Delivery guarantees
Naive consumers either drop messages on crash or double-process them. Getting at-least-once delivery right means deliberate acknowledgements, publisher confirms and idempotent handlers — not just turning on auto-ack.
RabbitMQ AMQP Message Queues Event-Driven
We design and operate RabbitMQ message brokers for software teams across the US and EU that need to decouple services and absorb load spikes without losing messages. From AMQP exchange topology to dead-letter strategies and quorum-queue clustering, we build async pipelines that survive node failures and traffic surges. Our engineers ship production-grade brokers with the observability and delivery guarantees regulated industries demand.

We design and operate RabbitMQ message brokers for software teams across the US and EU that need to decouple services and absorb load spikes without losing messages. From AMQP exchange topology to dead-letter strategies and quorum-queue clustering, we build async pipelines that survive node failures and traffic surges. Our engineers ship production-grade brokers with the observability and delivery guarantees regulated industries demand.
Challenges
Naive consumers either drop messages on crash or double-process them. Getting at-least-once delivery right means deliberate acknowledgements, publisher confirms and idempotent handlers — not just turning on auto-ack.
A single malformed or repeatedly failing message can wedge a queue, blocking everything behind it. Without dead-letter routing and retry caps, one bad payload stalls an entire pipeline.
When producers outrun consumers, memory and disk fill until RabbitMQ throttles or blocks publishers. Teams discover flow control the hard way during their first traffic spike.
Classic mirrored queues split-brain and lose data under network partitions. Moving to quorum queues with correct partition handling is essential but easy to misconfigure.
