Collection- & Index-Konfiguration
Die richtige Vektorgrö ß e, Distanzmetrik und HNSW-Parameter (m, ef_construct, ef) von Anfang an wä hlen, denn eine schlechte Index-Konfiguration begrenzt Recall und Latenz spä ter unbemerkt.
Qdrant Vektor-DB HNSW Hybride Suche
Wir konzipieren, tunen und betreiben Qdrant als Retrieval-Engine hinter produktiven RAG-, semantischen Such- und Empfehlungssystemen. Fü r US-Teams hosten wir self-hosted in Ihrer VPC fü r HIPAA- und SOC 2-Kontrolle; fü r EU-Kunden halten wir Vektoren und Payloads in der Region fü r die DSGVO-Datenresidenz. Vom Collection-Schema bis zum verteilten Sharding verantworten wir den gesamten Vektorlayer.

Wir konzipieren, tunen und betreiben Qdrant als Retrieval-Engine hinter produktiven RAG-, semantischen Such- und Empfehlungssystemen. Fü r US-Teams hosten wir self-hosted in Ihrer VPC fü r HIPAA- und SOC 2-Kontrolle; fü r EU-Kunden halten wir Vektoren und Payloads in der Region fü r die DSGVO-Datenresidenz. Vom Collection-Schema bis zum verteilten Sharding verantworten wir den gesamten Vektorlayer.
Herausforderungen
Die richtige Vektorgrö ß e, Distanzmetrik und HNSW-Parameter (m, ef_construct, ef) von Anfang an wä hlen, denn eine schlechte Index-Konfiguration begrenzt Recall und Latenz spä ter unbemerkt.
Payload-Filter mit der Ähnlichkeitssuche kombinieren, ohne aus dem HNSW-Index zu fallen oder bei selektiven Abfragen eine Full-Scan-Strafe zu zahlen.
RAM- und Infrastrukturkosten mit Scalar- oder Binary-Quantisation senken und dabei den Recall innerhalb akzeptabler Grenzen fü r Ihren Anwendungsfall halten.
Shards, Replikationsfaktor und Konsistenz dimensionieren, wä hrend Collections auf Hunderte Millionen Punkte wachsen, ohne Abfragedurchsatz zu verlieren.
Zwischen dem Betrieb eines eigenen Clusters und Qdrant Cloud entscheiden und dann Upgrades, Snapshots und Monitoring in beiden Fä llen zuverlä ssig betreiben.
Vektoren mit sich ä ndernden Quelldaten im Gleichschritt halten und Embedding-Modelle rotieren, ohne veraltete Ergebnisse oder stillen Index-Drift.
Lö sungen
Wir konzipieren Collections und tunen HNSW- und Suchparameter gegen Ihre Recall- und Latenzziele, validiert mit einem echten Evaluierungsset.
Wir kombinieren dichte Vektoren mit dü nnbesetzten und Keyword-Signalen sowie Payload-Filtern, sodass Ergebnisse relevant und korrekt eingegrenzt bleiben.
Wir wenden Scalar- oder Binary-Quantisation und Oversampling an, um Speicher und Kosten drastisch zu senken, und messen den Recall-Kompromiss dabei explizit.
Wir konfigurieren Sharding, Replikation und Konsistenz fü r Collections mit hohem Volumen, mit Kapazitä tsplanung fü r stetiges Wachstum.
Wir deployen auf Docker oder Kubernetes in Ihrer VPC oder auf Qdrant Cloud, mit Snapshots, Monitoring und Upgrade-Runbooks.
Wir binden Qdrant in einen FastAPI-Retrieval-Service mit Re-Ranking, Embedding-Pipelines und Versionierung fü r produktives RAG ein.
Stack
Qdrant, HNSW, payload filtering, scalar/binary quantisation, hybride Suche, Qdrant Cloud, Self-Host (Docker/K8s), Embeddings, FastAPI.
Compliance
DSGVO · Self-Host-Datenresidenz · HIPAA-fä hig · SOC 2
Cases

Plattformü bergreifende Sportnachrichten-App und Web-Portal — Telegram-Bot-CMS statt eines individuellen Admin-Bereichs, Markdown-Publishing-Pipeline.
