspartner und Aufgaben auf React + Laravel, gebaut für den Betrieb in den USA & der EU.
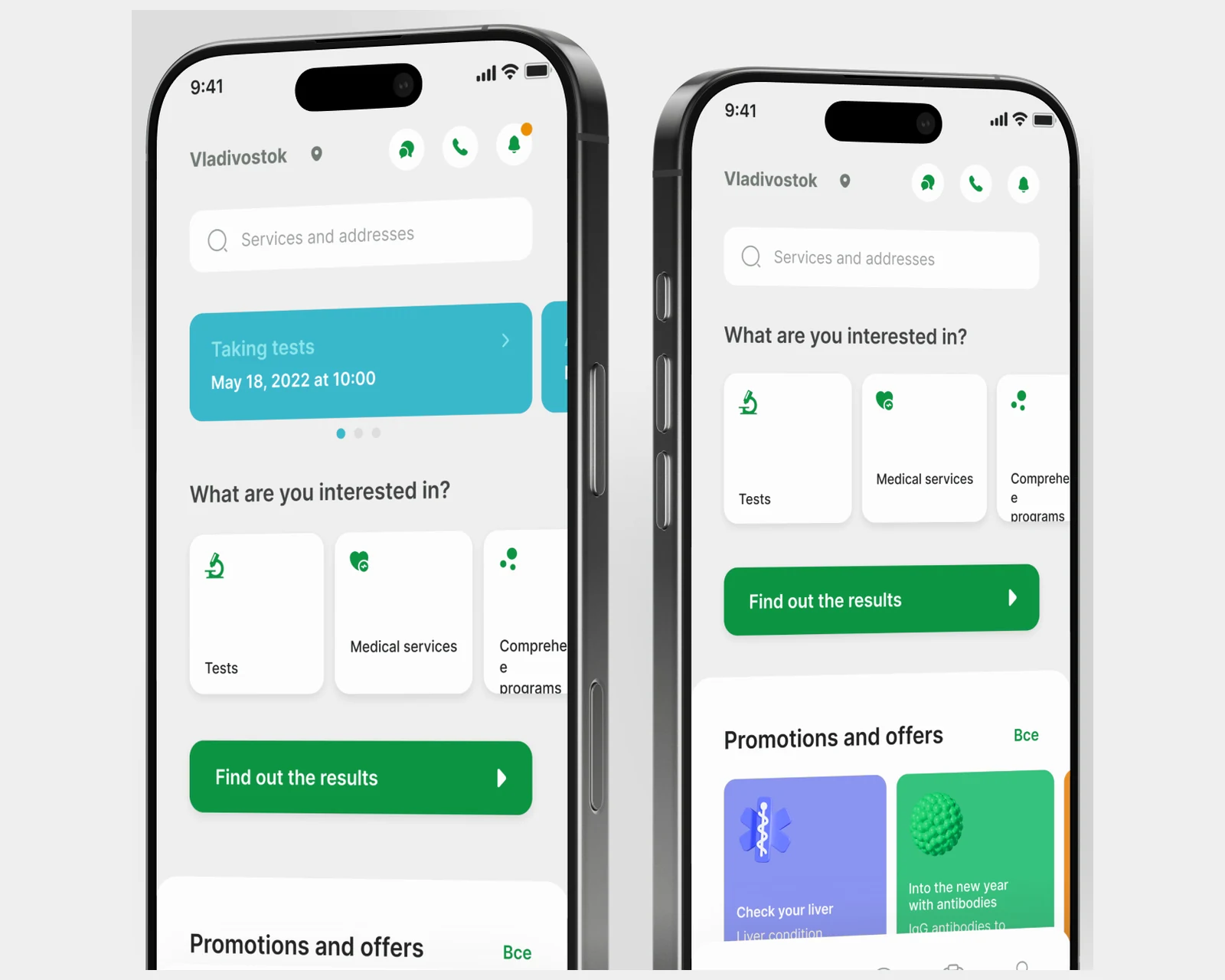
Patienten-App für ein Labornetzwerk in 40 Städten — Terminbuchung, digitale Befunde, 2.500+ Tests, Integrationen für Terminplanung und Buchhaltung.
