Chunking & parsing quality
Messy PDFs, tables and mixed formats produce poor chunks that wreck retrieval before a model ever sees the data.
LlamaIndex RAG Retrieval Agents
We design and ship retrieval-augmented generation systems on LlamaIndex for clients across the United States and the European Union. From document ingestion and indexing to hybrid retrieval, reranking and grounded, cited answers, we turn private knowledge bases into reliable LLM applications. Our senior engineers own the full path – parsing pipelines, vector stores, evaluation and observability – with compliance built in from day one.

We design and ship retrieval-augmented generation systems on LlamaIndex for clients across the United States and the European Union. From document ingestion and indexing to hybrid retrieval, reranking and grounded, cited answers, we turn private knowledge bases into reliable LLM applications. Our senior engineers own the full path – parsing pipelines, vector stores, evaluation and observability – with compliance built in from day one.
Challenges
Messy PDFs, tables and mixed formats produce poor chunks that wreck retrieval before a model ever sees the data.
Naive vector search returns near-misses; without reranking the most relevant passages never reach the prompt.
Answers that drift from the source documents erode trust and create compliance exposure in regulated domains.
Documents change constantly, and stale indexes serve outdated or contradictory answers to users.
Retrieval can leak content a given user is not permitted to see unless permissions are enforced at query time.
Without retrieval and answer metrics, regressions ship silently and quality cannot be defended to stakeholders.
Solutions
Robust loaders, layout-aware parsing and tuned chunking that preserve structure and meaning for high-quality retrieval.
Combined dense and keyword retrieval with cross-encoder rerankers to surface the genuinely most relevant context.
Query engines that constrain generation to retrieved evidence and return inline source citations for every claim.
Change-aware pipelines that update embeddings and indexes as source documents are added, edited or removed.
Per-user metadata filtering and access policies enforced inside retrieval so users only ever see authorised content.
Retrieval and answer-quality evaluation, regression tests and production observability for latency, cost and accuracy.
Stack
LlamaIndex, vector stores (pgvector, Qdrant, Pinecone, Weaviate), embeddings, OpenAI, Anthropic and Hugging Face LLMs, rerankers, FastAPI, Postgres, Docker.
Compliance
EU AI Act · GDPR · data residency · SOC 2
Cases
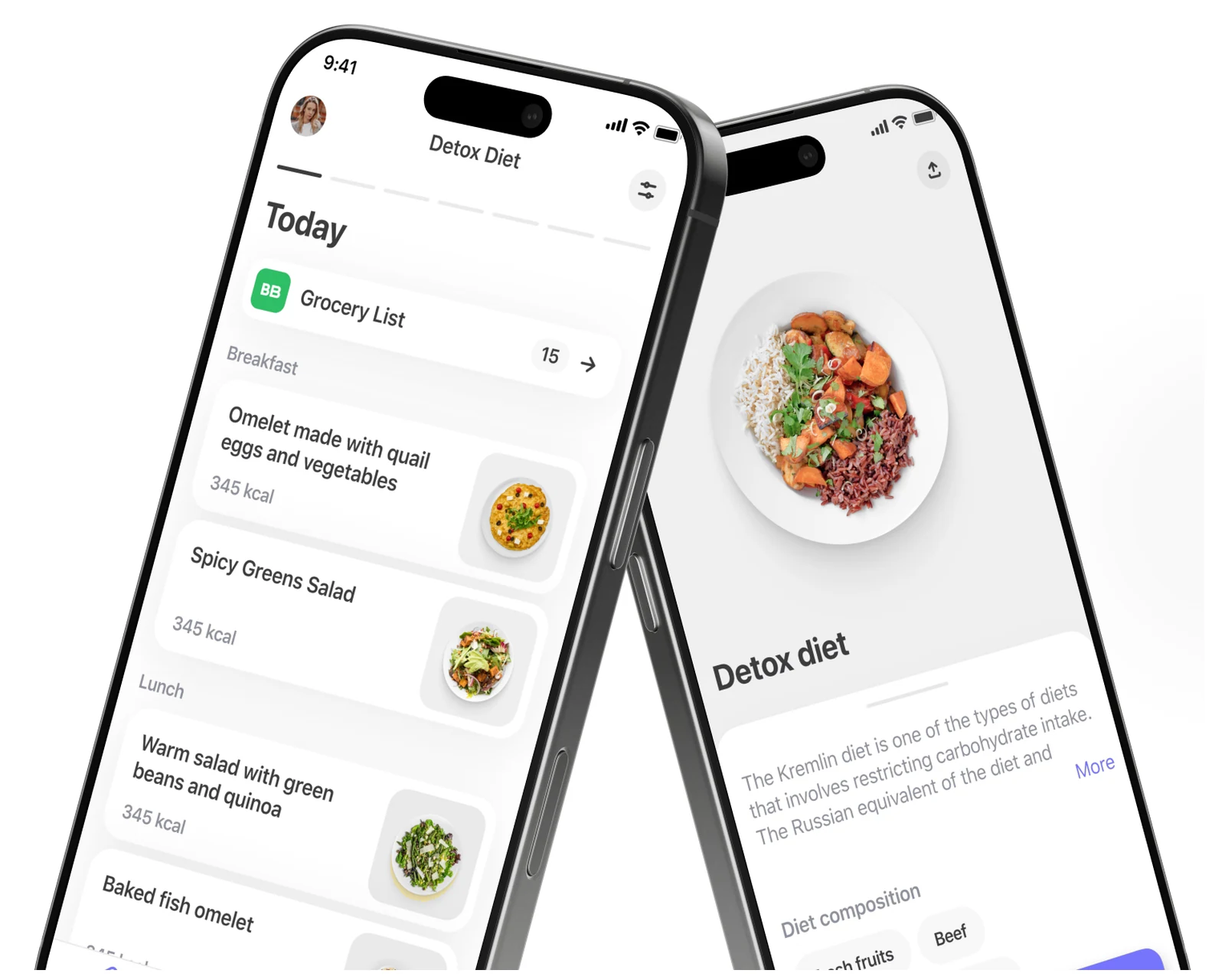
Cross-platform diet and meal-planning app on Flutter — calorie engine, recipe library, weekly meal-plan, grocery ordering.
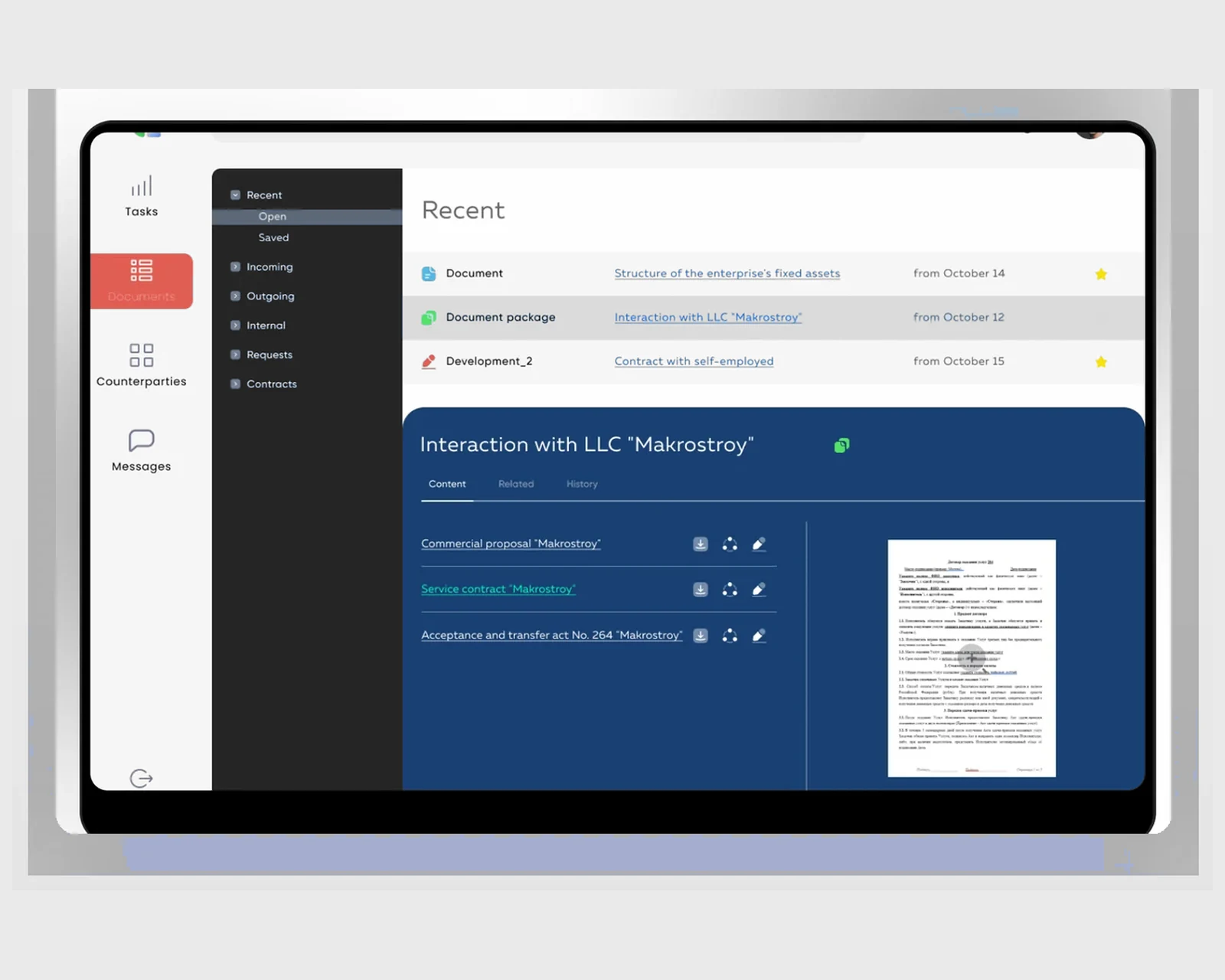
An internal EDM for a retail chain — e-signatures, approval routing, counterparties, and tasks on React + Laravel, built for US & EU operations.
