Sort-key & primary-key design
A wrong ORDER BY in MergeTree quietly wrecks performance — full scans where you expected granule skips. We model sort keys around your real query predicates so the sparse index does the work.
ClickHouse OLAP Columnar Real-Time Analytics
We design and run ClickHouse platforms for analytics-heavy products across the US and EU — from sub-second dashboards over billions of rows to event pipelines that ingest millions of records per second. Our engineers tune MergeTree schemas, materialised views and sharding topologies so your queries stay fast and your cloud bill stays sane. Whether you are migrating off a costly warehouse or building real-time analytics from scratch, we deliver production-grade columnar OLAP.

We design and run ClickHouse platforms for analytics-heavy products across the US and EU — from sub-second dashboards over billions of rows to event pipelines that ingest millions of records per second. Our engineers tune MergeTree schemas, materialised views and sharding topologies so your queries stay fast and your cloud bill stays sane. Whether you are migrating off a costly warehouse or building real-time analytics from scratch, we deliver production-grade columnar OLAP.
Challenges
A wrong ORDER BY in MergeTree quietly wrecks performance — full scans where you expected granule skips. We model sort keys around your real query predicates so the sparse index does the work.
Naive single-row inserts hammer ClickHouse and spawn too many parts. We design Kafka-engine consumers and batched inserts so millions of events per second land without merge storms.
ClickHouse is not a relational engine — large distributed JOINs blow up memory. We denormalise deliberately, using dictionaries and wide tables to keep hot queries single-table and fast.
UPDATE and DELETE are heavyweight async mutations, not OLTP operations. We model with ReplacingMergeTree, collapsing engines and versioning so corrections never rewrite whole partitions.
Get the cluster layout wrong and you inherit hot shards and rebalancing pain. We size shards, replicas and distributed tables around data volume, cardinality and failure domains.
Append-only columnar storage fights right-to-erasure. We engineer TTL policies, partition-level purges and key-based deletes so personal data can actually be removed on request.
Solutions
Event-to-dashboard pipelines with sub-second latency — ingestion, rollups and serving layers designed to keep queries fast as volume grows into the billions.
We redesign sort keys, partitioning, codecs and data types, then benchmark against your real workload to cut scan time and storage footprint.
Pre-aggregated materialised views and AggregatingMergeTree rollups that turn expensive ad-hoc scans into instant reads for recurring dashboards and APIs.
Robust Kafka table-engine consumers with batching, dead-letter handling and exactly-once-style dedup so streaming data lands reliably and cheaply.
Operational and product analytics in Grafana — tuned ClickHouse queries, sensible caching and alerting wired to the metrics that matter.
We migrate analytics off Postgres or Elasticsearch and trim runaway Snowflake/BigQuery bills by moving the hot path to a right-sized ClickHouse cluster.
Stack
ClickHouse, MergeTree engines, materialised views, Kafka table engine, ClickHouse Cloud, dbt-clickhouse, Grafana, Docker, and sharding/replication.
Compliance
GDPR · data residency · HIPAA-ready analytics · SOC 2
Cases

Cross-platform sports news app and web portal — Telegram-bot CMS instead of a custom admin, Markdown publishing pipeline.