RabbitMQ preserves order only per queue and only without competing consumers or redelivery. Scaling consumers naively quietly breaks the ordering assumptions downstream code relies on.
Most outages start as a slowly growing queue no one is watching. Without depth, consumer-lag and unacked-message metrics wired into alerting, problems surface only when users complain.
Solutions
We model your domain events and design the exchange, routing-key and queue topology — choosing direct, topic, fanout or headers exchanges to fit each integration pattern cleanly.
We implement publisher confirms, manual acknowledgements, dead-letter queues, bounded retries with backoff and idempotent consumers so messages are processed exactly the way you intend.
We deploy multi-node clusters on quorum queues with correct partition-handling, sized for your throughput and tested against node loss and network splits.
We build consumers with Spring AMQP, pika or amqplib — tuned prefetch, concurrency and ordering controls — turning queues into predictable, scalable worker pipelines.
We wire RabbitMQ and Prometheus metrics into dashboards and alerts on queue depth, consumer lag, unacked counts and memory pressure so you act before a backlog becomes an outage.
We migrate synchronous request chains to async messaging and give you a clear, evidence-based RabbitMQ vs Kafka decision instead of defaulting to whichever broker is fashionable.
Stack
RabbitMQ, AMQP 0-9-1, exchanges and queues, dead-letter queues, quorum queues, Spring AMQP / amqplib / pika, Docker, Kubernetes operator, Prometheus.
Compliance
GDPR · HIPAA-ready · TLS/mTLS · SOC 2 audit
Cases
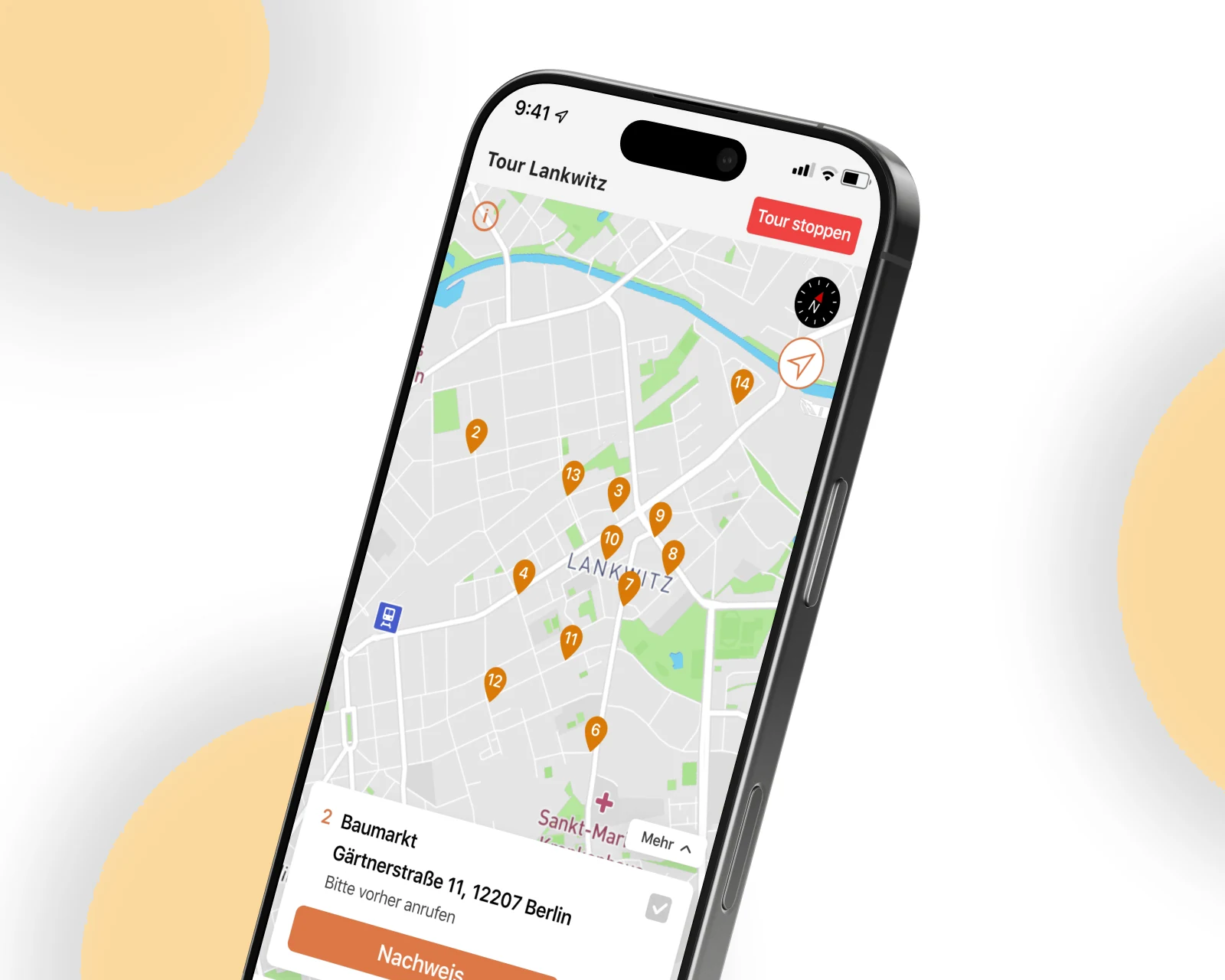
Android + iOS refactor and rebuild for a German last-mile logistics operator — multi-point route planning, real-time driver tracking and in-app invoicing live in the EU.
