Unpredictable cost model
On-demand pricing bills by bytes scanned, so a single unoptimised query against a wide table can cost more than a month of compute. Without slots or editions, spend is hard to forecast and cap.
BigQuery Serverless BigQuery ML GCP
We build and tune Google BigQuery warehouses for product, finance and analytics teams across the US and EU. From dataset design and partitioning to slot reservations, dbt pipelines and BigQuery ML, we make petabyte-scale analytics fast without runaway bills. Every build ships with GDPR-aware residency, governance and clear cost guardrails.
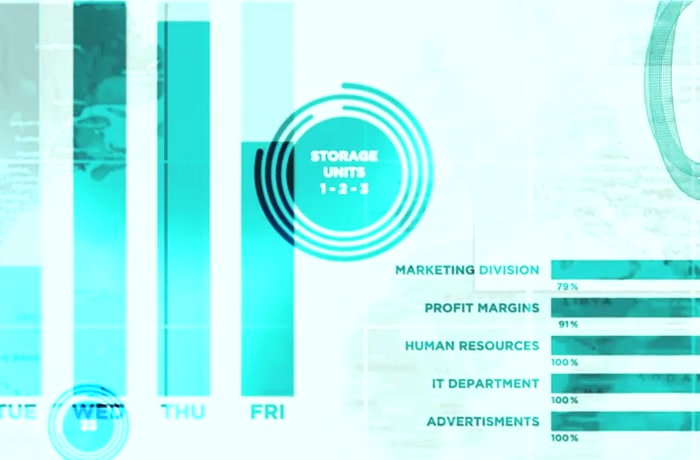
We build and tune Google BigQuery warehouses for product, finance and analytics teams across the US and EU. From dataset design and partitioning to slot reservations, dbt pipelines and BigQuery ML, we make petabyte-scale analytics fast without runaway bills. Every build ships with GDPR-aware residency, governance and clear cost guardrails.
Challenges
On-demand pricing bills by bytes scanned, so a single unoptimised query against a wide table can cost more than a month of compute. Without slots or editions, spend is hard to forecast and cap.
Choosing the wrong partition column — or clustering on low-cardinality fields — means queries still scan whole tables. Bad physical design quietly inflates both latency and cost.
SELECT * on a columnar store reads every column and bills for all of it. Teams routinely scan terabytes when a pruned, partition-filtered query would scan gigabytes.
The streaming API delivers low-latency rows but at-least-once semantics, so duplicates and a buffer that is not immediately queryable for deletes need explicit handling.
A dataset's region is fixed at creation — you cannot move it. Getting EU residency wrong means a costly export, recreate and reload to fix it later.
Erasing a single subject across large partitioned tables means targeted DML and partition-level rewrites, which must be designed in or deletions become slow and expensive.
Solutions
We model datasets, choose partition (date/ingestion/integer-range) and clustering keys to match real query patterns, and set residency and retention from day one.
We pick the right billing model — on-demand, slots or editions reservations — tune queries to prune partitions, and add budgets, byte limits and cost dashboards.
We build maintainable transformations in dbt or Dataform with tests, lineage and CI, replacing brittle hand-written SQL with version-controlled, documented models.
We wire Pub/Sub → Dataflow → BigQuery pipelines with dedup, schema evolution and exactly-once patterns for real-time analytics that stay clean.
We train and serve forecasting, classification and clustering models in SQL with BigQuery ML, keeping data in place and avoiding extra ML infrastructure.
We enforce column- and row-level security, policy tags, IAM least-privilege and region pinning so sensitive data stays governed and compliant.
Stack
BigQuery, partitioning & clustering, BigQuery ML, scheduled queries, dbt, Dataform, Dataflow, Pub/Sub streaming, Looker and Terraform.
Compliance
GDPR · EU data residency · HIPAA-ready · SOC 2
Cases

Cross-platform sports news app and web portal — Telegram-bot CMS instead of a custom admin, Markdown publishing pipeline.
