Slow queries at 100M+ rows
Table scans on large tables blow query time budgets. We run EXPLAIN (ANALYZE, BUFFERS), add targeted partial and expression indexes, and implement declarative partitioning to prune scan scope.
Postgres 17 pgvector GDPR-ready PITR
Forty-two of our production systems run on PostgreSQL — Loan Conveyor's lending decision engine processing thousands of credit decisions per day, ANT's PropTech marketplace with full-text search and geospatial queries, ArgoView's clinical workstation with DICOM metadata and pgvector embeddings. Schema design, query tuning, partitioning, logical replication and HA — all in our portfolio.

We deliver PostgreSQL engineering for SaaS platforms needing schema design, query optimisation and HA setup from the start; fintech and healthtech systems requiring audit-trail schemas, row-level security and GDPR-compliant erasure; AI teams adding pgvector for RAG and semantic search without introducing new infrastructure; and regulated industries where PITR backups, data residency and encryption at rest are delivery requirements.
Challenges
Table scans on large tables blow query time budgets. We run EXPLAIN (ANALYZE, BUFFERS), add targeted partial and expression indexes, and implement declarative partitioning to prune scan scope.
High-update workloads accumulate dead tuples faster than autovacuum clears them. We tune autovacuum thresholds per table and schedule explicit VACUUM ANALYZE on hot tables during low-traffic windows.
Missing or misconfigured RLS policies leak rows between tenants at the database layer. We enforce RLS on every table, write cross-tenant isolation tests and add canary rows that alert if they appear in the wrong tenant query.
Choosing between HNSW and IVFFlat for pgvector depends on recall requirements, update frequency and query latency SLA. We benchmark both on your data shape before committing to an index type.
High write volume causes replication slots to accumulate WAL, growing disk to dangerous levels. We monitor slot lag, set wal_keep_size guards and implement slot failover for zero-data-loss cutover.
Anonymising PII in an existing schema with no soft-delete design requires careful migration planning. We design erasure into new schemas and provide migration playbooks for existing ones.
Solutions
Domain-driven schema design with clear aggregate boundaries, audit tables, soft-delete, and RLS policies built in from the first migration.
Query plan analysis, index recommendation, connection pool sizing and autovacuum tuning — delivered as a prioritised remediation report.
Declarative range, list and hash partitioning with pg_partman automation for time-series and multi-tenant tables.
HNSW and IVFFlat index setup for semantic search and RAG retrieval — benchmarked against your corpus before production deployment.
Patroni or RDS Multi-AZ with pgBouncer, WAL-G continuous archiving and tested point-in-time recovery procedures.
Zero-downtime major-version upgrades and cross-cloud migrations using logical replication with sub-60-second cutover windows.
Stack
PostgreSQL 17, pgvector, pg_partman, pg_stat_statements, pgBouncer, Patroni, WAL-G, TimescaleDB, PostGIS, logical replication, RDS, Aurora, EXPLAIN (ANALYZE).
Compliance
GDPR-aligned · HIPAA-eligible · SOC 2-capable · PCI DSS-aware
Shared: TLS in transit, pgcrypto for column encryption, SBOM for extensions.