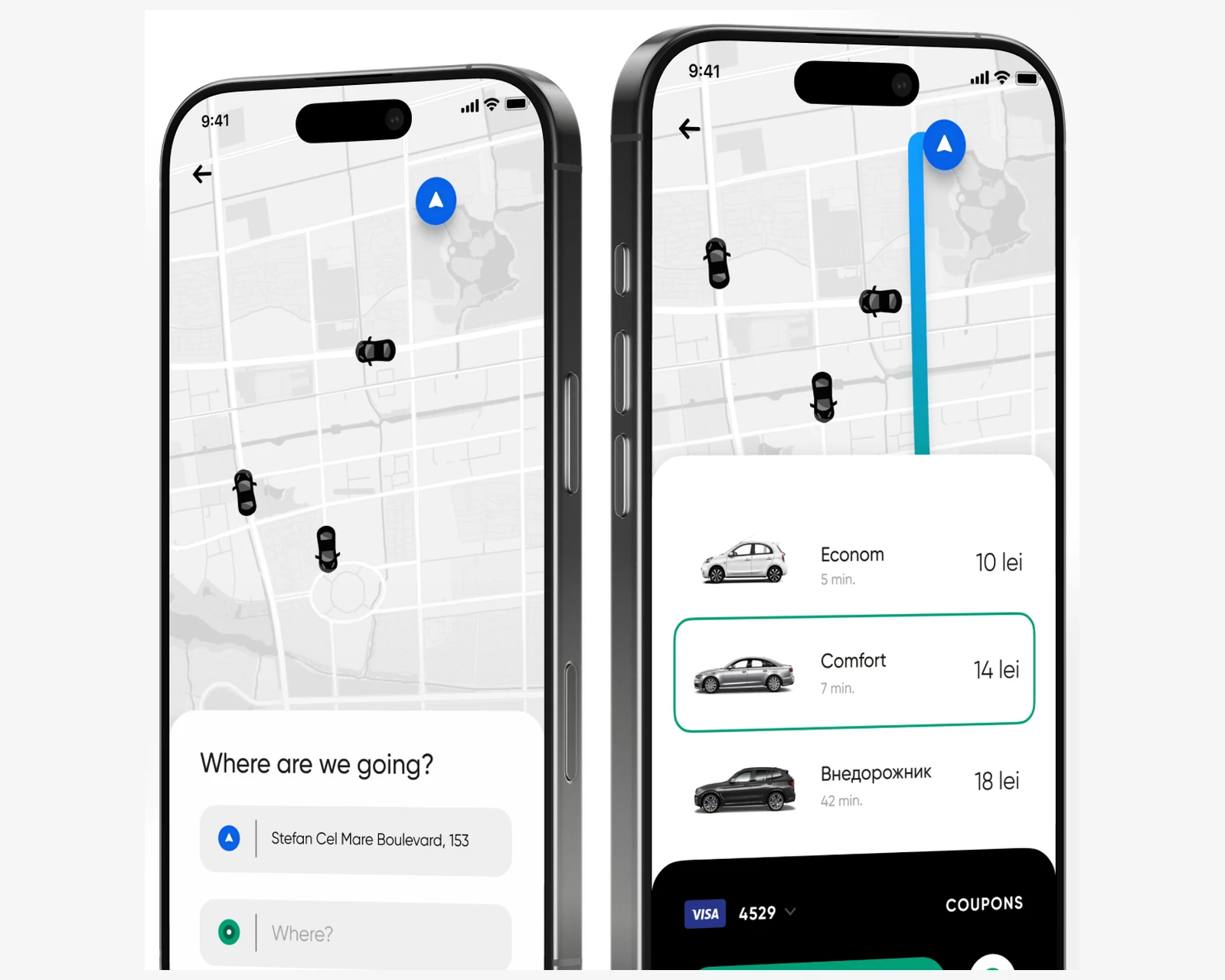
Three-app ride-hailing platform — driver, passenger, dispatcher — with real-time GPS, document verification, dual cash/card payments.
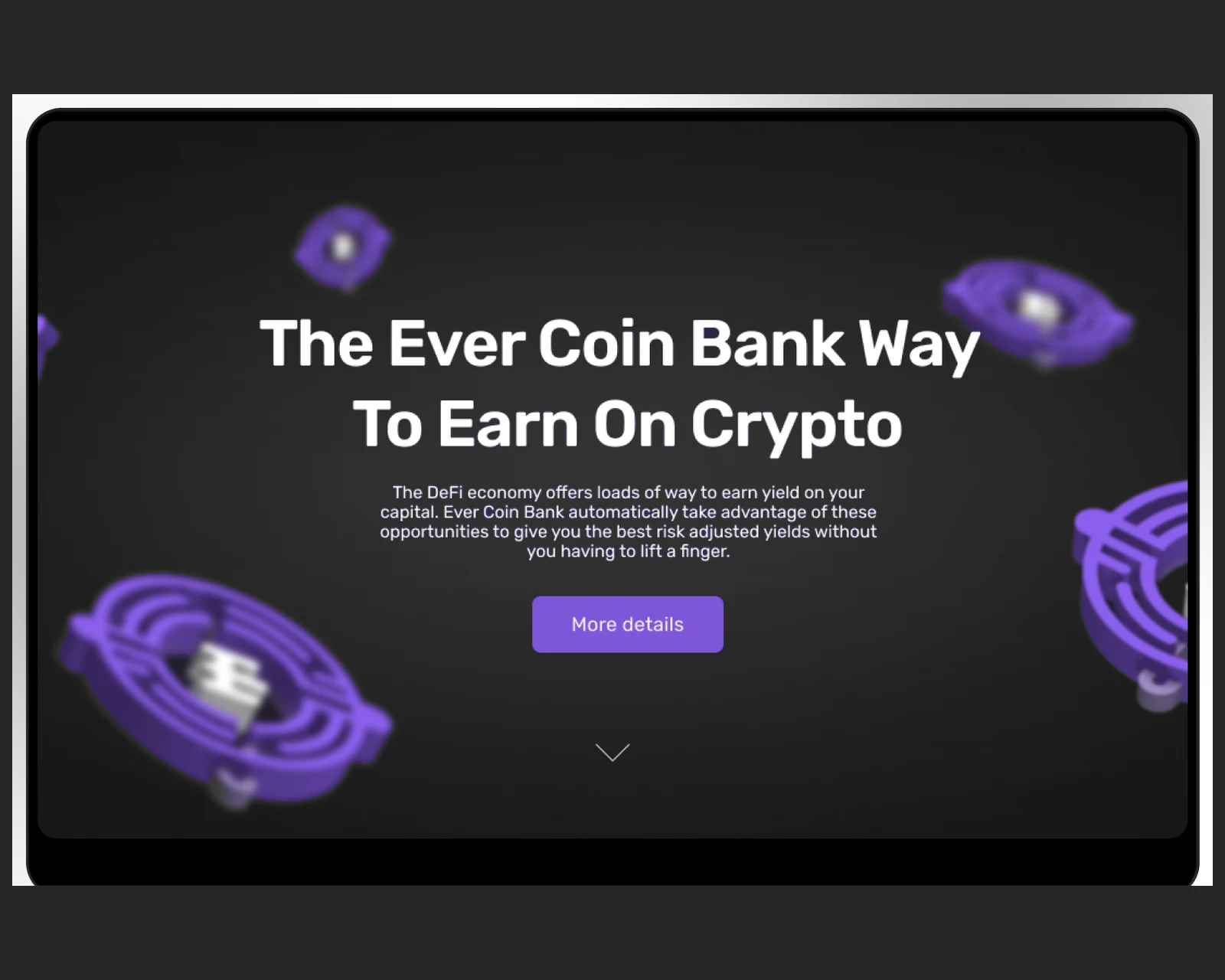
Unified crypto-ecosystem hub aggregating multiple tokens — live exchange data, search, charts, direct purchase entry point.
Why YuSMP
We have run RabbitMQ under real load — partitions, poison messages, backpressure and 3am pages — and we design for those failure modes from day one rather than after the first incident.
We work across US and EU time zones with the compliance posture each region expects, from HIPAA and SOC 2 to GDPR and NIS2, baked into the messaging layer.
We will tell you when RabbitMQ is the right tool and when Kafka, SQS or a simple database queue serves you better — the recommendation follows your workload, not our preference.
FAQ
Choose RabbitMQ when you need flexible routing, per-message acknowledgement, priorities, delayed delivery and complex consumer logic — classic task queues and RPC-style workloads. Choose Kafka for high-throughput event streaming, log replay and many consumers reading the same ordered stream. Many systems use both; we help you draw the line rather than force one tool to do everything.
RabbitMQ supports at-most-once and at-least-once delivery; exactly-once is achieved at the application level through idempotency. We combine publisher confirms, persistent messages, durable queues and manual consumer acknowledgements so messages survive broker restarts and consumer crashes. Idempotent handlers then make safe redelivery a non-event for your business logic.