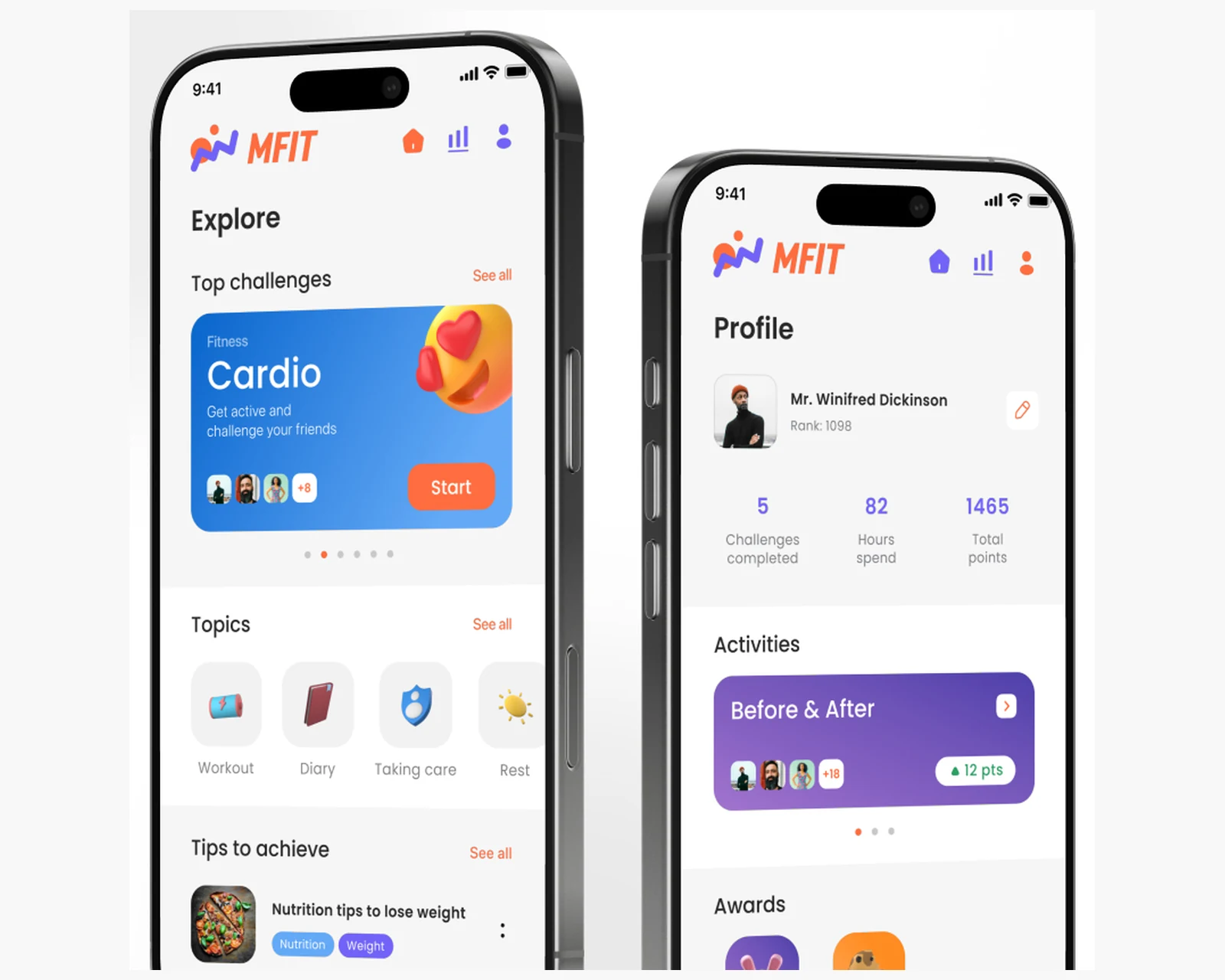
Native iOS & Android fitness-marathon and challenge app — programs, stats, and leaderboards on a Laravel backend, for the US & EU.
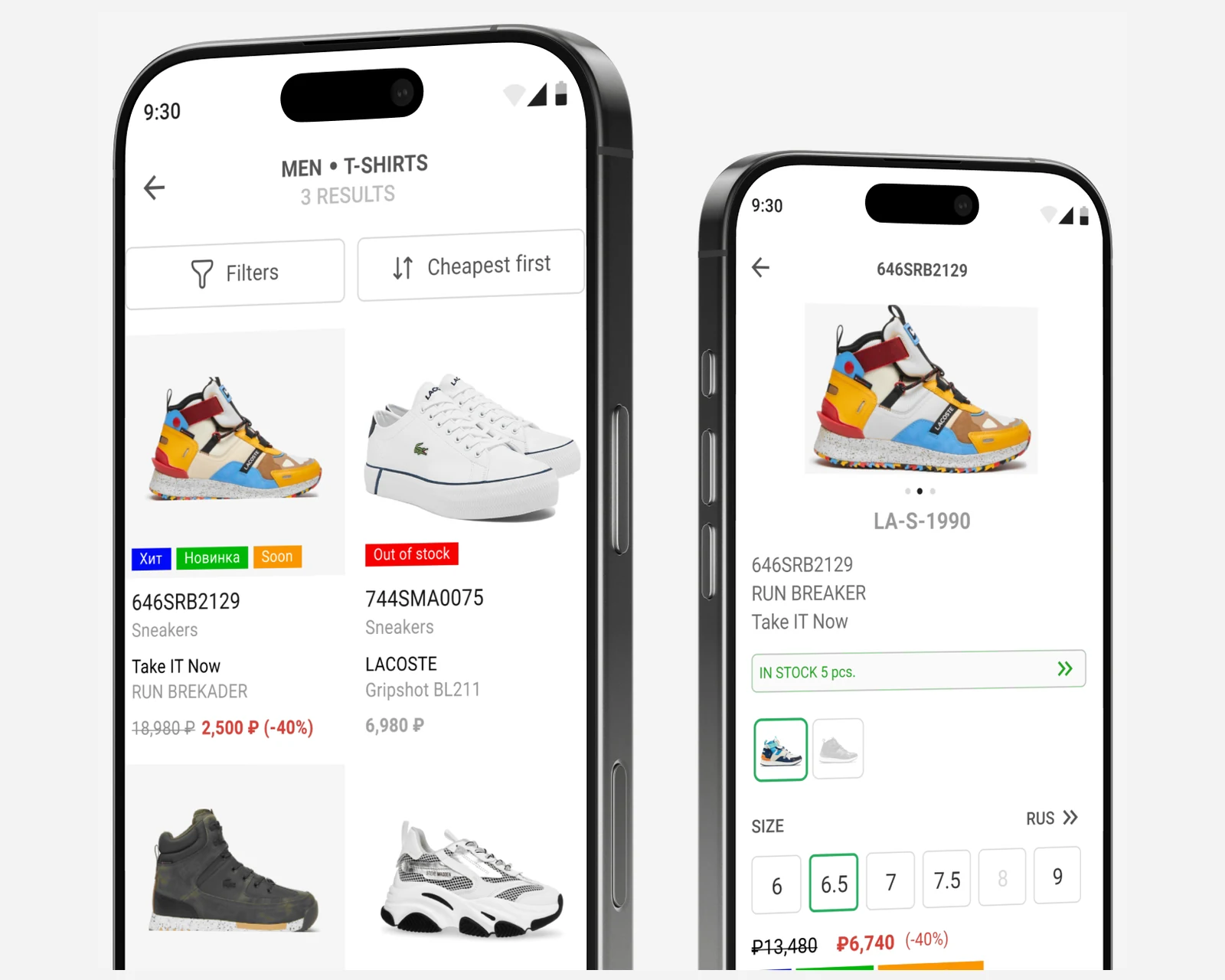
Retail POS companion app for a multi-brand boutique chain — ElasticSearch cross-store inventory search, 1C-system integration.
Why YuSMP
We treat bytes scanned as a budget. Every warehouse ships with partition pruning, slot or edition sizing and dashboards so finance sees predictable, explainable spend.
Senior engineers who design physical layouts, ELT and streaming end to end — not just SQL authors — so the warehouse scales as your data grows.
GDPR residency, HIPAA BAA scope and SOC 2 controls are designed in from the first dataset, not retrofitted under audit pressure.
FAQ
BigQuery is fully serverless with no clusters to size or pause — storage and compute scale independently and you pay by bytes scanned or by reserved slots. Snowflake offers similar separation but with explicit virtual warehouses you start and stop, while Redshift leans toward provisioned (or serverless) clusters tied tightly to AWS. We help teams pick based on cloud footprint, query patterns and cost model rather than hype.
On-demand billing charges per terabyte scanned, so cost is driven by how much data each query reads, not how long it runs. Editions and slot reservations switch you to predictable, capacity-based pricing. We control spend with partition and cluster pruning, byte-limit guardrails, materialised views, custom quotas and cost dashboards so there are no surprise bills.