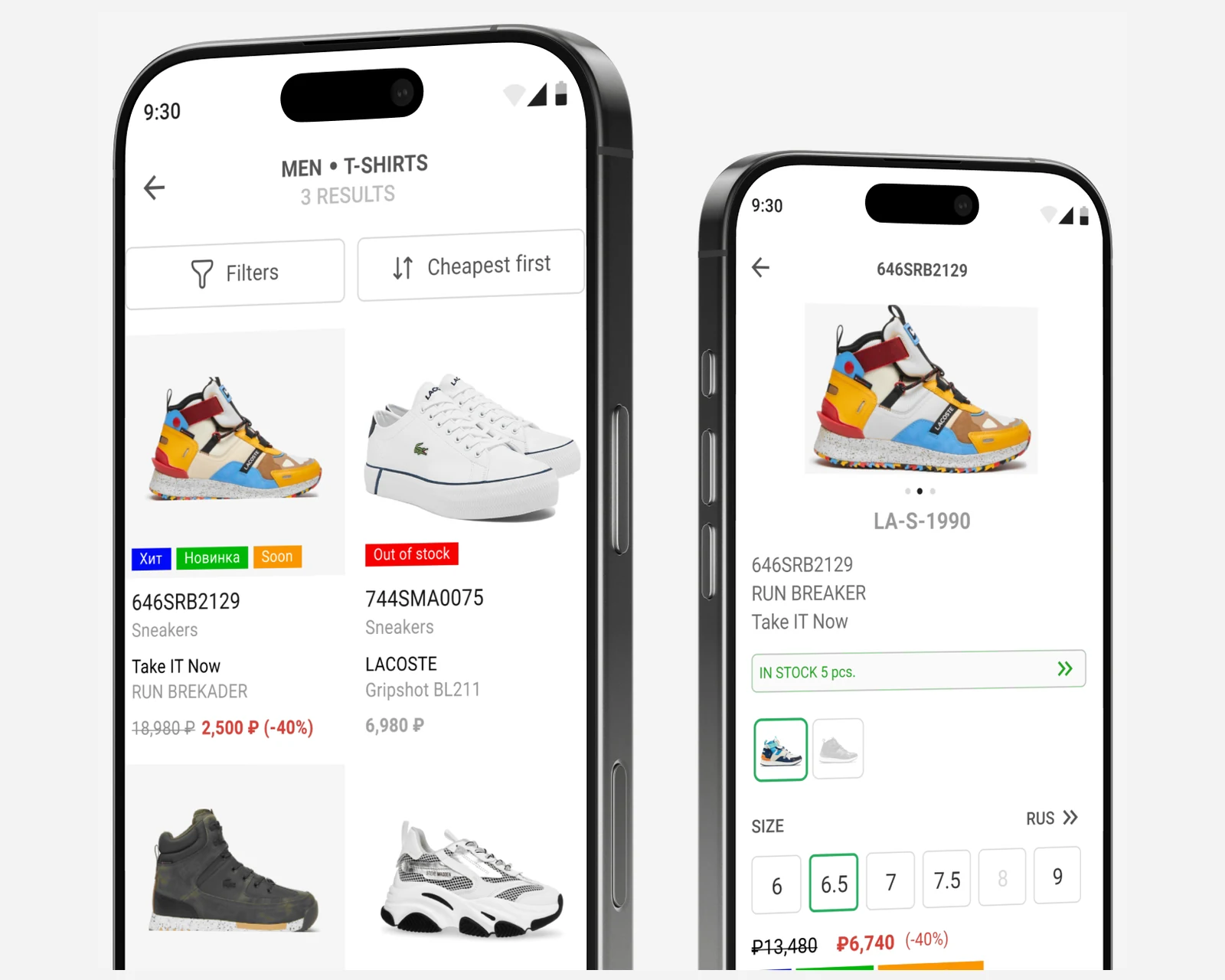
Retail-POS-Begleit-App fü r eine Multi-Brand-Boutiquenkette — ElasticSearch-Inventarsuche ü ber Filialen hinweg, 1C-Systemintegration.

Produktive Social-Plattform — App Store + Google Play, live in den USA und der EU — mit Geo-Radar, verschlü sseltem Messaging und einer virtuellen Wirtschaft.