We route messages that exceed a retry threshold to a dead-letter exchange and queue, so a single bad payload never blocks the main queue. From there failed messages can be inspected, replayed after a fix, or alerted on. We pair this with bounded exponential backoff and TTL-based retry queues so transient failures self-heal without manual intervention.
We deploy multi-node clusters using quorum queues, which use a Raft-based consensus that handles network partitions safely — unlike the legacy mirrored queues prone to split-brain. We configure the right partition-handling mode, place nodes across availability zones where possible, and load-test failover so the cluster behaves predictably when a node goes down.
RabbitMQ preserves publish order within a single queue, but ordering breaks once you add competing consumers, redelivery after a nack, or priorities. When strict ordering matters we use single active consumer mode, consistent-hash routing to partition by key, or per-entity queues. We design the topology around your actual ordering requirements rather than assuming order is free.
Direct exchanges route on an exact routing-key match (point-to-point work distribution); topic exchanges route on wildcard patterns (flexible pub/sub by category); fanout exchanges broadcast to every bound queue (event notifications); and headers exchanges route on message attributes. We pick per integration, often combining several, so each event reaches exactly the consumers that need it.
We scale consumers horizontally with tuned prefetch counts to balance load, shard high-volume queues by routing key, and right-size persistence and acknowledgement settings for the durability you actually need. Where a single broker becomes the ceiling we partition queues across the cluster or introduce sharding. We back every change with load tests so scaling decisions rest on measured numbers, not guesses.
Response within 1 business day. NDA on request.
Share a few details and a senior consultant will reply within one business day.