Partitioning physically splits a table by a column — usually a date or ingestion time — so queries with a filter on that column scan only relevant partitions. Clustering sorts data within partitions by up to four columns, further reducing scanned bytes for filtered or aggregated queries. They are complementary: partition first for coarse pruning, then cluster on the fields you filter or group by most.
Batch loads are free, ideal for scheduled ELT and large volumes, and give exactly-once semantics. Streaming inserts (or the Storage Write API) deliver rows in seconds for real-time dashboards but cost more and need dedup handling. We typically recommend batch for analytics and streaming only where genuine sub-minute latency creates business value.
BigQuery ML lets you train and run models — linear and logistic regression, time-series forecasting, clustering, boosted trees and more — directly in SQL, with data never leaving the warehouse. It is excellent for forecasting, churn and segmentation when you want fast results without standing up separate ML infrastructure. For deep learning or low-latency serving we integrate Vertex AI instead.
Yes. You pin a dataset to an EU multi-region or specific region at creation to keep data in-jurisdiction, and the region cannot be changed afterwards, so we design it correctly up front. BigQuery is a covered service under a Google Cloud BAA, so with the right IAM, encryption and logging it supports HIPAA workloads alongside GDPR residency requirements.
BigQuery is built for analytical, append-heavy workloads, not transactional ones — it is a poor fit for high-frequency single-row reads, updates and deletes that an OLTP database like Postgres or Cloud SQL handles better. For very small datasets the serverless overhead and per-query model rarely beat a simple managed database. We will tell you when a warehouse is overkill.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.