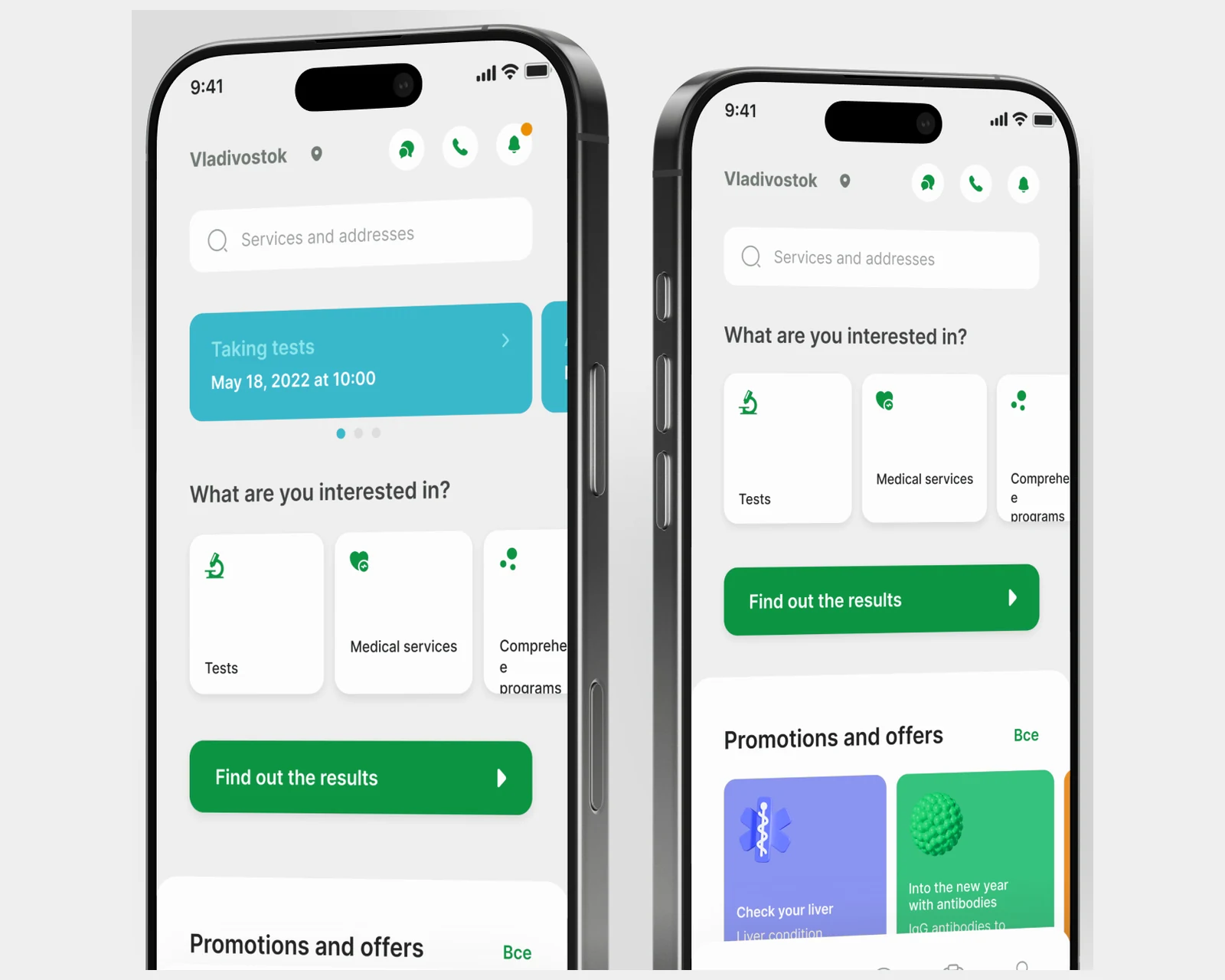
Patient app for a 40-city lab network — appointment booking, digital results, 2,500+ tests, scheduling and accounting integrations.
Why YuSMP
You work with engineers who own the whole system – parsing, retrieval, LLM orchestration, infrastructure and evaluation – not a single layer.
EU AI Act, GDPR, HIPAA and SOC 2 considerations shape the architecture from the first sprint, not as an afterthought.
We ship evaluated, observable, permission-aware RAG that holds up under real users, real data volumes and real audits.
FAQ
LlamaIndex is purpose-built around data – ingestion, indexing and retrieval – which makes it a strong fit for document-heavy RAG over private knowledge bases. LangChain is broader for general agent and tool orchestration. The two are not mutually exclusive, and we often combine them; we pick based on your data, latency and team constraints rather than fashion.
RAG is usually the right first step when answers must reflect current, private or frequently changing documents, because it grounds responses in retrieved evidence and is far cheaper to keep up to date. Fine-tuning suits fixed style, format or narrow tasks. Many production systems use RAG as the backbone and reserve fine-tuning for specific behaviours.
Chunking is driven by document structure and query patterns, not a fixed token count. We use layout-aware parsing, semantic and hierarchical chunking, and metadata enrichment, then validate choices against a retrieval evaluation set so chunk size and overlap are tuned to measurable relevance rather than guesswork.
It depends on scale, hosting and existing infrastructure. We often start with pgvector when you already run Postgres, and move to Qdrant, Weaviate or Pinecone when you need higher throughput, advanced filtering or managed operations. Data-residency and compliance requirements frequently decide the final choice.
We constrain generation to retrieved context, require inline citations, and tune retrieval and reranking so the right evidence reaches the model. We add answer-grounding checks and confidence handling so the system can decline or escalate when evidence is weak, and we measure faithfulness continuously in evaluation.
Yes. We attach permission metadata to documents and enforce it as filters inside retrieval, so each user only retrieves content they are authorised to see. Access policies are applied at query time and logged, which keeps RAG aligned with your existing authorisation model and audit requirements.
We treat source documents, embeddings and indexes as personal-data stores: PII is identified, access is controlled, processing is documented, and we support erasure and rectification across both raw documents and derived embeddings. EU data residency for the vector store and inference is configured where required.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.