Cases
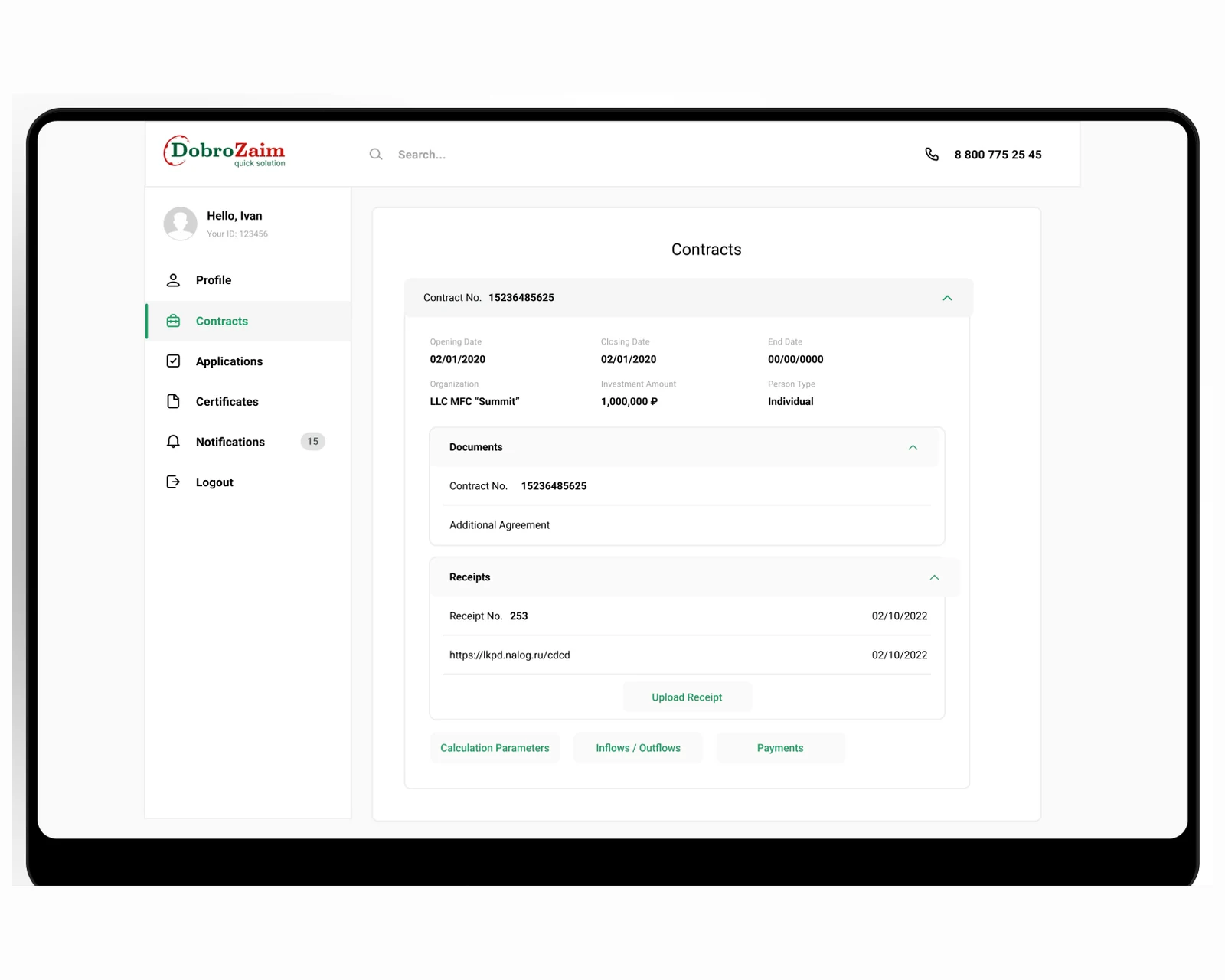
A high-throughput loan decision engine on Laravel — automated scoring, credit-bureau integration, and 10x faster decisions for US & EU lenders.
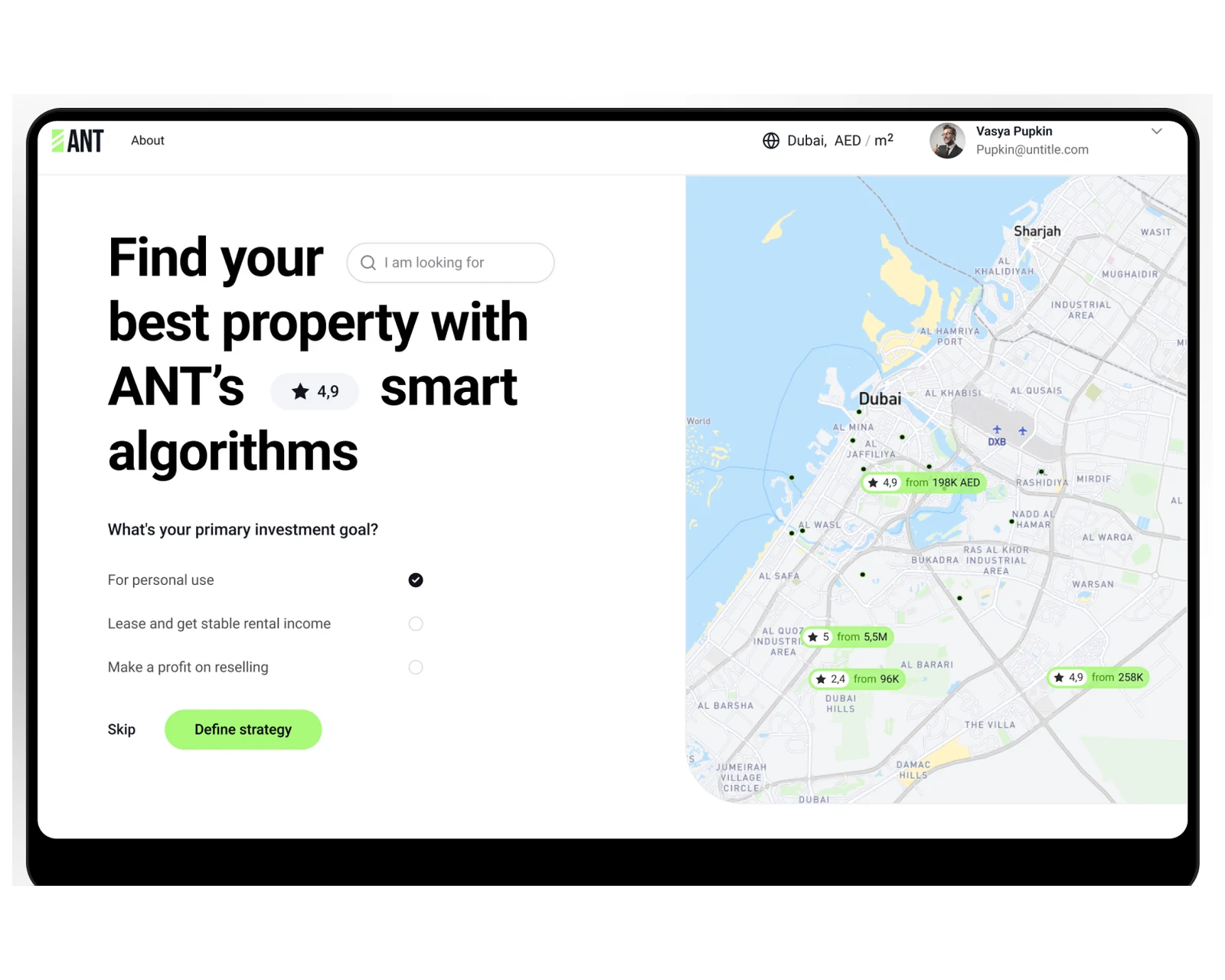
Property marketplace web platform with listing CMS, search and B2B admin console for US and EU operators.
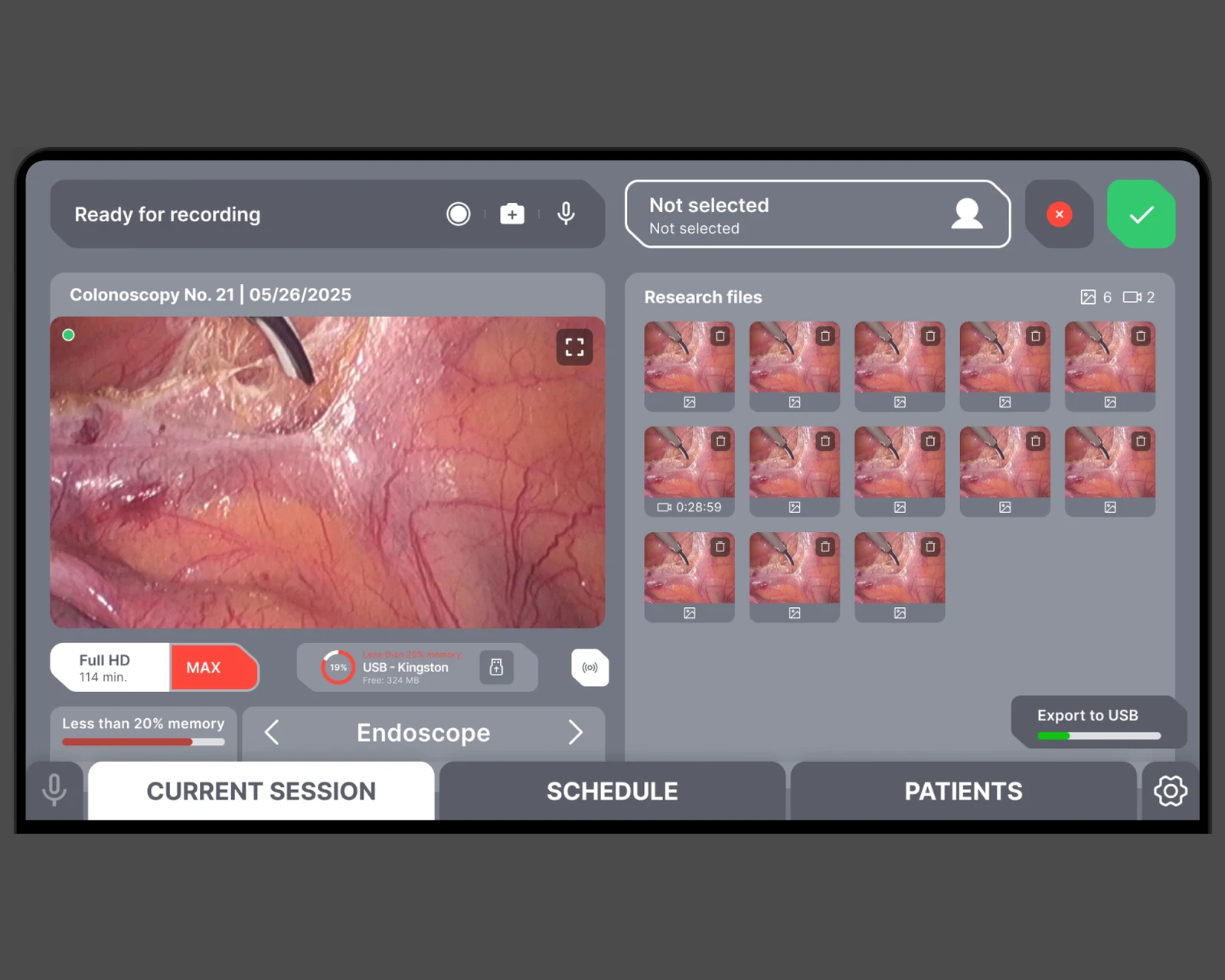
Tablet-first endoscopy recording, patient records, and DICOM/HL7 export — built on Laravel + React with browser-tier WebRTC capture for US & EU clinics.
Why YuSMP
More production PostgreSQL experience than any other database in our portfolio — across fintech decision engines, healthtech clinical systems and high-traffic marketplaces.
We add semantic search and RAG retrieval to your PostgreSQL without introducing new infrastructure — HNSW indexes, SQL joins, ACID consistency.
Right-to-erasure, anonymisation playbooks and PITR backup testing — designed into the schema, not retrofitted at audit time.
FAQ