Production social platform — App Store + Google Play, live across the US and EU — with geo Radar, encrypted messaging and a virtual economy.
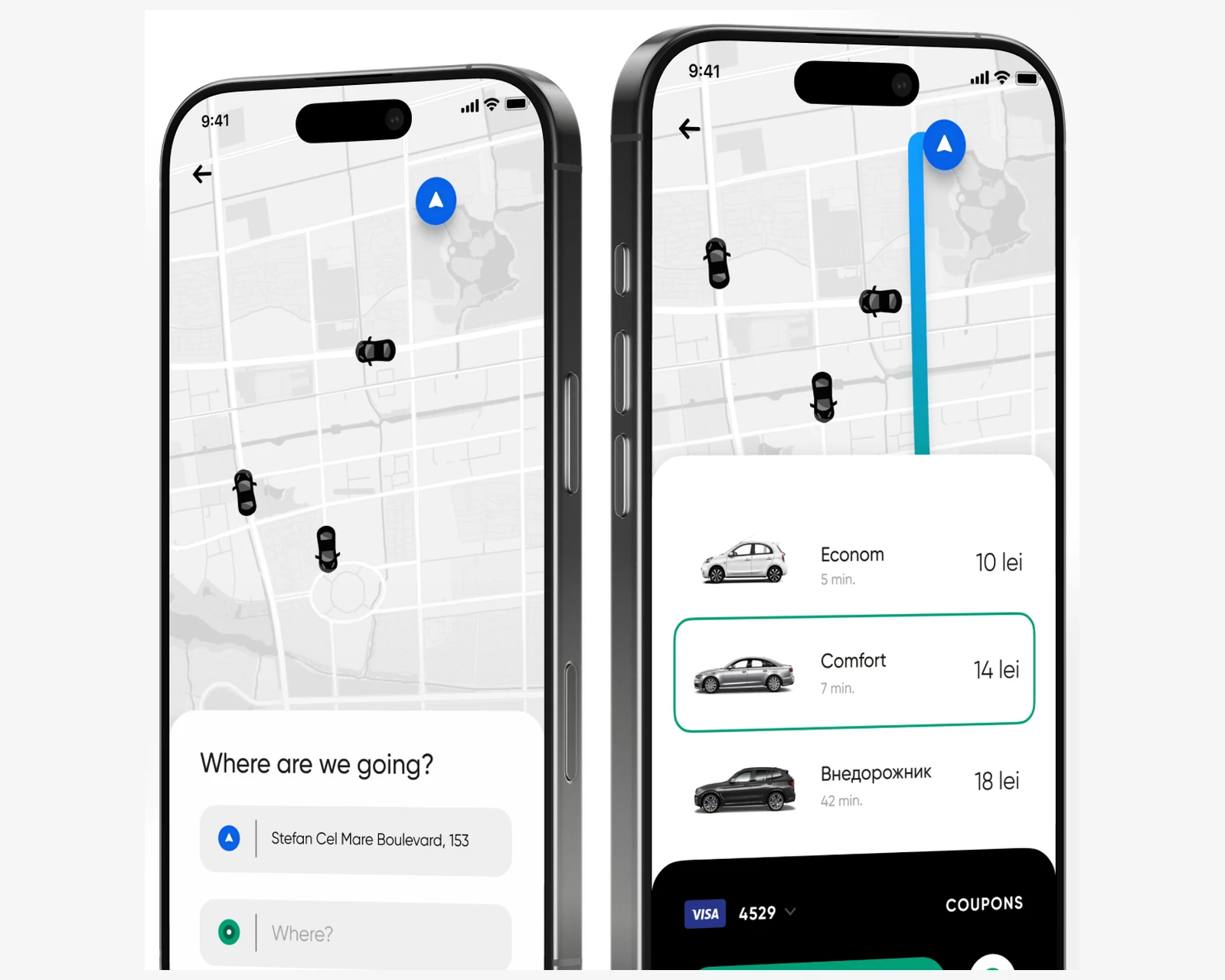
Three-app ride-hailing platform — driver, passenger, dispatcher — with real-time GPS, document verification, dual cash/card payments.
Why YuSMP
Our schemas and indexes are tuned for sub-second aggregates across billions of rows — we benchmark on your data, not synthetic demos.
Columnar storage, codecs and right-sized clusters routinely cut analytics infrastructure spend by half versus general-purpose warehouses.
From Kafka ingestion to materialised views, we build pipelines that surface fresh data in seconds, not hourly batch windows.
FAQ
PostgreSQL is a row-store built for transactions; ClickHouse is a columnar OLAP engine built for fast aggregates over huge datasets. Versus Snowflake and BigQuery, ClickHouse can be dramatically cheaper and lower-latency for high-volume, high-frequency analytics, especially when self-hosted. The trade-off is that you manage schema design and operations more deliberately, which is exactly where we help.
ClickHouse shines when you run analytical queries — aggregations, filters and time-series scans — over large, mostly append-only datasets. It is ideal for product analytics, observability, ad-tech and clickstream workloads. If your app needs frequent single-row updates and transactional consistency, a row-store like PostgreSQL remains the better primary database.
Yes — with the right design. We use the Kafka table engine or batched bulk inserts to land millions of events per second while avoiding the small-parts problem that plagues naive row-by-row writes. Combined with materialised views, fresh data becomes queryable within seconds of arrival.
ClickHouse treats UPDATE and DELETE as asynchronous mutations rather than cheap OLTP operations, so we model corrections with ReplacingMergeTree, collapsing engines or versioning. For GDPR and CCPA erasure we combine TTL policies, partition-level purges and lightweight key-based deletes so personal data can be removed on request without rewriting entire tables.
ClickHouse supports JOINs but is not optimised for large distributed relational joins, which can exhaust memory. We design wide, denormalised tables and use dictionaries for lookups so the hottest queries stay single-table and fast, reserving JOINs for smaller dimension data.
ClickHouse Cloud removes operational overhead and scales storage and compute independently, which suits lean teams and bursty workloads. Self-hosting gives maximum cost control and data-residency certainty for regulated US and EU environments. We help you weigh both and run whichever you choose, including hybrid setups.
A single well-tuned node handles surprising volume, so we scale vertically first. When data or query load outgrows one machine, we add replication for availability and sharding to distribute data and parallelise queries via distributed tables. We size the topology around your cardinality, growth curve and failure-domain requirements.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.