Warum YuSMP
Wir setzen standardmä ß ig auf Self-Hosting von Qdrant in Ihrer VPC oder EU-Region, sodass HIPAA-, SOC 2- und DSGVO-Datenresidenzanforderungen durch Architektur erfü llt werden, nicht nachträ glich angeflanscht.
Jede Index-, Filter- und Quantisierungsentscheidung wird durch ein Evaluierungs-Harness fü r Recall und Latenz gestü tzt, sodass Sie eine nachweisbare Retrieval-Qualitä t ausliefern.
Vom Collection-Schema ü ber den verteilten Cluster-Betrieb bis zum RAG-Service darü ber verantwortet ein erfahrenes Team den gesamten Retrieval-Stack durchgä ngig.
FAQ
Qdrant ist eine eigens entwickelte, quelloffene Vektordatenbank mit starkem Payload-Filtering, Quantisierung und hybrider Suche und lä uft self-hosted oder als Qdrant Cloud. pgvector ist am einfachsten, wenn Ihre Daten ohnehin in Postgres liegen und der Umfang ü berschaubar ist; Pinecone ist vollstä ndig gemanagt, aber proprietä r und in den USA gehostet; Weaviate ist ein leistungsfä higer quelloffener Mitbewerber. Wir wä hlen Qdrant, wenn Sie quelloffene Kontrolle, In-Region-Self-Hosting und feingranulare gefilterte Suche im groß en Maß stab wü nschen.
Hosten Sie self-hosted in Ihrer VPC, wenn Sie HIPAA, strenge Datenresidenz oder volle Infrastrukturkontrolle benö tigen; wir betreiben es auf Docker oder Kubernetes mit Snapshots und Monitoring. Qdrant Cloud ist der schnellere Weg, wenn Sie ein gemanagtes Cluster wü nschen und Ihre Compliance-Lage es zulä sst. Wir helfen Ihnen bei der Wahl und kö nnen spä ter in beide Richtungen migrieren.
Wir setzen m, ef_construct und das ef zur Abfragezeit gegen Ihr Ziel von Recall und Latenz, anhand eines reprä sentativen Evaluierungssets statt der Standardwerte. Wir tunen auch Segment- und Indexierungsschwellen und testen erneut, sobald sich Datenvolumen oder Abfragemuster wesentlich ä ndern.
Scalar Quantisation reduziert den Speicher typischerweise um etwa das Vierfache und Binary Quantisation deutlich mehr, was Infrastrukturkosten senkt und die Suche beschleunigt. Der Kompromiss ist ein gewisser Recall-Verlust, den wir durch Oversampling und Rescoring ausgleichen und stets explizit messen, bevor wir eine Einstellung empfehlen.
Ja. Qdrant wendet Payload-Filter wä hrend der Vektorsuche mit einem filterbaren Index an, sodass selektive Metadaten-Abfragen schnell bleiben, statt zu vollstä ndigen Scans zu degradieren. Wir kombinieren auch dichte und dü nnbesetzte Vektoren fü r die hybride Suche und nehmen optional ein Re-Ranking vor, um sowohl semantische als auch Keyword-Relevanz zu erzielen.
Qdrant skaliert horizontal ü ber Sharding und Replikation in einem verteilten Cluster. Wir dimensionieren Shard-Anzahl, Replikationsfaktor und Konsistenz fü r Ihre Punktzahl und Ihren Durchsatz, planen Kapazitä t fü r Wachstum und fü hren Lasttests vor dem Launch durch, damit die Latenz hä lt, wä hrend die Collection wä chst.
Das Self-Hosting von Qdrant in Ihrer EU-Region hä lt Vektoren und Payloads innerhalb Ihrer Jurisdiktion und erfü llt die Datenresidenz. Da jeder Punkt eine adressierbare ID und ein Payload trä gt, kö nnen wir bestimmte Datensä tze lö schen oder aktualisieren, um Anfragen zum Recht auf Lö schung und Berichtigung nachzukommen, und wir dokumentieren den Lö sch-Workflow fü r Ihren Datenschutzbeauftragten.
Antwort innerhalb von 1 Werktag. NDA auf Anfrage.
Teilen Sie uns einige Details mit, und ein Senior-Consultant antwortet innerhalb eines Werktages.