Declarative partitioning (range or list) to prune scan scope, targeted indexing with partial and expression indexes, autovacuum tuning to prevent table bloat, and query plan analysis with EXPLAIN (ANALYZE, BUFFERS). We also evaluate pg_partman for automated partition management and TimescaleDB for time-series workloads.
PostgreSQL Row-Level Security policies with a current_setting('app.tenant_id') context variable — enforced at the database layer, not just the application layer. Every SELECT, INSERT, UPDATE and DELETE is filtered through RLS. We write cross-tenant canary tests to verify isolation.
pgvector on your existing PostgreSQL for teams that want transactional consistency between vector search and relational data — no new infrastructure, SQL joins, ACID guarantees. Dedicated Qdrant or Weaviate for workloads requiring filtered vector search at scale (100M+ vectors) or multi-modal indexing. We have production experience with both.
Patroni on-premises or on cloud VMs for auto-failover with etcd quorum. RDS Multi-AZ or Aurora PostgreSQL on managed cloud. We add pgBouncer connection pooling in transaction mode in front of any HA setup and test failover with real application traffic in staging.
WAL-G for continuous WAL archiving to S3 or GCS, enabling point-in-time recovery to any second within the retention window. pg_dump for logical backups of individual databases. We test recovery to a staging environment weekly and document the RTO in your DR runbook.
We set up logical replication from the source to the target, let the replica catch up, run a brief application-level read-only window to drain in-flight writes, switch the connection string, and tear down replication. Typical cutover window: under 60 seconds for most application stacks.
We implement soft-delete with a deleted_at timestamp and a GDPR erasure job that replaces PII columns with a SHA-256 hash of the subject ID. For irreversible anonymisation we use PostgreSQL's UPDATE ... RETURNING and a deletion audit log. The approach must be designed into the schema — retrofitting it on an existing schema requires a planned migration.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.