Warum YuSMP
Sie arbeiten mit Entwicklern zusammen, die das gesamte System verantworten – Parsing, Retrieval, LLM-Orchestrierung, Infrastruktur und Evaluation – nicht nur eine einzelne Schicht.
Aspekte der EU-KI-Verordnung, DSGVO, HIPAA und SOC 2 prägen die Architektur ab dem ersten Sprint, nicht erst nachträglich.
Wir liefern evaluiertes, observierbares, berechtigungsbewusstes RAG, das echten Nutzern, echten Datenmengen und echten Audits standhält.
FAQ
LlamaIndex ist gezielt rund um Daten aufgebaut – Ingestion, Indexierung und Retrieval – und eignet sich daher hervorragend für dokumentenintensives RAG über private Wissensdatenbanken. LangChain ist breiter angelegt für allgemeine Agenten- und Tool-Orchestrierung. Beide schließen sich nicht gegenseitig aus, und wir kombinieren sie häufig; wir wählen anhand Ihrer Daten, Latenz und Teamrahmenbedingungen aus, nicht nach Mode.
RAG ist meist der richtige erste Schritt, wenn Antworten aktuelle, private oder häufig wechselnde Dokumente widerspiegeln müssen, weil es die Antworten in abgerufenen Belegen verankert und deutlich günstiger aktuell zu halten ist. Fine-Tuning eignet sich für festen Stil, festes Format oder eng umrissene Aufgaben. Viele Produktionssysteme nutzen RAG als Rückgrat und behalten Fine-Tuning für bestimmte Verhaltensweisen vor.
Chunking richtet sich nach Dokumentstruktur und Abfragemustern, nicht nach einer festen Token-Anzahl. Wir nutzen layout-bewusstes Parsing, semantisches und hierarchisches Chunking sowie Metadaten-Anreicherung und validieren die Entscheidungen anschließend gegen ein Retrieval-Evaluationsset, sodass Chunk-Größe und Überlappung auf messbare Relevanz statt auf Vermutungen abgestimmt sind.
Das hängt von Umfang, Hosting und vorhandener Infrastruktur ab. Häufig beginnen wir mit pgvector, wenn Sie ohnehin Postgres betreiben, und wechseln zu Qdrant, Weaviate oder Pinecone, sobald Sie höheren Durchsatz, fortgeschrittenes Filtern oder verwalteten Betrieb benötigen. Anforderungen an Datenresidenz und Compliance entscheiden häufig über die endgültige Wahl.
Wir beschränken die Generierung auf den abgerufenen Kontext, verlangen Inline-Quellenangaben und stimmen Retrieval und Reranking so ab, dass die richtigen Belege das Modell erreichen. Wir ergänzen Prüfungen zur Antwortverankerung und ein Konfidenz-Handling, damit das System ablehnen oder eskalieren kann, wenn die Belege schwach sind, und wir messen die Treue zur Quelle laufend in der Evaluation.
Ja. Wir versehen Dokumente mit Berechtigungs-Metadaten und setzen diese als Filter innerhalb des Retrievals durch, sodass jeder Nutzer nur Inhalte abruft, für die er berechtigt ist. Zugriffsrichtlinien werden zur Abfragezeit angewendet und protokolliert, wodurch RAG mit Ihrem bestehenden Berechtigungsmodell und Ihren Audit-Anforderungen im Einklang bleibt.
Wir behandeln Quelldokumente, Embeddings und Indizes als Speicher personenbezogener Daten: PII wird identifiziert, Zugriffe werden kontrolliert, die Verarbeitung wird dokumentiert, und wir unterstützen Löschung und Berichtigung sowohl bei den Rohdokumenten als auch bei den abgeleiteten Embeddings. Eine EU-Datenresidenz für Vektorspeicher und Inferenz wird konfiguriert, wo erforderlich.
Antwort innerhalb von 1 Werktag. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.